BELLE
v0.95 发布
 BELLE: Be Everyone's Large Language model Engine
BELLE: Be Everyone's Large Language model EngineRead this in English.
The goal of this project is to promote the development of the Chinese dialogue big model open source community, and the vision is to become LLM Engine that can help everyone.
Compared to how to pre-train large language models, BELLE focuses more on how to help everyone obtain a language model of their own, with the best possible effect and instruction performance capabilities based on open source pre-training large language models, and reduce the research and application threshold of large language models, especially large language models in Chinese. To this end, the BELLE project will continue to open instruction training data, related models, training code, application scenarios, etc., and will continue to evaluate the impact of different training data, training algorithms, etc. on the model performance. BELLE has been optimized for Chinese, and model tuning only uses data produced by ChatGPT (without any other data).
The following figure is a BELLE-7B model that can be run 4bit quantized locally on the device side using the App, and runs in real time on the M1 Max CPU (not accelerated). For details on the app download, please refer to the App Supporting Model Download and Instructions for Use. The App Download Link is currently only available on the Mac Os version. The model needs to be downloaded separately. After the model is quantified, the effect loss is obvious, and we will continue to study how to improve it.
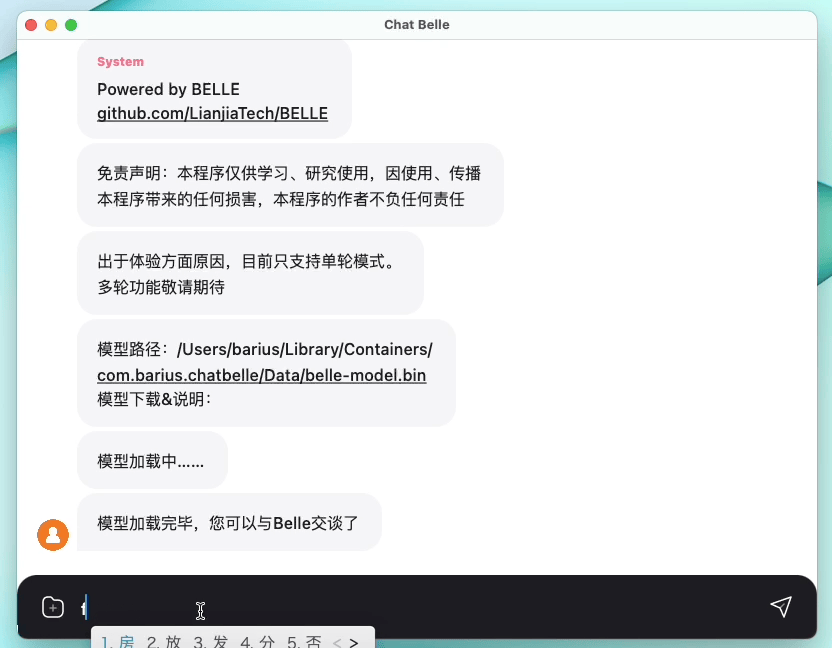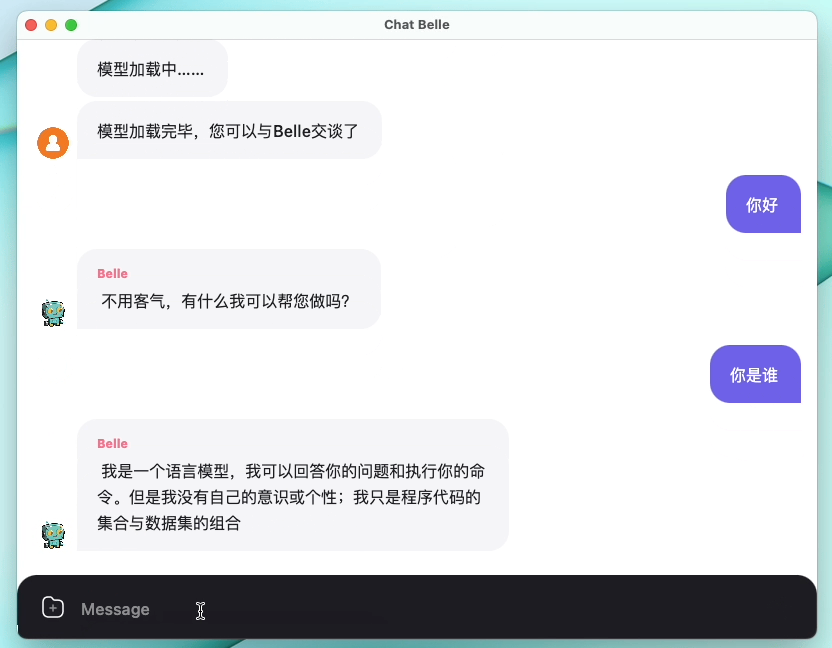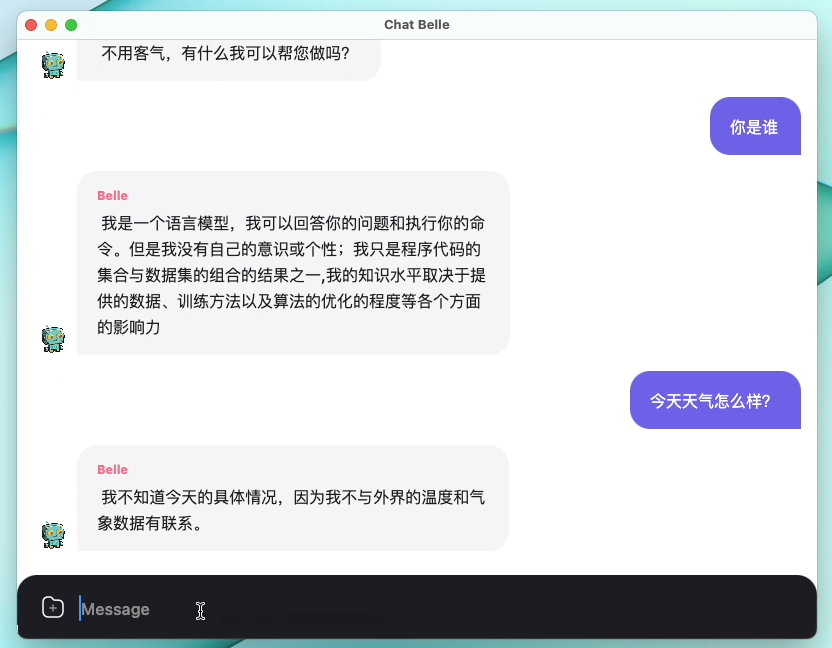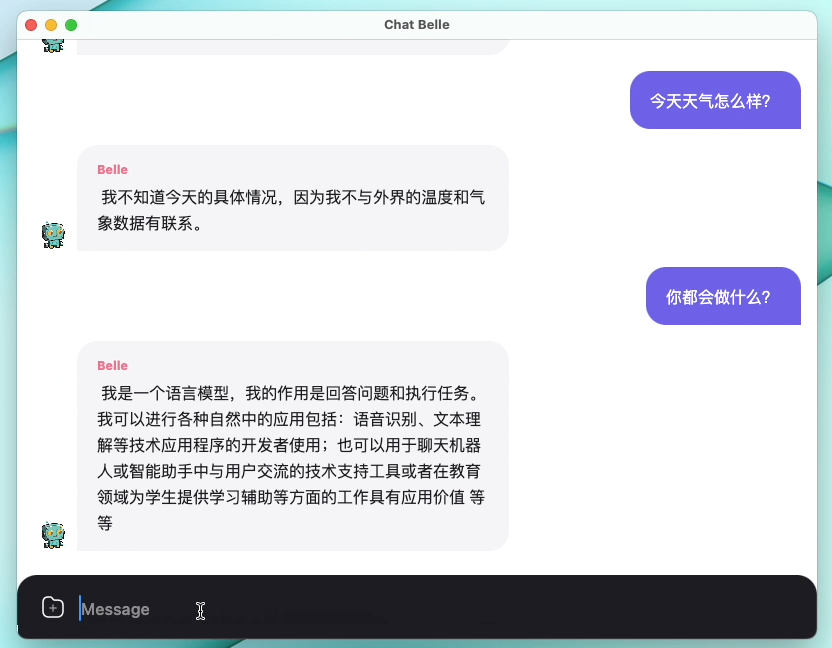
See BELLE/train for details, a training code implementation that is as simplified as possible, integrates Deepspeed-Chat, supports finetune and lora, and provides related dockers.
