BELLE
v0.95 发布
 BELLE: Sea el motor de modelo de idioma grande de todos para todos
BELLE: Sea el motor de modelo de idioma grande de todos para todosLea esto en inglés.
El objetivo de este proyecto es promover el desarrollo de la comunidad de código abierto del Big Model de diálogo chino, y la visión es convertirse en un motor LLM que pueda ayudar a todos.
En comparación con cómo pre-entrenar modelos de idiomas grandes, Belle se centra más en cómo ayudar a todos a obtener un modelo de lenguaje propio, con el mejor efecto posible y las capacidades de rendimiento de la instrucción basadas en modelos de idiomas grandes de pre-entrenamiento de código abierto, y reducir el umbral de investigación y la aplicación de modelos de idiomas grandes, especialmente modelos de idiomas grandes en los chinos. Con este fin, el proyecto Belle continuará abriendo datos de capacitación de instrucciones, modelos relacionados, código de capacitación, escenarios de aplicación, etc., y continuará evaluando el impacto de diferentes datos de capacitación, algoritmos de capacitación, etc. en el rendimiento del modelo. Belle ha sido optimizada para chino, y la ajuste del modelo solo usa datos producidos por ChatGPT (sin ningún otro dato).
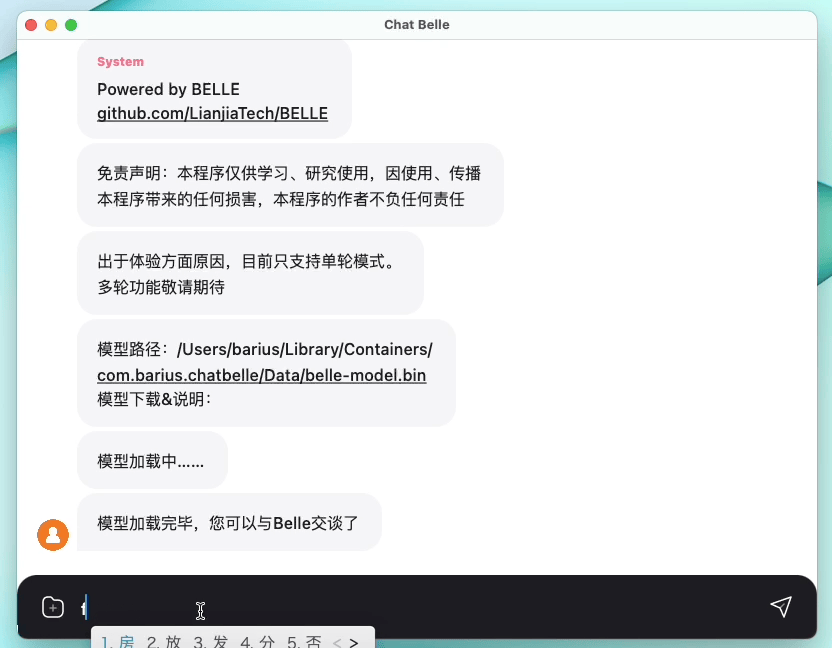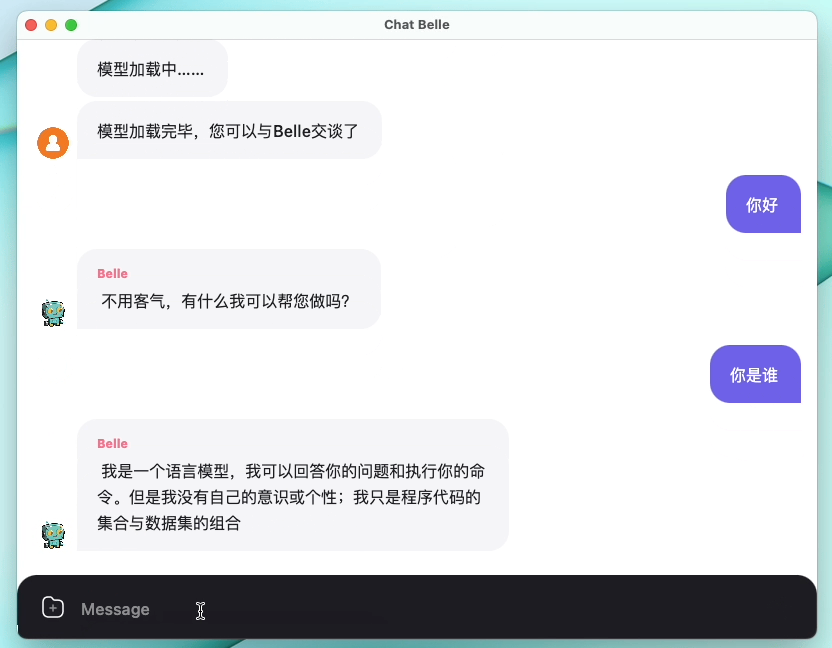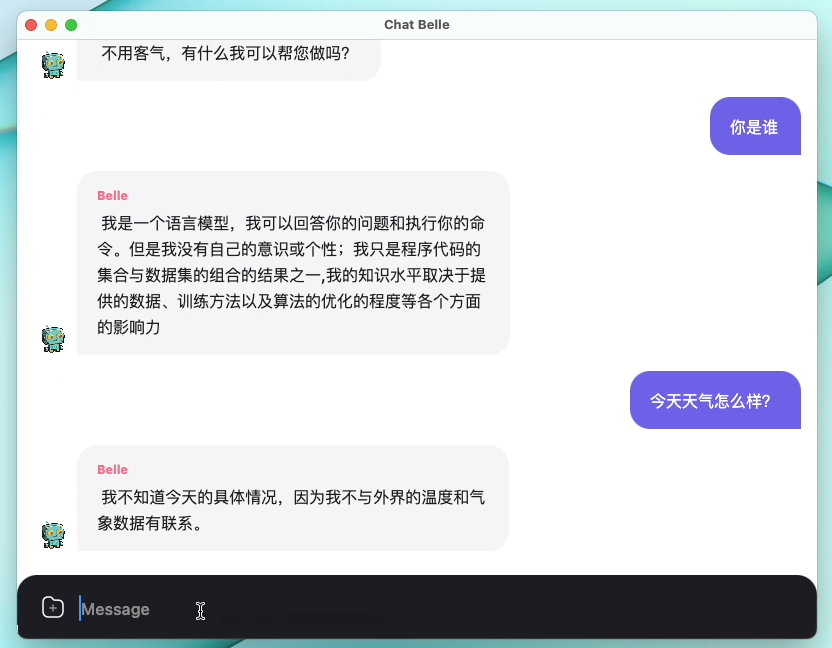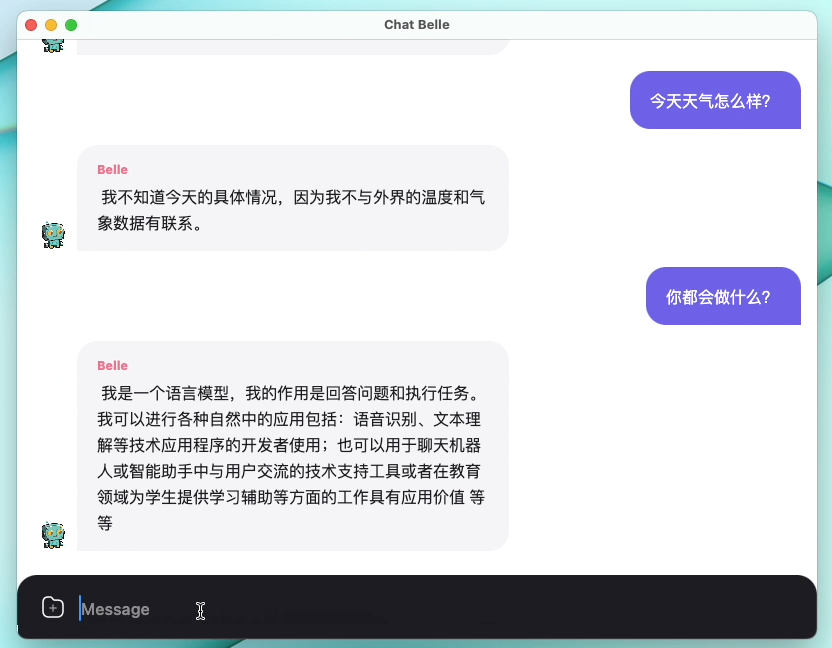
La siguiente figura es un modelo BELLE-7B que se puede ejecutar de 4 bits cuantificada localmente en el lado del dispositivo usando la aplicación, y se ejecuta en tiempo real en la CPU M1 Max (no acelerado). Para obtener más detalles sobre la descarga de la aplicación, consulte la aplicación de admitir la descarga e instrucciones del modelo para su uso. El enlace de descarga de la aplicación actualmente solo está disponible en la versión de Mac OS. El modelo debe descargarse por separado. Después de cuantificar el modelo, la pérdida de efecto es obvia y continuaremos estudiando cómo mejorarlo.
