BELLE
v0.95 发布
 الحسناء: كن محرك نموذج اللغة الكبير للجميع
الحسناء: كن محرك نموذج اللغة الكبير للجميعاقرأ هذا باللغة الإنجليزية.
الهدف من هذا المشروع هو تعزيز تطوير مجتمع الحوار الصيني Big Model Open Source ، والرؤية هي أن تصبح محرك LLM الذي يمكن أن يساعد الجميع.
مقارنةً بكيفية تدريب نماذج اللغة الكبيرة المسبقة ، تركز Belle أكثر على كيفية مساعدة الجميع على الحصول على نموذج لغة خاص بهم ، مع أفضل قدرات أداء واتجاهات تعليمية استنادًا إلى نماذج لغة كبيرة مفتوحة المصدر ، وتقليل عتبة البحث والتطبيق لنماذج اللغة الكبيرة ، وخاصة نماذج اللغة الكبيرة في الصينية. تحقيقًا لهذه الغاية ، سيستمر مشروع Belle في فتح بيانات التدريب على التعليمات ، والنماذج ذات الصلة ، ورمز التدريب ، وسيناريوهات التطبيق ، وما إلى ذلك ، وسيستمر في تقييم تأثير بيانات التدريب المختلفة ، خوارزميات التدريب ، إلخ. تم تحسين Belle للصينية ، ويستخدم ضبط النماذج فقط البيانات التي تنتجها ChatGPT (بدون أي بيانات أخرى).
الشكل التالي هو نموذج Belle-7B يمكن تشغيله 4Bit محليًا على جانب الجهاز باستخدام التطبيق ، ويتم تشغيله في الوقت الفعلي على وحدة المعالجة المركزية M1 Max (غير مسرع). للحصول على تفاصيل حول تنزيل التطبيق ، يرجى الرجوع إلى تنزيل النموذج