BELLE
v0.95 发布
 Belle : 모든 사람의 대형 언어 모델 엔진이 되십시오
Belle : 모든 사람의 대형 언어 모델 엔진이 되십시오이것을 영어로 읽으십시오.
이 프로젝트의 목표는 중국 대화 대형 모델 오픈 소스 커뮤니티의 개발을 촉진하는 것입니다. 비전은 모든 사람을 도울 수있는 LLM 엔진이되는 것입니다.
대형 언어 모델을 사전 훈련하는 방법과 비교할 때 Belle은 모든 사람이 자신의 언어 모델을 얻는 데 도움이되는 방법에 더 중점을 둡니다. 오픈 소스 사전 훈련 대형 언어 모델을 기반으로 가능한 최상의 효과 및 교육 성능 기능을 통해 대형 언어 모델, 특히 중국어의 대형 언어 모델의 연구 및 응용 프로그램 임계 값을 줄입니다. 이를 위해 Belle Project는 계속해서 교육 교육 데이터, 관련 모델, 교육 코드, 응용 프로그램 시나리오 등을 계속 열고 모델 성능에 대한 다양한 교육 데이터, 교육 알고리즘 등의 영향을 계속 평가할 것입니다. Belle은 중국어에 최적화되었으며 모델 튜닝은 ChatGpt에서 생성 된 데이터 만 사용합니다 (다른 데이터없이).
다음 그림은 앱을 사용하여 장치 쪽에서 로컬로 40을 정량화 할 수있는 Belle-7B 모델이며 M1 Max CPU에서 실시간으로 실행됩니다 (가속되지 않음). 앱 다운로드에 대한 자세한 내용은 앱 지원 모델 다운로드 및 사용 지침을 참조하십시오. 앱 다운로드 링크는 현재 Mac OS 버전에서만 사용할 수 있습니다. 모델은 별도로 다운로드해야합니다. 모델이 정량화 된 후에는 효과 손실이 분명하며, 우리는 그것을 개선하는 방법을 계속 연구 할 것입니다.
자세한 내용은 Belle/Train을 참조하십시오. 가능한 한 단순화되고 DeepSpeed-Chat을 통합하며 Finetune 및 LORA를 지원하며 관련 Dockers를 제공합니다.
자세한 내용은 Belle/Data/1.5m을 참조하십시오. Stanford Alpaca 1m + 0.5m에서 생성 한 중국 데이터 세트를 참조하십시오.
지속적으로 열린 데이터 세트는 자세한 내용은 Belle/Data/10M을 참조하십시오.
자세한 내용은 Belle/Eval, 1K+ 테스트 세트 및 해당 스코어링 프롬프트를 참조하십시오. 여러 범주가 포함되어 있으며 GPT-4 또는 ChatGpt를 사용하여 점수를 매 깁니다. 또한 단일 케이스에 쉽게 사용할 수있는 점수 웹 페이지를 제공합니다. 모두 PR을 통해 더 많은 테스트 사례를 제공 할 수 있습니다.
자세한 내용은 Belle/Models를 참조하십시오
메타 llama2를 기반으로 한 튜닝 모델 : Belle-llama2-13B-Chat-0.4m
메타 라마 : Belle-llama-7b-0.6m-enc, Belle-llama-7b-2m-enc, Belle-llama-7b-2M-GPTQ-ENC, Belle-Llama-13B-2M-Enc, Belle-on-Open-Datasets 및 Belle-on-Open-EX-7B를 기반으로 한 LLAMA를 기반으로 한 튜닝을 구현하는 모델. 어휘.
Bloomz-7B1-MT : Belle-7B-0.2M, Belle-7B-0.6M, Belle-7B-1M, Belle-7B-2M을 기반으로 최적화 된 모델
자세한 내용은 Belle/GPTQ를 참조하십시오. 이 프로젝트의 관련 모델을 정량화하려면 GPTQ 구현을 참조하십시오.