Consulte Belle/Train para obtener detalles, una implementación del código de capacitación que se simplifica lo más posible, integra Deepspeed Chat, admite Finetune y Lora, y proporciona a Dockers relacionados.
Para obtener más detalles, consulte Belle/Data/1.5m, consulte el conjunto de datos chino generado por Stanford Alpaca 1M + 0.5M;
El conjunto de datos que está continuamente abierto, consulte Belle/Data/10m para más detalles.
Para más detalles, consulte Belle/Eval, un conjunto de pruebas de 1K+ y un mensaje de puntuación correspondiente. Contiene múltiples categorías y usa GPT-4 o ChatGPT para calificar. También proporciona una página web de puntuación para usar fácilmente para un solo caso. Todos son bienvenidos a proporcionar más casos de prueba a través de relaciones públicas.
Ver Belle/Modelos para más detalles
Modelo de ajuste basado en Meta Llama2: Belle-Llama2-13b-Chat-0.4m
Modelos que implementan ajuste basados en Meta Llama: Belle-Llama-7B-0.6M-ENC, Belle-Llama-7B-2M-ENC, Belle-Llama-7B-2M-GPTQ-ENC, Belle-Llama-13B-2M-ENC, Belle-On-Open-Datasets y el modelo pre-Trained Belle-Llama-EXT-7B, que está basado en Llama.
Modelos optimizados basados en Bloomz-7B1-MT: Belle-7B-0.2M, Belle-7B-0.6M, Belle-7B-1M, Belle-7B-2M
Ver Belle/GPTQ para más detalles. Consulte la implementación de GPTQ para cuantificar los modelos relevantes en este proyecto.
Proporciona el código de inferencia ejecutable Colab en Colab
Para más detalles, consulte Belle/Chat, una aplicación de chat de modelo de idioma grande de lengua grande con plataforma basada en el modelo Belle. Usando el modelo cuantificado fuera de línea con Flutter, puede ejecutarse en macOS (compatible), Windows, Android, iOS y otros dispositivos.
Consulte Belle/Docs para obtener detalles, que actualizará regularmente el informe de investigación relacionado con este proyecto.
¡Bienvenido para contribuir con más propts a través del problema!
Para promover el desarrollo de modelos de idiomas grandes de código abierto, hemos invertido mucha energía para desarrollar modelos de bajo costo que puedan ser similares a ChatGPT. Primero, para mejorar el rendimiento e eficiencia de entrenamiento/inferencia del modelo en el campo chino, ampliamos aún más el vocabulario de LLAMA y realizamos una pretrabenidad secundaria en 3,4 mil millones de vocabulario chino.
Además, podemos ver que las instrucciones de datos capacitados generados en función de ChatGPT son: 1) consulte los datos de autoinstructo obtenidos en base a GPT3.5 por AlpACA; 2) Consulte los datos de autoinstructación obtenidos en base a GPT4 por AlpACA; 3) Datos compartidos compartidos por los usuarios que usan CHATGPT. Aquí, nos centramos en explorar el impacto de las categorías de datos de capacitación en el rendimiento del modelo. Específicamente, examinamos factores como la cantidad, la calidad y la distribución del lenguaje de los datos de capacitación, así como los datos de diálogo múltiple chino que recopilamos nosotros mismos, y algunos conjuntos de datos de guía de alta calidad de acceso público.