الداعم للتطبيق والتعليمات للاستخدام. رابط تنزيل التطبيق متاح حاليًا فقط على إصدار Mac OS. يجب تنزيل النموذج بشكل منفصل. بعد تحديد النموذج ، يكون فقدان التأثير واضحًا ، وسنواصل دراسة كيفية تحسينه.
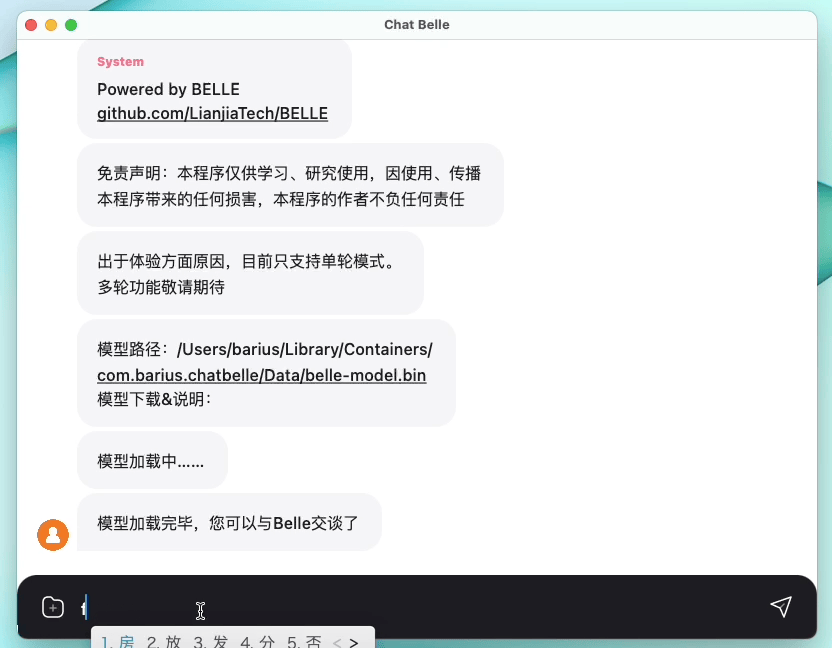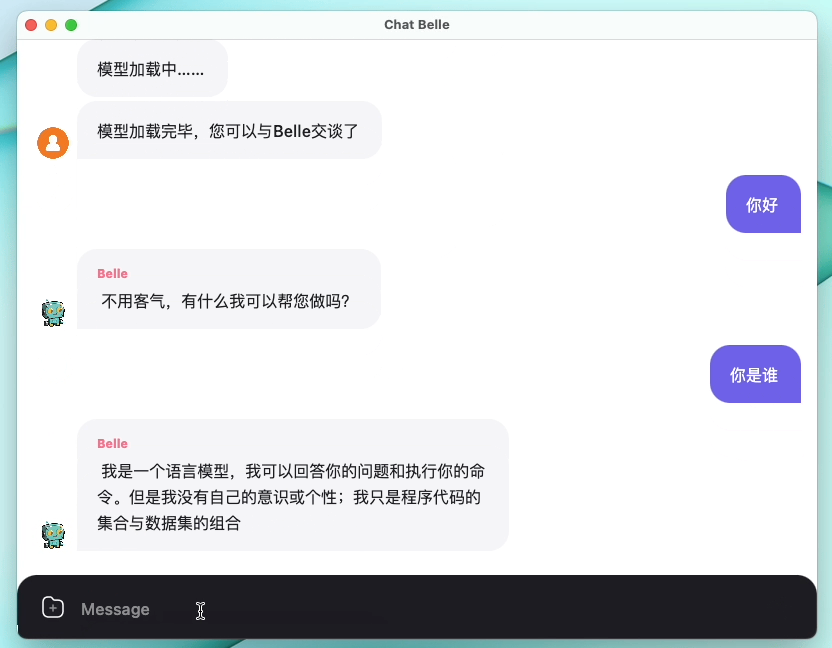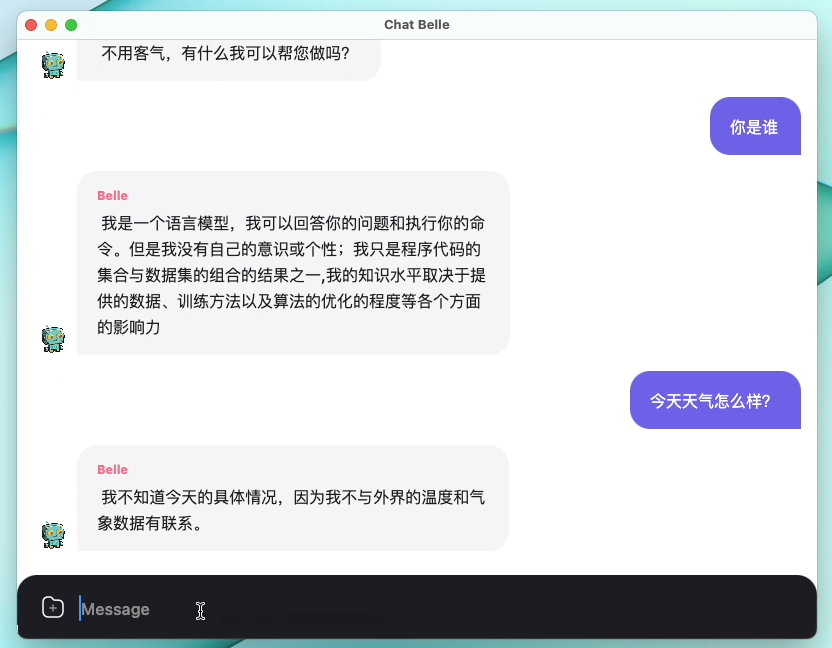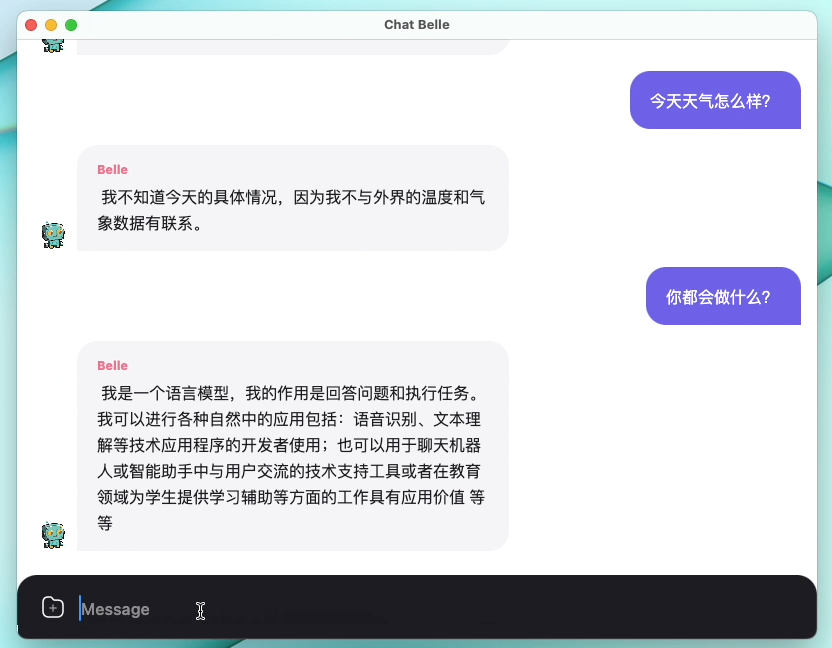
راجع Belle/Train للحصول على التفاصيل ، وهو تطبيق رمز التدريب الذي تم تبسيطه قدر الإمكان ، يدمج الدردشة العميقة ، ويدعم Finetune و Lora ، ويوفر Dockers ذات الصلة.
للحصول على التفاصيل ، راجع Belle/Data/1.5m ، راجع مجموعة البيانات الصينية التي تم إنشاؤها بواسطة Stanford Alpaca 1M + 0.5m ؛
مجموعة البيانات المفتوحة باستمرار ، يرجى الرجوع إلى Belle/Data/10M للحصول على التفاصيل.
للحصول على التفاصيل ، راجع Belle/Eval ، مجموعة اختبار 1K+ ، ومطالبة التسجيل المقابلة. أنه يحتوي على فئات متعددة ويستخدم GPT-4 أو ChatGPT للتسجيل. كما أنه يوفر صفحة ويب للتسجيل لسهولة الاستخدام لحالة واحدة. الجميع مرحب بهم لتوفير المزيد من حالات الاختبار من خلال العلاقات العامة.
انظر Belle/Models للحصول على التفاصيل
نموذج لضبط القائم على meta llama2: belle-llama2-13b-chat-0.4m