For details, see BELLE/data/1.5M, refer to the Chinese data set generated by Stanford Alpaca 1M + 0.5M;
The data set that is continuously open, please refer to BELLE/data/10M for details.
For details, see BELLE/eval, a 1k+ test set, and corresponding scoring prompt. It contains multiple categories and uses GPT-4 or ChatGPT to score. It also provides a scoring web page for easy use for a single case. Everyone is welcome to provide more test cases through PR.
See BELLE/models for details
Model for tuning based on Meta LLaMA2: BELLE-Llama2-13B-chat-0.4M
Models that implement tuning based on Meta LLaMA: BELLE-LLaMA-7B-0.6M-enc , BELLE-LLaMA-7B-2M-enc , BELLE-LLaMA-7B-2M-gptq-enc , BELLE-LLaMA-13B-2M-enc , BELLE-on-Open-Datasets , and the pre-trained model BELLE-LLaMA-EXT-7B, which is based on LLaMA, has been expanded in Chinese vocabulary.
Models optimized based on BLOOMZ-7B1-mt: BELLE-7B-0.2M, BELLE-7B-0.6M, BELLE-7B-1M, BELLE-7B-2M
See BELLE/gptq for details. Refer to the implementation of gptq to quantify the relevant models in this project.
Provides the runnable inference code Colab on colab
For details, see BELLE/chat, a cross-platform offline large language model chat app based on the BELLE model. Using the quantized offline model with Flutter, it can run on macOS (supported), Windows, Android, iOS and other devices.
See BELLE/docs for details, which will regularly update the research report related to this project.
Welcome to contribute more propts through issue!
In order to promote the development of open source large language models, we have invested a lot of energy to develop low-cost models that can be similar to ChatGPT. First, in order to improve the performance and training/inference efficiency of the model in the Chinese field, we further expanded the vocabulary of LLaMA and performed secondary pre-training on 3.4 billion Chinese vocabulary.
In addition, we can see that the instructions trained data generated based on ChatGPT are: 1) Refer to the self-instruct data obtained based on GPT3.5 by Alpaca; 2) Refer to the self-instruct data obtained based on GPT4 by Alpaca; 3) ShareGPT data shared by users using ChatGPT. Here, we focus on exploring the impact of training data categories on model performance. Specifically, we examine factors such as quantity, quality, and language distribution of training data, as well as the Chinese multi-round dialogue data we collected ourselves, and some publicly accessible high-quality guidance datasets.
To better evaluate the effect, we used an evaluation set of 1,000 samples and nine real scenarios to test various models, while providing valuable insights through quantitative analysis to better promote the development of open source chat models.
The goal of this study is to fill the gap in the comprehensive evaluation of open source chat models in order to provide strong support for continued progress in this field.