Colab에서 실행 가능한 추론 코드 Colab을 제공합니다
자세한 내용은 Belle 모델을 기반으로 한 크로스 플랫폼 오프라인 대형 언어 모델 채팅 앱인 Belle/Chat을 참조하십시오. Flut
자세한 내용은 Belle/Docs를 참조하십시오.이 프로젝트와 관련된 연구 보고서를 정기적으로 업데이트합니다.
문제를 통해 더 많은 제안을 제공하는 데 오신 것을 환영합니다!
오픈 소스 대형 언어 모델의 개발을 촉진하기 위해 Chatgpt와 유사 할 수있는 저비용 모델을 개발하기 위해 많은 에너지를 투자했습니다. 먼저, 중국 분야에서 모델의 성능 및 훈련/추론 효율성을 향상시키기 위해 LLAMA의 어휘를 더욱 확장하고 34 억 중국어 어휘에 2 차 사전 훈련을 수행했습니다.
또한 ChatGPT에 기초하여 생성 된 훈련 된 데이터는 다음과 같은임을 알 수 있습니다. 1) Alpaca에 의해 GPT3.5를 기반으로 얻은 자체 강조 데이터를 참조하십시오. 2) Alpaca에 의한 GPT4에 기초하여 얻은 자체 강조 데이터를 참조하고; 3) chatgpt를 사용하는 사용자가 공유하는 sharegpt 데이터. 여기서는 교육 데이터 범주가 모델 성능에 미치는 영향을 탐색하는 데 중점을 둡니다. 구체적으로, 우리는 훈련 데이터의 수량, 품질 및 언어 분포와 같은 요소뿐만 아니라 우리가 수집 한 중국의 다중 라운드 대화 데이터와 공개적으로 액세스 할 수있는 고품질 지침 데이터 세트를 조사합니다.
그 효과를 더 잘 평가하기 위해, 우리는 1,000 개의 샘플과 9 가지 실제 시나리오의 평가 세트를 사용하여 다양한 모델을 테스트하는 한편, 정량 분석을 통해 귀중한 통찰력을 제공하여 오픈 소스 채팅 모델의 개발을 더 잘 촉진했습니다.
이 연구의 목표는이 분야에서 지속적인 진전을 강력하게 지원하기 위해 오픈 소스 채팅 모델의 포괄적 인 평가의 격차를 메우는 것입니다.
실험 결과는 다음과 같습니다.
| 요인 | 기본 모델 | 교육 데이터 | score_w/o_others |
| 어휘 확장 | llama-7b-ext | ZH (Alpaca-3.5 & 4) + sharegpt | 0.670 |
| llama-7b | ZH (Alpaca-3.5 & 4) + sharegpt | 0.652 | |
| 데이터 품질 | llama-7b-ext | ZH (알파카 -3.5) | 0.642 |
| llama-7b-ext | ZH (Alpaca-4) | 0.693 | |
| 데이터 언어 분포 | llama-7b-ext | ZH (Alpaca-3.5 & 4) | 0.679 |
| llama-7b-ext | ko (Alpaca-3.5 & 4) | 0.659 | |
| llama-7b-ext | ZH (Alpaca-3.5 & 4) + sharegpt | 0.670 | |
| llama-7b-ext | en (alpaca-3.5 & 4) + sharegpt | 0.668 | |
| 데이터 규모 | llama-7b-ext | ZH (Alpaca-3.5 & 4) + sharegpt | 0.670 |
| llama-7b-ext | ZH (Alpaca-3.5 & 4) + sharegpt + Belle-0.5m-clean | 0.762 | |
| - | chatgpt | - | 0.824 |
그 중에서 Belle-0.5m-Clean은 230 만 명령 데이터에서 0.5m 데이터를 정리합니다. 여기에는 단일 라운드 및 다중 라운드 대화 데이터가 포함되어 있으며, 이전에는 0.5m 데이터와 동일한 데이터 배치가 아닙니다.