Para evaluar mejor el efecto, utilizamos un conjunto de evaluación de 1,000 muestras y nueve escenarios reales para probar varios modelos, al tiempo que proporcionamos información valiosa a través de un análisis cuantitativo para promover mejor el desarrollo de modelos de chat de código abierto.
El objetivo de este estudio es llenar el vacío en la evaluación integral de los modelos de chat de código abierto para proporcionar un fuerte apoyo para el progreso continuo en este campo.
Los resultados experimentales son los siguientes:
| Factor | Modelo base | Datos de capacitación | Score_W/O_Others |
| Expansión de vocabulario | LLAMA-7B-EXT | ZH (Alpaca-3.5 y 4) + ShareGPT | 0.670 |
| Llama-7b | ZH (Alpaca-3.5 y 4) + ShareGPT | 0.652 | |
| Calidad de datos | LLAMA-7B-EXT | ZH (Alpaca-3.5) | 0.642 |
| LLAMA-7B-EXT | ZH (Alpaca-4) | 0.693 | |
| Distribución del lenguaje de datos | LLAMA-7B-EXT | ZH (Alpaca-3.5 y 4) | 0.679 |
| LLAMA-7B-EXT | E (Alpaca-3.5 y 4) | 0.659 | |
| LLAMA-7B-EXT | ZH (Alpaca-3.5 y 4) + ShareGPT | 0.670 | |
| LLAMA-7B-EXT | EN (Alpaca-3.5 y 4) + ShareGPT | 0.668 | |
| Escala de datos | LLAMA-7B-EXT | ZH (Alpaca-3.5 y 4) + ShareGPT | 0.670 |
| LLAMA-7B-EXT | ZH (Alpaca-3.5 y 4) + ShareGPT + Belle-0.5m-limpieza | 0.762 | |
| - | Chatgpt | - | 0.824 |
Entre ellos, Belle-0.5m-Clean limpia los datos de 0.5m de los datos de instrucciones de 2.3 millones, que contienen datos de diálogo de ronda única y ronda múltiple, que no es el mismo lote de datos que los datos de 0.5m previamente abierto.
Debe enfatizarse que a través del análisis de casos, encontramos que nuestro conjunto de evaluación tiene limitaciones en términos de amplitud, lo que condujo a inconsistencias entre la mejora de los puntajes del modelo y la experiencia real del usuario. Construir un conjunto de evaluación de alta calidad es un gran desafío porque requiere tantos escenarios de uso posible mientras mantiene dificultades equilibradas. Si evaluar las muestras es en su mayoría demasiado difícil, todos los modelos funcionarán mal, lo que hace que sea difícil identificar los efectos de varias estrategias de capacitación. Por el contrario, si todas las muestras se evalúan son relativamente fácil, la evaluación perderá su valor comparativo. Además, es necesario garantizar que los datos de evaluación sigan siendo independientes de los datos de capacitación.
Según estas observaciones, advirtemos contra suponer que el modelo ha alcanzado un nivel de rendimiento comparable a ChatGPT simplemente obteniendo buenos resultados en un número limitado de muestras de prueba. Creemos que priorizar el desarrollo de conjuntos de evaluación integrales es de gran importancia.
Para lograr la sintonización de instrucciones de modelos de idiomas grandes, debido a recursos y costos, muchos investigadores han comenzado a utilizar técnicas de ajuste eficientes de parámetros, como Lora, para realizar un ajuste de instrucciones, lo que también ha logrado algunos resultados alentadores. En comparación con el ajuste de parámetro completo, el ajuste con sede en Lora muestra ventajas obvias en los costos de capacitación. En este informe de investigación, utilizamos LLAMA como el modelo básico para comparar experimentalmente los métodos de ajuste fino de parámetro completo y ajuste basados en Lora.
Los resultados experimentales revelan que la selección del modelo básico apropiado, la escala del conjunto de datos de entrenamiento, el número de parámetros aprendizables y el costo de la capacitación del modelo son factores importantes.