The experimental results are as follows:
| Factor | Base model | Training data | Score_w/o_others |
| Vocabulary expansion | LLaMA-7B-EXT | zh(alpaca-3.5&4) + sharegpt | 0.670 |
| LLaMA-7B | zh(alpaca-3.5&4) + sharegpt | 0.652 | |
| Data quality | LLaMA-7B-EXT | zh(alpaca-3.5) | 0.642 |
| LLaMA-7B-EXT | zh(alpaca-4) | 0.693 | |
| Data language distribution | LLaMA-7B-EXT | zh(alpaca-3.5&4) | 0.679 |
| LLaMA-7B-EXT | en(alpaca-3.5&4) | 0.659 | |
| LLaMA-7B-EXT | zh(alpaca-3.5&4) + sharegpt | 0.670 | |
| LLaMA-7B-EXT | en(alpaca-3.5&4) + sharegpt | 0.668 | |
| Data Scale | LLaMA-7B-EXT | zh(alpaca-3.5&4) + sharegpt | 0.670 |
| LLaMA-7B-EXT | zh(alpaca-3.5&4) + sharegpt + BELLE-0.5M-CLEAN | 0.762 | |
| - | ChatGPT | - | 0.824 |
Among them, BELLE-0.5M-CLEAN cleans the 0.5M data from 2.3 million instruction data, which contains single-round and multiple-round dialogue data, which is not the same batch of data as the previously opened 0.5M data.
It should be emphasized that through case analysis, we found that our evaluation set has limitations in terms of comprehensiveness, which led to inconsistencies between the improvement of model scores and the actual user experience. Building a high-quality evaluation set is a huge challenge because it requires as many usage scenarios as possible while maintaining balanced difficulty. If evaluating samples is mostly too difficult, all models will perform poorly, making it challenging to identify the effects of various training strategies. On the contrary, if all samples are evaluated are relatively easy, the evaluation will lose its comparative value. In addition, it is necessary to ensure that the evaluation data remains independent from the training data.
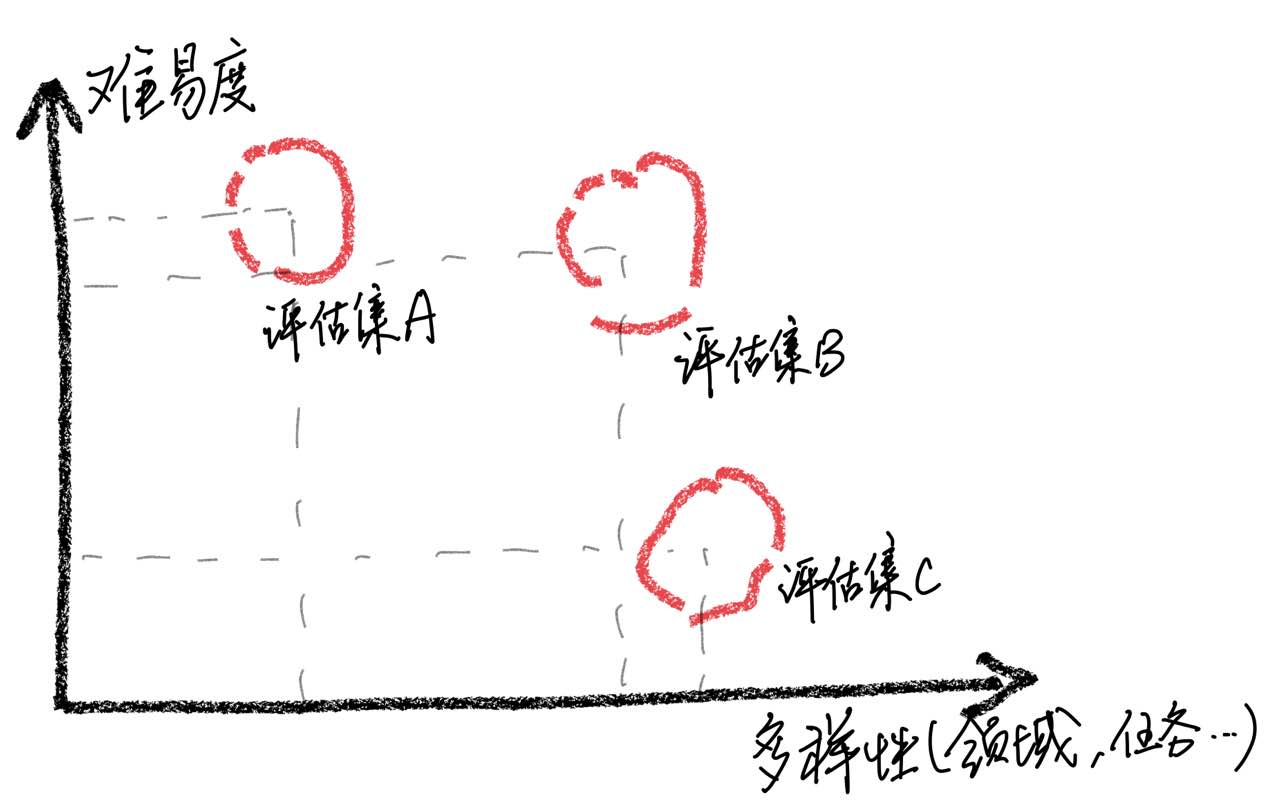
Based on these observations, we caution against assuming that the model has achieved a performance level comparable to ChatGPT by simply obtaining good results on a limited number of test samples. We believe that prioritizing the development of comprehensive assessment sets is of great significance.