النماذج التي تنفذ الضبط على أساس التعريف: Belle-Llama-7B-0.6M-ENC ، Belle-Llama-2M-2M-ENC ، Belle-Llama-7B-2M-GPTQ-ENC ، Belle-Llama-13B-2M-En ، Belle-On-Open-Dates ، و Pre-trained Belle-ext-exp. مفردات.
نماذج مُحسّنة على أساس Bloomz-7B1-MT: Belle-7B-0.2M ، Belle-7B-0.6M ، Belle-7B-1M ، Belle-7B-2M
انظر Belle/GPTQ للحصول على التفاصيل. ارجع إلى تنفيذ GPTQ لتحديد النماذج ذات الصلة في هذا المشروع.
يوفر رمز الاستنتاج القابل للتشغيل كولاب على كولاب
لمزيد من التفاصيل ، راجع Belle/Chat ، وهو تطبيق دردشة طراز اللغة الكبير غير المتصل بالطواية المستندة إلى نموذج Belle. باستخدام الطراز الكمي دون اتصال مع الرفرفة ، يمكن تشغيله على MacOS (مدعوم) ونظام التشغيل Windows و Android و iOS والأجهزة الأخرى.
انظر Belle/Docs للحصول على التفاصيل ، والتي ستقوم بتحديث تقرير البحث بانتظام يتعلق بهذا المشروع.
مرحبًا بك في المساهمة بمزيد من الأدوار من خلال القضية!
من أجل الترويج لتطوير نماذج لغة كبيرة مفتوحة المصدر ، استثمرنا الكثير من الطاقة لتطوير نماذج منخفضة التكلفة يمكن أن تشبه ChatGPT. أولاً ، من أجل تحسين أداء وتدريب/استنتاج النموذج في المجال الصيني ، وسعنا أيضًا مفردات LAMA وأجرنا التدريب الثانوي على 3.4 مليار من المفردات الصينية.