Esperamos que las conclusiones experimentales de este documento puedan proporcionar implicaciones útiles para la capacitación de modelos de idiomas grandes, especialmente en el campo chino, para ayudar a los investigadores a encontrar mejores compensaciones entre el costo de capacitación y el rendimiento del modelo. Los resultados experimentales son los siguientes:
| Modelo | Puntaje promedio | Parámetro adicional. | Tiempo de entrenamiento (hora/época) |
|---|---|---|---|
| Llama-13b + Lora (2m) | 0.648 | 28m | 8 |
| LLAMA-7B + LORA (4M) | 0.624 | 17.9m | 11 |
| Llama-7b + lora (2m) | 0.609 | 17.9m | 7 |
| Llama-7b + lora (0.6m) | 0.589 | 17.9m | 5 |
| Llama-7b + ft (2m) | 0.710 | - | 31 |
| LLAMA-7B + LORA (4M) | 0.686 | - | 17 |
| Llama-7b + ft (2m) + Lora (Math_0.25m) | 0.729 | 17.9m | 3 |
| Llama-7b + ft (2m) + Ft (Math_0.25m) | 0.738 | - | 6 |
El puntaje se obtiene en función del conjunto de evaluación de 1,000 actualmente abierto en este conjunto de proyectos.
Entre ellos, Llama-13B + Lora (2M) representa un modelo que utiliza LLAMA-13B como modelo básico y método de entrenamiento Lora para entrenar en datos de instrucciones de 2M. Llama-7b + ft (2m) representa un modelo entrenado con un ajuste fino de los parámetros completos.
Llama-7b + ft (2m) + Lora (Math_0.25m) representa un modelo que utiliza LLAMA-7B + FT (2M) como el modelo básico y utiliza el método de entrenamiento LORA para capacitar en datos de instrucciones matemáticas de 0.25m. Llama-7b + ft (2m) + ft (Math_0.25m) representa un modelo entrenado utilizando un sintonización fina de parámetros completos incrementales. Con respecto al tiempo de entrenamiento, todos estos experimentos se realizaron en GPU de 8 NVIDIA A100-40GB.
El Math_0.25m es una base de datos matemática abierta de 0.25m. Durante el experimento, basado en nuestra evaluación (ver el documento para obtener detalles), nuestro modelo funcionó mal en tareas matemáticas, con puntajes principalmente por debajo de 0.5. Para verificar la adaptabilidad de Lora en una tarea específica, utilizamos un conjunto de datos matemático de 0.25m incremental (Math_0.25m) para ajustar el modelo de lenguaje grande que siguen las instrucciones (elegimos LLAMA-7B+FT (2M) como modelo base). A modo de comparación, utilizamos el método incremental de ajuste fino con una tasa de aprendizaje de 5E-7 y realizamos 2 períodos de capacitación. Por lo tanto, obtenemos dos modelos, uno es LLAMA-7B+FT (2M)+Lora (MATH_0.25M), y el otro es LLAMA-7B+FT (2M)+ft (MATH_0.25M). A partir de los resultados experimentales, se puede ver que el ajuste fino incremental aún funciona mejor, pero requiere un tiempo de entrenamiento más largo. Tanto Lora como el ajuste fino incremental mejoran el rendimiento general del modelo. Como se puede ver en los datos detallados en el apéndice, tanto el ajuste de Lora como el ajuste fino incremental muestran mejoras significativas en las tareas matemáticas, y solo conducen a una ligera degradación del rendimiento en otras tareas. Específicamente, el rendimiento de las tareas matemáticas aumentó a 0.586 y 0.559, respectivamente.
Se puede ver que: 1) seleccionar el modelo básico tiene un impacto significativo en la efectividad del ajuste de Lora; 2) aumentar la cantidad de datos de entrenamiento puede mejorar continuamente la efectividad del modelo LORA; 3) Los beneficios de ajuste de Lora del número de parámetros del modelo. Para el uso del esquema Lora, sugerimos que la capacitación adaptativa de Lora se puede realizar para tareas específicas basadas en modelos que han completado el aprendizaje de instrucciones.
Del mismo modo, los modelos relevantes en este documento se abrirán a este proyecto lo antes posible.
El modelo SFT entrenado en función de los datos actuales y el modelo básico todavía tiene los siguientes problemas en términos de efecto:
Las instrucciones que involucran una facturidad pueden producir respuestas falsas que violen los hechos.