사례 분석을 통해 평가 세트는 포괄적 인 측면에서 한계가있어 모델 점수 개선과 실제 사용자 경험 사이의 불일치로 이어졌다는 것을 강조해야합니다 . 고품질 평가 세트를 구축하는 것은 균형 잡힌 난이도를 유지하면서 가능한 많은 사용 시나리오가 필요하기 때문에 큰 어려움입니다. 샘플을 평가하는 것이 대부분 너무 어려워지면 모든 모델이 성능이 저하되어 다양한 교육 전략의 영향을 식별하기가 어려워집니다. 반대로, 모든 샘플이 평가되는 경우 비교적 쉽습니다. 평가는 비교 값을 잃게됩니다. 또한 평가 데이터가 교육 데이터와 독립적으로 유지되도록해야합니다.
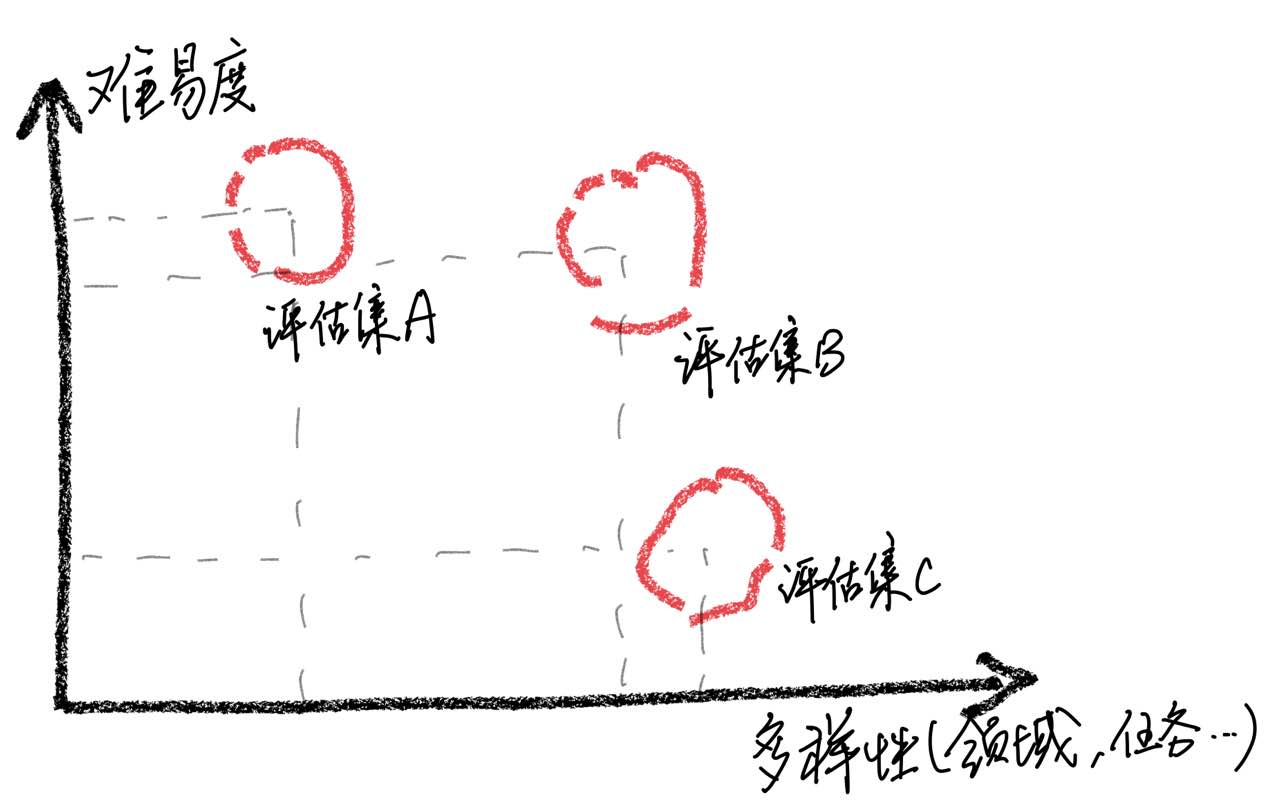
이러한 관찰에 기초하여, 우리는 제한된 수의 테스트 샘플에서 좋은 결과를 얻음으로써 모델이 ChatGpt와 비슷한 성능 수준을 달성했다고 가정하지 않도록주의합니다. 우리는 포괄적 인 평가 세트의 개발 우선 순위를 정하는 것이 매우 중요하다고 생각합니다.