In order to achieve instruction tuning of large language models, due to resources and costs, many researchers have begun to use parameter-efficient tuning techniques, such as LoRA, to perform instruction tuning, which has also achieved some encouraging results. Compared with full-parameter fine-tuning, LoRA-based tuning shows obvious advantages in training costs. In this research report, we used LLaMA as the basic model to experimentally compare the full-parameter fine-tuning and LoRA-based tuning methods.
The experimental results reveal that the selection of the appropriate basic model, the scale of the training data set, the number of learnable parameters, and the cost of model training are all important factors.
We hope that the experimental conclusions of this paper can provide useful implications for the training of large language models, especially in the Chinese field, to help researchers find better trade-offs between training cost and model performance. The experimental results are as follows:
| Model | Average Score | Additional Param. | Training Time (Hour/epoch) |
|---|---|---|---|
| LLaMA-13B + LoRA(2M) | 0.648 | 28M | 8 |
| LLaMA-7B + LoRA(4M) | 0.624 | 17.9M | 11 |
| LLaMA-7B + LoRA(2M) | 0.609 | 17.9M | 7 |
| LLaMA-7B + LoRA (0.6M) | 0.589 | 17.9M | 5 |
| LLaMA-7B + FT(2M) | 0.710 | - | 31 |
| LLaMA-7B + LoRA(4M) | 0.686 | - | 17 |
| LLaMA-7B + FT(2M) + LoRA(math_0.25M) | 0.729 | 17.9M | 3 |
| LLaMA-7B + FT(2M) + FT(math_0.25M) | 0.738 | - | 6 |
The score is obtained based on the 1,000 evaluation set currently open in this project set.
Among them, LLaMA-13B + LoRA(2M) represents a model that uses LLaMA-13B as the basic model and LoRA training method to train on 2M instruction data. LLaMA-7B + FT(2M) represents a model trained using full parameter fine tuning.
LLaMA-7B + FT(2M) + LoRA(math_0.25M) represents a model that uses LLaMA-7B + FT(2M) as the basic model and uses the LoRA training method for training on 0.25M mathematical instruction data. LLaMA-7B + FT(2M) + FT(math_0.25M) represents a model trained using incremental full parameter fine tuning. Regarding training time, all these experiments were performed on 8 NVIDIA A100-40GB GPUs.