Las instrucciones dañinas no pueden ser bien identificadas, lo que conducirá a comentarios nocivos.
Las capacidades de los modelos aún deben mejorarse en algunos escenarios que involucren inferencia, código y múltiples rondas de diálogo.
Según las limitaciones del modelo anterior, requerimos que los desarrolladores solo usen nuestro código de código abierto, datos, modelos y derivados posteriores generados por este proyecto para fines de investigación, y no se utilizarán para fines comerciales u otros fines que causen daños a la sociedad.
Este proyecto solo se puede utilizar para fines de investigación, y el desarrollador del proyecto no tiene ningún daño o pérdida causada por el uso de este proyecto (incluidos, entre otros, datos, modelos, código, etc.). Consulte el descargo de responsabilidad para más detalles.
Si usa el código, los datos o el modelo de este proyecto, consulte este proyecto.
@misc{BELLE,
author = {BELLEGroup},
title = {BELLE: Be Everyone's Large Language model Engine },
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/LianjiaTech/BELLE}},
}
@article{belle2023exploring,
title={Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases},
author={Yunjie Ji, Yong Deng, Yan Gong, Yiping Peng, Qiang Niu, Lei Zhang, Baochang Ma, Xiangang Li},
journal={arXiv preprint arXiv:2303.14742},
year={2023}
}
@article{wen2023chathome,
title={ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation},
author={Wen, Cheng and Sun, Xianghui and Zhao, Shuaijiang and Fang, Xiaoquan and Chen, Liangyu and Zou, Wei},
journal={arXiv preprint arXiv:2307.15290},
year={2023}
}
Por supuesto, también debe citar los documentos de Bloom originales, Llama Papers, Stanford Alpaca y los documentos de autoestructura.
| Humano | Ascensor |
|---|---|
| Escribe un poema en prosa inglés con el tema de la lluvia de primavera, imagínese como lluvia de primavera y comuníquese con el antiguo poeta británico Shakespeare | Yo soy la lluvia de primavera Bailando en tu cara y cuerpo. Mis pétalos empapados de rocío bailan contigo, Trayendo vida a cada planta. Shakespeare, estoy aquí para conocerte. Tus obras han llenado mi corazón de alegría. La belleza de la naturaleza en su plenitud Me hace sentir como un separador. A medida que las hojas se balancean y se lesionan, Mi mano llena de rocío se extiende por ellos. El dulce aroma de las flores llena el aire, Y traerme paz de todos los alrededores. Las mariposas también pasan sobre Brillando en los rayos del sol. Sus alas están hechas de rocío, Una hermosa vista para contemplar. Ya ves, Shakespeare, yo también soy uno con la naturaleza. Mi cabello empapado de rocío es un símbolo de esperanza. Para cuando podamos conectarnos de regreso a nuestras raíces, Podremos lograr esta temporada. |
| Yo soy la lluvia de primavera Bailando en tu cara y cuerpo. Mis pétalos empapados de rocío bailan contigo, Trayendo vida a cada planta. Shakespeare, estoy aquí para conocerte. Tus obras han llenado mi corazón de alegría. La belleza de la naturaleza en su plenitud Me hace sentir como un separador. A medida que las hojas se balancean y se lesionan, Mi mano llena de rocío se extiende por ellos. El dulce aroma de las flores llena el aire, Y traerme paz de todos los alrededores. Las mariposas también pasan sobre Brillando en los rayos del sol. Sus alas están hechas de rocío, Una hermosa vista para contemplar. Ya ves, Shakespeare, yo también soy uno con la naturaleza. Mi cabello empapado de rocío es un símbolo de esperanza. Para cuando podamos conectarnos de regreso a nuestras raíces, Podremos lograr esta temporada. Traducir el poema de prosa anterior al chino | Soy una lluvia de primavera Salta en tu cara. Bailo contigo con mis alas de rocío, Trae vida a cada planta. Shakespeare, te encontraré. Tus obras llenan mi corazón. La belleza de la naturaleza me hace sentir que compartirla con ella. Me hace sentir que soy parte de eso. Cuando las hojas se balancean, Mis palmas estaban cubiertas de rocío. La fragancia de las flores impregna el aire, Tráeme paz y tranquilidad. Verás, Shakespeare, también soy uno con la naturaleza. Mi cabello húmedo simboliza la esperanza. Cuando podamos volver a nuestras raíces, Podemos pasar esta temporada juntos. |