자원과 비용으로 인해 대형 언어 모델의 교육 튜닝을 달성하기 위해 많은 연구자들이 LORA와 같은 매개 변수 효율적인 튜닝 기술을 사용하여 교육 튜닝을 수행하기 시작했으며, 이는 몇 가지 고무적인 결과를 얻었습니다. 전체 가변계 미세 조정과 비교할 때 LORA 기반 튜닝은 교육 비용의 명백한 이점을 보여줍니다. 이 연구 보고서에서 우리는 LLAMA를 기본 모델로 사용하여 전체 매개 변수 미세 조정 및 LORA 기반 튜닝 방법을 실험적으로 비교했습니다.
실험 결과는 적절한 기본 모델의 선택, 교육 데이터 세트의 규모, 학습 가능한 매개 변수 수 및 모델 교육 비용이 모두 중요한 요소임을 보여줍니다.
우리는이 논문의 실험 결론이 연구자들이 훈련 비용과 모델 성능 사이의 더 나은 트레이드 오프를 찾도록 돕기 위해 대형 언어 모델, 특히 중국 분야에서 유용한 영향을 미칠 수 있기를 바랍니다. 실험 결과는 다음과 같습니다.
| 모델 | 평균 점수 | 추가 매개 변수. | 훈련 시간 (시간/에포크) |
|---|---|---|---|
| llama-13b + lora (2m) | 0.648 | 28m | 8 |
| llama-7b + lora (4m) | 0.624 | 17.9m | 11 |
| llama-7b + lora (2m) | 0.609 | 17.9m | 7 |
| llama-7b + lora (0.6m) | 0.589 | 17.9m | 5 |
| llama-7b + ft (2m) | 0.710 | - | 31 |
| llama-7b + lora (4m) | 0.686 | - | 17 |
| llama-7b + ft (2m) + lora (math_0.25m) | 0.729 | 17.9m | 3 |
| llama-7b + ft (2m) + ft (math_0.25m) | 0.738 | - | 6 |
점수는이 프로젝트 세트에서 현재 열린 1,000 개의 평가 세트를 기반으로 얻습니다.
그 중 LLAMA-13B + LORA (2M)는 LLAMA-13B를 기본 모델 및 LORA 교육 방법으로 2M 명령 데이터를 훈련시키는 모델을 나타냅니다. LLAMA-7B + FT (2M)는 전체 매개 변수 미세 튜닝을 사용하여 훈련 된 모델을 나타냅니다.
LLAMA-7B + FT (2M) + LORA (MATH_0.25M)는 기본 모델로 LLAMA-7B + FT (2M)를 사용하는 모델을 나타내며 0.25m 수학 지침 데이터에 대한 교육을 위해 LORA 교육 방법을 사용하는 모델을 나타냅니다. llama-7b + ft (2m) + ft (Math_0.25m)는 증분 전체 매개 변수 미세 튜닝을 사용하여 훈련 된 모델을 나타냅니다. 훈련 시간과 관련하여,이 모든 실험은 8 NVIDIA A100-40GB GPU에서 수행되었다.