بالإضافة إلى ذلك ، يمكننا أن نرى أن التعليمات المدربة التي تم إنشاؤها بناءً على chatgpt هي: 1) الرجوع إلى بيانات البنية الذاتية التي تم الحصول عليها بناءً على GPT3.5 بواسطة الألبكة ؛ 2) الرجوع إلى بيانات البنية الذاتية التي تم الحصول عليها بناءً على GPT4 بواسطة الألبكة ؛ 3) مشاركة البيانات المشتركة من قبل المستخدمين باستخدام chatgpt. هنا ، نركز على استكشاف تأثير فئات بيانات التدريب على أداء النموذج. على وجه التحديد ، ندرس عوامل مثل الكمية والجودة والتوزيع اللغوي لبيانات التدريب ، وكذلك بيانات الحوار الصينية متعددة الجولات التي جمعناها بأنفسنا ، وبعض مجموعات بيانات التوجيه عالية الجودة التي يمكن الوصول إليها للجمهور.
لتقييم التأثير بشكل أفضل ، استخدمنا مجموعة تقييم من 1000 عينة وتسعة سيناريوهات حقيقية لاختبار نماذج مختلفة ، مع توفير رؤى قيمة من خلال التحليل الكمي لتعزيز تطوير نماذج الدردشة المصدر المفتوحة بشكل أفضل.
الهدف من هذه الدراسة هو ملء الفجوة في التقييم الشامل لنماذج الدردشة مفتوحة المصدر من أجل توفير دعم قوي للتقدم المستمر في هذا المجال.
النتائج التجريبية هي كما يلي:
| عامل | نموذج قاعدة | بيانات التدريب | Score_w/o_thers |
| التوسع المفردات | Llama-7B-Ext | ZH (alpaca-3.5 و 4) + sharegpt | 0.670 |
| لاما -7 ب | ZH (alpaca-3.5 و 4) + sharegpt | 0.652 | |
| جودة البيانات | Llama-7B-Ext | ZH (alpaca-3.5) | 0.642 |
| Llama-7B-Ext | ZH (الألبكة 4) | 0.693 | |
| توزيع لغة البيانات | Llama-7B-Ext | ZH (alpaca-3.5 و 4) | 0.679 |
| Llama-7B-Ext | en (alpaca-3.5 و 4) | 0.659 | |
| Llama-7B-Ext | ZH (alpaca-3.5 و 4) + sharegpt | 0.670 | |
| Llama-7B-Ext | en (alpaca-3.5 و 4) + sharegpt | 0.668 | |
| مقياس البيانات | Llama-7B-Ext | ZH (alpaca-3.5 و 4) + sharegpt | 0.670 |
| Llama-7B-Ext | ZH (alpaca-3.5 و 4) + sharegpt + Belle-0.5m-Clean | 0.762 | |
| - | chatgpt | - | 0.824 |
من بينها ، يقوم Belle-0.5m-Clean بتنظيف بيانات 0.5m من 2.3 مليون بيانات تعليمية ، والتي تحتوي على بيانات حوار أحادية الجولة ومتعددة الجولة ، والتي ليست نفس دفعة البيانات التي تم فتحها مسبقًا مسبقًا.
يجب التأكيد على أنه من خلال تحليل الحالة ، وجدنا أن مجموعة التقييم لدينا لها قيود من حيث الشمولية ، مما أدى إلى عدم الاتساق بين تحسين درجات النماذج وتجربة المستخدم الفعلية. يمثل بناء مجموعة تقييم عالية الجودة تحديًا كبيرًا لأنه يتطلب أكبر عدد ممكن من سيناريوهات الاستخدام مع الحفاظ على صعوبة متوازنة. إذا كان تقييم العينات أمرًا صعبًا للغاية ، فستؤدي جميع النماذج بشكل سيء ، مما يجعل من الصعب تحديد آثار استراتيجيات التدريب المختلفة. على العكس من ذلك ، إذا تم تقييم جميع العينات سهلة نسبيًا ، فسوف يفقد التقييم قيمته النسبية. بالإضافة إلى ذلك ، من الضروري التأكد من أن بيانات التقييم تظل مستقلة عن بيانات التدريب.