The math_0.25M is an open 0.25M mathematical database. During the experiment, based on our evaluation (see the paper for details), our model performed poorly on mathematical tasks, with scores mostly below 0.5. To verify LoRA’s adaptability on a specific task, we used an incremental 0.25M mathematical dataset (math_0.25M) to adjust the large language model that the instructions follow (we chose LLaMA-7B+FT (2M) as the base model). For comparison, we used the incremental fine-tuning method with a learning rate of 5e-7 and conducted 2 periods of training. Therefore, we get two models, one is LLaMA-7B+FT(2M)+LoRA(math_0.25M), and the other is LLaMA-7B+FT(2M)+FT(math_0.25M). From the experimental results, it can be seen that incremental fine-tuning still performs better, but requires longer training time. Both LoRA and incremental fine-tuning improve the overall performance of the model. As can be seen from the detailed data in the appendix, both LoRA and incremental fine-tuning show significant improvements in mathematical tasks, and only lead to slight performance degradation in other tasks. Specifically, the performance of mathematical tasks increased to 0.586 and 0.559, respectively.
It can be seen that: 1) Selecting the basic model has a significant impact on the effectiveness of LoRA adjustment; 2) Increasing the amount of training data can continuously improve the effectiveness of the LoRA model; 3) LoRA adjustment benefits from the number of model parameters. For the use of LoRA scheme, we suggest that loRA adaptive training can be performed for specific tasks based on models that have completed instruction learning.
Similarly, the relevant models in this paper will be opened to this project as soon as possible.
The SFT model trained based on the current data and basic model still has the following problems in terms of effect:
Instructions involving factuality may produce false answers that violate facts.
The harmful instructions cannot be well identified, which will lead to harmful remarks.
The capabilities of models still need to be improved in some scenarios involving inference, code, and multiple rounds of dialogue.
Based on the limitations of the above model, we require developers to only use our open source code, data, models and subsequent derivatives generated by this project for research purposes, and shall not be used for commercial purposes or other purposes that will cause harm to society.
This project can only be used for research purposes, and the project developer does not bear any harm or loss caused by the use of this project (including but not limited to data, models, code, etc.). Please refer to the disclaimer for details.
If you use the code, data, or model of this project, please refer to this project.
@misc{BELLE,
author = {BELLEGroup},
title = {BELLE: Be Everyone's Large Language model Engine },
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/LianjiaTech/BELLE}},
}
@article{belle2023exploring,
title={Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases},
author={Yunjie Ji, Yong Deng, Yan Gong, Yiping Peng, Qiang Niu, Lei Zhang, Baochang Ma, Xiangang Li},
journal={arXiv preprint arXiv:2303.14742},
year={2023}
}
@article{wen2023chathome,
title={ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation},
author={Wen, Cheng and Sun, Xianghui and Zhao, Shuaijiang and Fang, Xiaoquan and Chen, Liangyu and Zou, Wei},
journal={arXiv preprint arXiv:2307.15290},
year={2023}
}
Of course, you also need to cite the original BLOOM papers, LLaMA papers, Stanford Alpaca and Self-Instruct papers.