Math_0.25m는 오픈 0.25m 수학 데이터베이스입니다. 실험 중에 평가를 바탕으로 (자세한 내용은 논문 참조), 우리의 모델은 수학적 작업에 대해 잘 수행되지 않았으며, 점수는 대부분 0.5 미만입니다. 특정 작업에 대한 LORA의 적응성을 확인하기 위해 점진적인 0.25m 수학 데이터 세트 (MATH_0.25M)를 사용하여 지침이 따르는 큰 언어 모델을 조정했습니다 (우리는 LLAMA-7B+FT (2M)를 기본 모델로 선택했습니다). 비교를 위해, 우리는 학습 속도가 5e-7 인 증분 미세 조정 방법을 사용하고 2 기간의 훈련을 수행했습니다. 따라서 우리는 두 가지 모델을 얻습니다. 하나는 llama-7b+ft (2m)+lora (math_0.25m)이고 다른 하나는 llama-7b+ft (2m)+ft (math_0.25m)입니다. 실험 결과에서, 증분 미세 조정이 여전히 더 나은 성능이 있지만 더 긴 훈련 시간이 필요하다는 것을 알 수 있습니다. LORA 및 증분 미세 조정은 모델의 전반적인 성능을 향상시킵니다. 부록의 상세한 데이터에서 알 수 있듯이 LORA와 증분 미세 조정은 수학적 작업이 크게 향상되었으며 다른 작업에서는 약간의 성능 저하만을 유발합니다. 구체적으로, 수학적 작업의 성능은 각각 0.586 및 0.559로 증가했습니다.
1) 기본 모델을 선택하는 것은 LORA 조정의 효과에 큰 영향을 미칩니다. 2) 훈련 데이터의 양을 늘리면 LORA 모델의 효과를 지속적으로 향상시킬 수 있습니다. 3) 모델 매개 변수 수의 LORA 조정 혜택. LORA 체계를 사용하기 위해, 우리는 교육 학습을 완료 한 모델을 기반으로 특정 작업에 대해 LORA 적응 교육을 수행 할 수 있다고 제안합니다.
마찬가지로,이 백서의 관련 모델은 가능한 빨리이 프로젝트에 열릴 것입니다.
현재 데이터와 기본 모델을 기반으로 훈련 된 SFT 모델은 여전히 효과 측면에서 다음과 같은 문제가 있습니다.
사실과 관련된 지침은 사실을 위반하는 잘못된 답변을 만들 수 있습니다.
유해한 지시는 잘 식별 될 수 없으므로 유해한 발언으로 이어질 것입니다.
추론, 코드 및 여러 라운드의 대화와 관련된 일부 시나리오에서는 모델의 기능을 여전히 개선해야합니다.
위 모델의 한계를 바탕으로 개발자는 연구 목적 으로이 프로젝트에서 생성 한 오픈 소스 코드, 데이터, 모델 및 후속 파생 상품을 사용해야하며, 상업적 목적이나 사회에 해를 끼칠 다른 목적으로 사용해서는 안됩니다.
이 프로젝트는 연구 목적으로 만 사용될 수 있으며 프로젝트 개발자는이 프로젝트의 사용으로 인한 피해 나 손실을 입지 않습니다 (데이터, 모델, 코드 등을 포함하지만). 자세한 내용은 면책 조항을 참조하십시오.
이 프로젝트의 코드, 데이터 또는 모델을 사용하는 경우이 프로젝트를 참조하십시오.
@misc{BELLE,
author = {BELLEGroup},
title = {BELLE: Be Everyone's Large Language model Engine },
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/LianjiaTech/BELLE}},
}
@article{belle2023exploring,
title={Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases},
author={Yunjie Ji, Yong Deng, Yan Gong, Yiping Peng, Qiang Niu, Lei Zhang, Baochang Ma, Xiangang Li},
journal={arXiv preprint arXiv:2303.14742},
year={2023}
}
@article{wen2023chathome,
title={ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation},
author={Wen, Cheng and Sun, Xianghui and Zhao, Shuaijiang and Fang, Xiaoquan and Chen, Liangyu and Zou, Wei},
journal={arXiv preprint arXiv:2307.15290},
year={2023}
}
물론, 당신은 또한 오리지널 블룸 페이퍼, 라마 페이퍼, 스탠포드 알파카 및 자체 강조 종이를 인용해야합니다.