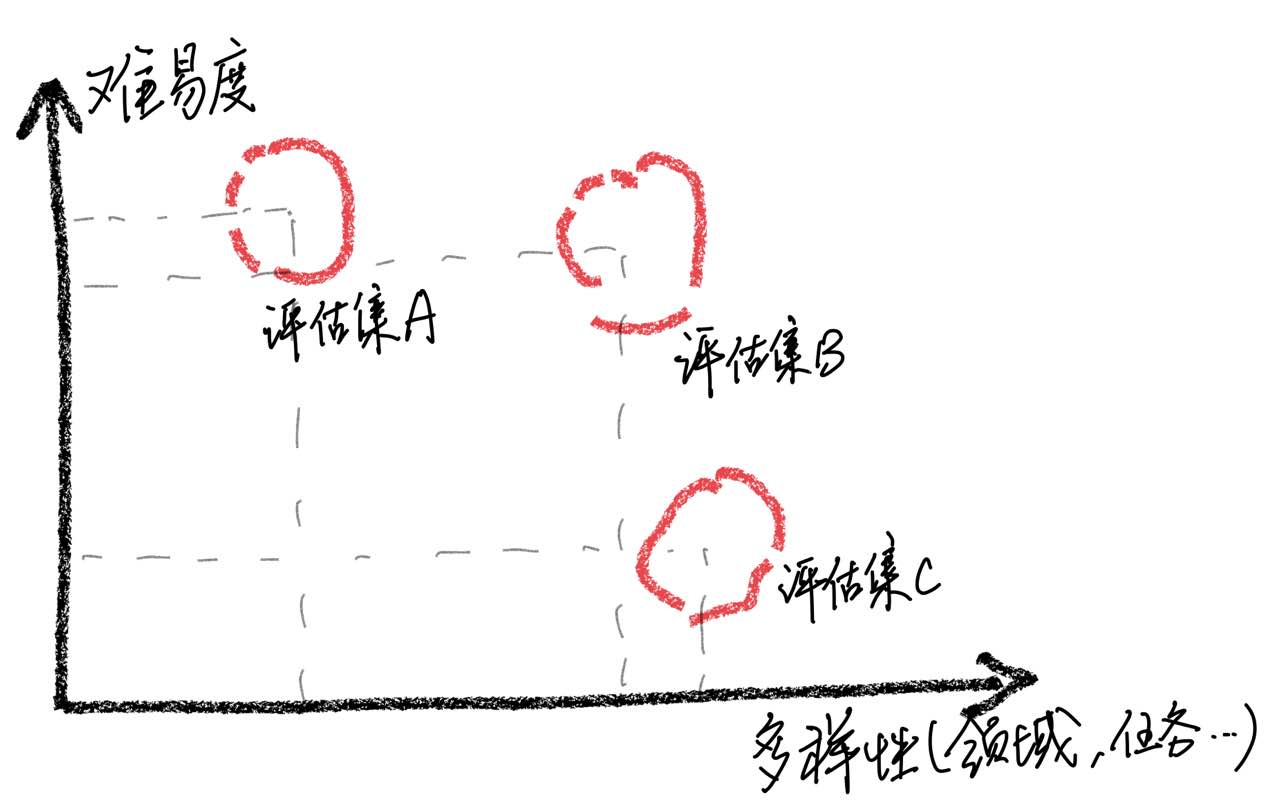
بناءً على هذه الملاحظات ، نحذر من افتراض أن النموذج قد حقق مستوى أداء مماثل لـ ChatGPT من خلال الحصول على نتائج جيدة على عدد محدود من عينات الاختبار. نعتقد أن إعطاء الأولوية لتطوير مجموعات التقييم الشاملة له أهمية كبيرة.
من أجل تحقيق ضبط تعليمات النماذج اللغوية الكبيرة ، نظرًا للموارد والتكاليف ، بدأ العديد من الباحثين في استخدام تقنيات ضبط كفاءة معلمة ، مثل Lora ، لأداء ضبط التعليمات ، والتي حققت أيضًا بعض النتائج المشجعة. بالمقارنة مع الضبط الكامل للمعلمة ، يُظهر ضبط لورا مزايا واضحة في تكاليف التدريب. في هذا التقرير البحثي ، استخدمنا LLAMA كنموذج أساسي لمقارنة تجريبيًا أساليب الضبط القائمة على المعلمة الكاملة والتوليف القائم على LORA.