| Human | Assitant |
|---|---|
| Write an English prose poem with the theme of spring rain, imagine yourself as spring rain, and communicate with the ancient British poet Shakespeare | I am the spring rain, Dancing on your face and body. My dew-drenched petals dance with you, Bringing life to every plant. Shakespeare, I am here to meet you. Your works have filled my heart with joy. The beauty of nature in its fullness Makes me feel like a partaker. As the leaves sway and rustle by, My dew-filled hand reaches out for them. The sweet scent of flowers fill the air, And bring me peace from all around. Butterflies flit about as well, Glistening in the sun's rays. Their wings are made of dew, A beautiful sight to behold. You see, Shakespeare, I too am one with nature. My dew-drenched hair is a symbol of hope. For when we can connect back to our roots, We will be able to make it through this season. |
| I am the spring rain, Dancing on your face and body. My dew-drenched petals dance with you, Bringing life to every plant. Shakespeare, I am here to meet you. Your works have filled my heart with joy. The beauty of nature in its fullness Makes me feel like a partaker. As the leaves sway and rustle by, My dew-filled hand reaches out for them. The sweet scent of flowers fill the air, And bring me peace from all around. Butterflies flit about as well, Glistening in the sun's rays. Their wings are made of dew, A beautiful sight to behold. You see, Shakespeare, I too am one with nature. My dew-drenched hair is a symbol of hope. For when we can connect back to our roots, We will be able to make it through this season. Translate the above prose poem into Chinese | I'm a spring rain, Jump in your face. I dance with you with my dew-drop wings, Bring life to every plant. Shakespeare, I'll meet you. Your works fill my heart. The beauty of nature makes me feel like sharing it with it. It makes me feel like I'm a part of it. When the leaves sway, My palms were covered with dew. The fragrance of flowers permeates the air, Bring me peace and tranquility. You see, Shakespeare, I am also one with nature. My wet hair symbolizes hope. When we can return to our roots, We can spend this season together. |
| Classify the sentiment of the following sentence into Positive, Neutral, or Negative: Super excited about teaching Stanford's first course on Large Language Models! Check the syllabus out here | Positive |
| Xiao Ming's father has three children. The eldest son called Wang Yi, the second son called Wang Er, and what is the third son called? | Xiao Ming |
| Write a binary search code using python | def binary_search(arr, target): low = 0 high = len(arr) - 1 While (low <= high): mid = low + high // 2 if arr[mid] == target: Return mid elif target < arr[mid]: low = mid + 1 else: high = mid - 1 return -1 |
| How is the weather today? Translate this sentence into English | What's the weather like today? |
| How to make yourself energetic, 5 suggestions | Here are some tips to keep you energetic: 1. Have enough sleep. Make sure you get plenty of sleep every night. 2. Exercise more. Doing moderate aerobic exercises, such as jogging, swimming, etc., can help you improve your energy and endurance. 3. Eat healthy foods. Choose protein-rich foods such as chicken, fish and eggs, as well as fresh fruits and vegetables. 4. Reduce caffeine intake. Try to avoid drinking caffeine-containing beverages or eating caffeine-containing foods during the day. 5. Relax your body and mind. Try meditation, yoga, or other forms of relaxation to relieve stress and anxiety. |
| The holiday is over tomorrow. I’m a little resistant to going to work. What should I do? | Faced with the end of your holiday and the tension you get when you start working, you can do the following to help you adapt better: 1. Make a clear work plan for yourself. This can help you better organize your time and tasks and avoid feeling confused at work. 2. Communicate with colleagues or friends and share your feelings and work pressure. This will help relieve some anxiety while also getting support and advice. 3. Spend some time before work days to relax, such as yoga, meditation and other activities. These methods can relieve physical and mental fatigue and make you more energetic to meet challenges. |
| Both parents’ surnames are Wu, so they take some names of boys and girls | - Boy: Wu Junjie, Wu Yuchen, Wu Zimo, Wu Siyuan, Wu Zeyang, Wu Yuhang, Wu Bowen, Wu Zheyi. - Girls: Wu Meiqi, Wu Jiayi, Wu Xinyu, Wu Xiangning, Wu Xuerou, Wu Yingshi, Wu Yuyan. |
| Recommend some martial arts novels by Jin Yong | Here are three of my favorite Jin Yong’s martial arts novels: 1. "The Legend of the Condor Heroes" - A novel full of wisdom and wit, telling the story of Guo Jing and Huang Rong. 2. "The Return of the Condor Heroes" - This is a romantic and touching story, telling the love story between a couple Xiaolongnu and Yang Guo. 3. "The Legend of the Condor Heroes" - This is a magnificent and spectacular story that depicts how the leader of the Ming Cult Zhang Wuji became an outstanding hero. |
If you want to submit an Issue or contribute data/code for this project, please refer to How to contribute.
Everyone is welcome to Discord and communicate with us on WeChat.