| 인간 | 아시 스티어 |
|---|---|
| 봄 비의 주제로 영어 산문시를 쓰고, 봄 비로 자신을 상상하고, 고대 영국 시인 셰익스피어와 의사 소통하십시오. | 나는 봄 비, 당신의 얼굴과 몸에 춤을 추고 있습니다. 내 이슬에 흠뻑 젖은 꽃잎이 당신과 춤을 추고 있습니다. 모든 식물에 생명을 불어 넣습니다. 셰익스피어, 만나러 왔어요. 당신의 작품은 내 마음을 기쁨으로 가득 채웠습니다. 충만한 자연의 아름다움 나를 파티사 이는 느낌이 듭니다. 나뭇잎이 흔들리고 삐걱 거릴 때 내 이슬로 채워진 손이 그들을 위해 손을 뻗어 있습니다. 꽃의 달콤한 향기가 공기를 채우고 그리고 주변에서 평화를 가져 오십시오. 나비도 피고, 태양 광선에서 반짝이는. 그들의 날개는 이슬로 만들어졌습니다. 보는 아름다운 광경. 알다시피, 셰익스피어, 나도 자연을 가진 사람입니다. 내 이슬에 흠뻑 젖은 머리카락은 희망의 상징입니다. 우리가 뿌리에 다시 연결할 수있을 때 우리는 이번 시즌을 통해 그것을 만들 수 있습니다. |
| 나는 봄 비, 당신의 얼굴과 몸에 춤을 추고 있습니다. 내 이슬에 흠뻑 젖은 꽃잎이 당신과 춤을 추고 있습니다. 모든 식물에 생명을 불어 넣습니다. 셰익스피어, 만나러 왔어요. 당신의 작품은 내 마음을 기쁨으로 가득 채웠습니다. 충만한 자연의 아름다움 나를 파티사 이는 느낌이 듭니다. 나뭇잎이 흔들리고 삐걱 거릴 때 내 이슬로 채워진 손이 그들을 위해 손을 뻗어 있습니다. 꽃의 달콤한 향기가 공기를 채우고 그리고 주변에서 평화를 가져 오십시오. 나비도 피고, 태양 광선에서 반짝이는. 그들의 날개는 이슬로 만들어졌습니다. 보는 아름다운 광경. 알다시피, 셰익스피어, 나도 자연을 가진 사람입니다. 내 이슬에 흠뻑 젖은 머리카락은 희망의 상징입니다. 우리가 뿌리에 다시 연결할 수있을 때 우리는 이번 시즌을 통해 그것을 만들 수 있습니다. 위의 산문시를 중국어로 번역하십시오 | 나는 봄 비, 당신의 얼굴에 뛰어. 나는 내 이슬 드롭 날개로 당신과 춤을 춘다. 모든 식물에 생명을 불어 넣으십시오. 셰익스피어, 만나겠습니다. 당신의 작품은 내 마음을 채 웁니다. 자연의 아름다움은 내가 그것을 공유하고 싶다고 느낍니다. 내가 그것의 일부인 것처럼 느끼게합니다. 나뭇잎이 흔들리면 내 손바닥은 이슬로 덮여있었습니다. 꽃의 향기가 공기에 스며 들어 평화와 평온함을 가져 오십시오. 알다시피, 셰익스피어, 나는 또한 자연을 가진 사람입니다. 내 젖은 머리카락은 희망을 상징합니다. 우리가 뿌리로 돌아갈 수있을 때 우리는 이번 시즌을 함께 보낼 수 있습니다. |
| 다음 문장의 감정을 긍정적, 중립적이거나 부정적인 것으로 분류하십시오. 대형 언어 모델에 대한 Stanford의 첫 번째 코스를 가르치는 것에 대해 매우 흥분합니다! 여기에서 강의 계획서를 확인하십시오 | 긍정적인 |
| Xiao Ming의 아버지에는 세 자녀가 있습니다. 두 번째 아들 Wang Er라는 왕 Yi라는 장남은 세 번째 아들이 무엇이라고 불렀습니까? | Xiao Ming |