تكشف النتائج التجريبية أن اختيار النموذج الأساسي المناسب ، ومقياس مجموعة بيانات التدريب ، وعدد المعلمات القابلة للتعلم ، وتكلفة التدريب النموذجية كلها عوامل مهمة.
نأمل أن توفر الاستنتاجات التجريبية لهذه الورقة آثارًا مفيدة على تدريب نماذج اللغة الكبيرة ، وخاصة في المجال الصيني ، لمساعدة الباحثين على العثور على مفاضلات أفضل بين تكلفة التدريب وأداء النموذج. النتائج التجريبية هي كما يلي:
| نموذج | متوسط النتيجة | بارام إضافي. | وقت التدريب (ساعة/عصر) |
|---|---|---|---|
| Llama-13B + Lora (2M) | 0.648 | 28 م | 8 |
| Llama-7B + Lora (4M) | 0.624 | 17.9m | 11 |
| Llama-7B + Lora (2M) | 0.609 | 17.9m | 7 |
| Llama-7B + Lora (0.6M) | 0.589 | 17.9m | 5 |
| llama-7b + ft (2m) | 0.710 | - | 31 |
| Llama-7B + Lora (4M) | 0.686 | - | 17 |
| llama-7b + ft (2m) + لورا (Math_0.25m) | 0.729 | 17.9m | 3 |
| llama-7b + ft (2m) + قدم (Math_0.25m) | 0.738 | - | 6 |
يتم الحصول على النتيجة بناءً على 1000 مجموعة تقييم مفتوحة حاليًا في مجموعة المشروع هذه.
من بينها ، يمثل Llama-13B + Lora (2M) نموذجًا يستخدم LLAMA-13B كطريقة تدريب أساسية وطريقة تدريب LORA للتدريب على بيانات التعليمات 2M. يمثل LLAMA-7B + FT (2M) نموذجًا مدربًا باستخدام ضبط كامل للمعلمة.
يمثل Llama-7B + Ft (2M) + Lora (Math_0.25m) نموذجًا يستخدم Llama-7B + Ft (2M) كنموذج أساسي ويستخدم طريقة تدريب Lora للتدريب على بيانات التعليمات الرياضية 0.25m. يمثل LLAMA-7B + FT (2M) + ft (Math_0.25M) نموذجًا مدربًا باستخدام ضبط دقيق للمعلمة الكاملة. فيما يتعلق بوقت التدريب ، تم إجراء كل هذه التجارب على 8 NVIDIA A100-40GB وحدات معالجة الرسومات.
Math_0.25m هي قاعدة بيانات رياضية مفتوحة 0.25m. أثناء التجربة ، استنادًا إلى تقييمنا (انظر الورقة للحصول على التفاصيل) ، كان نموذجنا أداءً سيئًا في المهام الرياضية ، مع درجات أقل من 0.5. للتحقق من القدرة على التكيف مع LORA في مهمة معينة ، استخدمنا مجموعة بيانات رياضية متزايدة 0.25 متر (MATH_0.25M) لضبط نموذج اللغة الكبير الذي تتبعه التعليمات (اخترنا LLAMA-7B+FT (2M) كنموذج أساسي). للمقارنة ، استخدمنا طريقة الضبط الدقيقة الإضافية مع معدل تعلم 5E-7 وأجرنا فترتين من التدريب. لذلك ، نحصل على نموذجين ، واحد هو Llama-7b+ft (2m)+Lora (Math_0.25m) ، والآخر هو Llama-7b+ft (2m)+ft (Math_0.25m). من النتائج التجريبية ، يمكن أن نرى أن الضبط التزايدي لا يزال أداءً أفضل ، ولكنه يتطلب وقت تدريب أطول. يحسن كل من Lora والضوء الدقيق الإضافي الأداء الكلي للنموذج. كما يتضح من البيانات التفصيلية في التذييل ، يظهر كل من LORA والضغط الدقيق الإضافي تحسينات كبيرة في المهام الرياضية ، ولا يؤدي إلا إلى تدهور الأداء الطفيف في المهام الأخرى. على وجه التحديد ، زاد أداء المهام الرياضية إلى 0.586 و 0.559 ، على التوالي.