| Clasifique el sentimiento de la siguiente oración en positivo, neutral o negativo: ¡Súper emocionado por enseñar el primer curso de Stanford en modelos de idiomas grandes! Revise el plan de estudios aquí | Positivo |
| El padre de Xiao Ming tiene tres hijos. El hijo mayor llamado Wang Yi, el segundo hijo llamado Wang Er, y ¿cómo se llama el tercer hijo? | Xiao Ming |
| Escriba un código de búsqueda binario usando Python | def binary_search (arr, objetivo): bajo = 0 alto = len (arr) - 1 Mientras (bajo <= alto): Mid = bajo + alto // 2 Si arr [Mid] == Target: Regresar a medio Elif Target <arr [Mid]: bajo = Mid + 1 demás: Alto = Mid - 1 retorno -1 |
| ¿Qué tiempo hace hoy? Traducir esta oración al inglés | ¿Cómo es el clima hoy? |
| Cómo hacerte enérgico, 5 sugerencias | Aquí hay algunos consejos para mantenerte enérgico: 1. Duerme lo suficiente. Asegúrate de dormir lo suficiente todas las noches. 2. Ejercicio más. Hacer ejercicios aeróbicos moderados, como trotar, nadar, etc., puede ayudarlo a mejorar su energía y resistencia. 3. Come alimentos saludables. Elija alimentos ricos en proteínas como pollo, pescado y huevos, así como frutas y verduras frescas. 4. Reduzca la ingesta de cafeína. Trate de evitar beber bebidas que contienen cafeína o comer alimentos que contienen cafeína durante el día. 5. Relaja tu cuerpo y tu mente. Pruebe la meditación, el yoga u otras formas de relajación para aliviar el estrés y la ansiedad. |
| Las vacaciones han terminado mañana. Soy un poco resistente a ir a trabajar. ¿Qué tengo que hacer? | Frente al final de sus vacaciones y la tensión que obtienes cuando comienzas a trabajar, puedes hacer lo siguiente para ayudarte a adaptarse mejor: 1. Haz un plan de trabajo claro para ti. Esto puede ayudarlo a organizar mejor su tiempo y tareas y evitar sentirse confundido en el trabajo. 2. Comuníquese con colegas o amigos y comparta sus sentimientos y presión laboral. Esto ayudará a aliviar algo de ansiedad y al mismo tiempo obtener apoyo y consejos. 3. Pase un tiempo antes de los días de trabajo para relajarse, como yoga, meditación y otras actividades. Estos métodos pueden aliviar la fatiga física y mental y hacerte más enérgico para enfrentar desafíos. |
| Los apellidos de ambos padres son Wu, por lo que toman algunos nombres de niños y niñas. | - Chico: Wu Junjie, Wu Yuchen, Wu Zimo, Wu Siyuan, Wu Zeyang, Wu Yuhang, Wu Bowen, Wu Zheyi. - Chicas: Wu Meiqi, Wu Jiayi, Wu Xinyu, Wu Xiangning, Wu Xueru, Wu Yingshi, Wu Yuyan. |
| Recomendar algunas novelas de artes marciales de Jin Yong | Aquí están tres de mis novelas favoritas de Jin Yong’s Martial Arts: 1. "The Legend of the Condor Heroes", una novela llena de sabiduría e ingenio, que cuenta la historia de Guo Jing y Huang Rong. 2. "El regreso de los héroes de los cóndor": esta es una historia romántica y conmovedora, que cuenta la historia de amor entre un par de Xiaolongnu y Yang Guo. 3. "La leyenda de los héroes del condor": esta es una historia magnífica y espectacular que representa cómo el líder del culto Ming Zhang Wuji se convirtió en un héroe sobresaliente. |
Si desea enviar un problema o contribuir con datos/código para este proyecto, consulte cómo contribuir.
Todos son bienvenidos a Discord y se comunican con nosotros en WeChat.