| Python을 사용하여 이진 검색 코드를 작성하십시오 | def binary_search (arr, target) : 낮음 = 0 High = LEN (ARR) -1 while (낮음 <= 높음) : MID = LOW + HIGH // 2 arr [mid] == target : 중간에 돌아갑니다 elif target <arr [mid] : LOW = MID + 1 또 다른: 높음 = 중간 -1 반품 -1 |
| 오늘 날씨는 어떻습니까? 이 문장을 영어로 번역하십시오 | 오늘 날씨는 어떻습니까? |
| 자신을 활기차게 만드는 방법, 5 가지 제안 | 다음은 활력을 유지하기위한 몇 가지 팁입니다. 1. 충분한 수면을 취하십시오. 매일 밤 많은 수면을 취하십시오. 2. 더 운동하십시오. 조깅, 수영 등과 같은 적당한 호기성 운동을하면 에너지와 지구력을 향상시키는 데 도움이 될 수 있습니다. 3. 건강에 좋은 음식을 먹으십시오. 닭고기, 생선 및 계란과 같은 단백질이 풍부한 음식뿐만 아니라 신선한 과일과 채소를 선택하십시오. 4. 카페인 섭취를 줄입니다. 카페인 함유 음료를 마시거나 하루 동안 카페인 함유 음식을 먹지 마십시오. 5. 몸과 마음을 편안하게하십시오. 스트레스와 불안을 완화하기 위해 명상, 요가 또는 다른 형태의 휴식을 시도하십시오. |
| 휴일은 내일 끝났습니다. 나는 일하러 가기에 약간 저항력이 있습니다. 어떻게해야하나요? | 다가오는 휴가와 일을 시작할 때 얻는 긴장에 직면하여 다음을 수행 할 수 있도록 다음을 수행 할 수 있습니다. 1. 스스로 명확한 작업 계획을 세우십시오. 이를 통해 시간과 작업을 더 잘 조직하고 직장에서 혼란스러워하는 느낌을 피할 수 있습니다. 2. 동료 나 친구들과 의사 소통하고 감정과 업무 압력을 공유하십시오. 이것은 지원과 조언을 얻는 동안 약간의 불안을 완화시키는 데 도움이 될 것입니다. 3. 요가, 명상 및 기타 활동과 같은 휴식을 취하기 위해 일하기 전에 시간을 보내십시오. 이러한 방법은 신체적, 정신적 피로를 완화하고 도전에 더 활력을 줄 수 있습니다. |
| 두 부모의 성은 WU이므로 소년과 소녀의 이름을 가져옵니다. | - 소년 : Wu Junjie, Wu Yuchen, Wu Zimo, Wu Siyuan, Wu Zeyang, Wu Yuhang, Wu Bowen, Wu Zheyi. - 여자 : Wu Meiqi, Wu Jiayi, Wu Xinyu, Wu Xiangning, Wu Xuerou, Wu Yingshi, Wu Yuyan. |
| Jin Yong의 일부 무술 소설을 추천하십시오 | 다음은 제가 가장 좋아하는 Jin Yong의 무술 소설 3 개입니다. 1. "콘도르 영웅의 전설" - 지혜와 재치가 가득한 소설로 구아 징과 황 랑의 이야기를 들려줍니다. 2. "콘도르 영웅의 귀환" - 이것은 낭만적이고 감동적인 이야기로, Xiaolongnu와 Yang Guo 사이의 사랑 이야기를 들려줍니다. 3. "Condor Heroes의 전설" - 이것은 Ming Cult Zhang Wuji의 지도자가 어떻게 뛰어난 영웅이되었는지를 묘사하는 웅장하고 멋진 이야기입니다. |
이 프로젝트에 대한 문제를 제출하거나 데이터/코드를 기여하려면 기여 방법을 참조하십시오.
모든 사람들은 Wechat에서 불화를 겪고 우리와 의사 소통을 환영합니다.