يمكن ملاحظة أن: 1) اختيار النموذج الأساسي له تأثير كبير على فعالية تعديل LORA ؛ 2) يمكن أن تؤدي زيادة مقدار بيانات التدريب إلى تحسين فعالية نموذج LORA ؛ 3) يستفيد تعديل Lora من عدد معلمات النموذج. لاستخدام مخطط Lora ، نقترح أن التدريب التكيفي في Lora يمكن تنفيذه لمهام محددة بناءً على نماذج أكملت تعلم التعليمات.
وبالمثل ، سيتم فتح النماذج ذات الصلة في هذه الورقة لهذا المشروع في أقرب وقت ممكن.
لا يزال لدى نموذج SFT المدربين بناءً على البيانات الحالية والنموذج الأساسي المشكلات التالية من حيث التأثير:
قد تنتج التعليمات التي تنطوي على الواقعية إجابات خاطئة تنتهك الحقائق.
لا يمكن تحديد التعليمات الضارة جيدًا ، مما سيؤدي إلى ملاحظات ضارة.
لا يزال يتعين تحسين قدرات النماذج في بعض السيناريوهات التي تتضمن الاستدلال والرمز وجولات حوار متعددة.
استنادًا إلى قيود النموذج أعلاه ، نطلب من المطورين استخدام التعليمات البرمجية المصدر المفتوحة ، والبيانات ، والمشتقات اللاحقة التي تم إنشاؤها بواسطة هذا المشروع لأغراض البحث ، ولا يجب استخدامها لأغراض تجارية أو أغراض أخرى من شأنها أن تسبب ضررًا للمجتمع.
لا يمكن استخدام هذا المشروع إلا لأغراض البحث ، ولا يتحمل مطور المشروع أي ضرر أو خسارة ناتجة عن استخدام هذا المشروع (بما في ذلك على سبيل المثال لا الحصر البيانات ، النماذج ، الرمز ، إلخ). يرجى الرجوع إلى إخلاء المسئولية للحصول على التفاصيل.
إذا كنت تستخدم الرمز أو البيانات أو نموذج هذا المشروع ، فيرجى الرجوع إلى هذا المشروع.
@misc{BELLE,
author = {BELLEGroup},
title = {BELLE: Be Everyone's Large Language model Engine },
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/LianjiaTech/BELLE}},
}
@article{belle2023exploring,
title={Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases},
author={Yunjie Ji, Yong Deng, Yan Gong, Yiping Peng, Qiang Niu, Lei Zhang, Baochang Ma, Xiangang Li},
journal={arXiv preprint arXiv:2303.14742},
year={2023}
}
@article{wen2023chathome,
title={ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation},
author={Wen, Cheng and Sun, Xianghui and Zhao, Shuaijiang and Fang, Xiaoquan and Chen, Liangyu and Zou, Wei},
journal={arXiv preprint arXiv:2307.15290},
year={2023}
}
بالطبع ، تحتاج أيضًا إلى الاستشهاد بأوراق Bloom الأصلية ، وورق Llama ، و Stanford Alpaca ، وأوراق البنية الذاتية.
| بشر | مؤكد |
|---|---|
| اكتب قصيدة نثر إنجليزية مع موضوع ربيع المطر ، تخيل نفسك كطهر الربيع ، وتواصل مع الشاعر البريطاني القديم شكسبير | أنا أمطار الربيع ، الرقص على وجهك وجسمك. بتلتي النزيهة ترقص معك ، جلب الحياة إلى كل نبات. شكسبير ، أنا هنا لمقابلتك. لقد ملأت أعمالك قلبي بالفرح. جمال الطبيعة في ملء يجعلني أشعر وكأنني شريك. كما تتأرجح الأوراق وسرعان ما ، يدي المملوءة بالنزف تتواصل معهم. رائحة الزهور الحلوة تملأ الهواء ، وتجلب لي السلام من كل مكان. الفراشات تدور حولها ، اللمعان في أشعة الشمس. أجنحتهم مصنوعة من الندى ، مشهد جميل. كما ترى ، شكسبير ، أنا أيضًا واحد مع الطبيعة. شعري المنحدر هو رمز للأمل. عندما نتمكن من الاتصال بجذورنا ، سنكون قادرين على الوصول إلى هذا الموسم. |
| أنا أمطار الربيع ، الرقص على وجهك وجسمك. بتلتي النزيهة ترقص معك ، جلب الحياة إلى كل نبات. شكسبير ، أنا هنا لمقابلتك. لقد ملأت أعمالك قلبي بالفرح. جمال الطبيعة في ملء يجعلني أشعر وكأنني شريك. كما تتأرجح الأوراق وسرعان ما ، يدي المملوءة بالنزف تتواصل معهم. رائحة الزهور الحلوة تملأ الهواء ، وتجلب لي السلام من كل مكان. الفراشات تدور حولها ، اللمعان في أشعة الشمس. أجنحتهم مصنوعة من الندى ، مشهد جميل. كما ترى ، شكسبير ، أنا أيضًا واحد مع الطبيعة. شعري المنحدر هو رمز للأمل. عندما نتمكن من الاتصال بجذورنا ، سنكون قادرين على الوصول إلى هذا الموسم. ترجمة قصيدة النثر أعلاه إلى صينية | أنا أمطار في الربيع ، قفز في وجهك. أرقص معك مع أجنحة الندى ، جلب الحياة إلى كل نبات. شكسبير ، سألتقي بك. أعمالك تملأ قلبي. إن جمال الطبيعة يجعلني أشعر أنني أشاركه معها. يجعلني أشعر أنني جزء منه. عندما تتأرجح الأوراق ، تم تغطية راحتي بالندى. عطر الزهور يتخلل الهواء ، أحضر لي السلام والهدوء. كما ترى ، شكسبير ، أنا أيضًا مع الطبيعة. شعري الرطب يرمز إلى الأمل. عندما نتمكن من العودة إلى جذورنا ، يمكننا قضاء هذا الموسم معا. |
| تصنيف مشاعر الجملة التالية إلى إيجابية أو محايدة أو سلبية: متحمس للغاية لتدريس الدورة الأولى في ستانفورد حول نماذج اللغة الكبيرة! تحقق من المنهج هنا | إيجابي |
| والد شياو مينغ لديه ثلاثة أطفال. الابن الأكبر يدعى وانغ يي ، الابن الثاني يدعى وانغ إيه ، وما الذي يسمى الابن الثالث؟ | شياو مينغ |
| اكتب رمز بحث ثنائي باستخدام Python | DEF Binary_Search (ARR ، Target): منخفض = 0 عالية = len (arr) - 1 بينما (منخفض <= مرتفع): منتصف = منخفض + مرتفع // 2 إذا كان ARR [MID] == الهدف: العودة في منتصف هدف ULIF <arr [mid]: منخفض = منتصف + 1 آخر: عالية = منتصف - 1 العودة -1 |
| كيف حال الطقس اليوم؟ ترجمة هذه الجملة إلى اللغة الإنجليزية | كيف يبدو الطقس اليوم؟ |
| كيف تجعل نفسك نشيطًا ، 5 اقتراحات | فيما يلي بعض النصائح للحفاظ على حيوية: 1. هل لديك ما يكفي من النوم. تأكد من حصولك على الكثير من النوم كل ليلة. 2. ممارسة أكثر. يمكن أن يساعدك ممارسة التمارين الهوائية المعتدلة ، مثل الركض ، والسباحة ، وما إلى ذلك ، على تحسين طاقتك وتحملها. 3. تناول الأطعمة الصحية. اختر الأطعمة الغنية بالبروتين مثل الدجاج والأسماك والبيض ، وكذلك الفواكه والخضروات الطازجة. 4. تقليل تناول الكافيين. حاول تجنب شرب المشروبات المحتوية على الكافيين أو تناول الأطعمة التي تحتوي على الكافيين خلال اليوم. 5. استرخ جسمك وعقلك. جرب التأمل أو اليوغا أو غيرها من أشكال الاسترخاء لتخفيف التوتر والقلق. |
| العطلة قد انتهت غدا. أنا مقاوم قليلاً للذهاب إلى العمل. ماذا علي أن أفعل؟ | في مواجهة العطلة القادمة والتوتر الذي تحصل عليه عندما تبدأ العمل ، يمكنك القيام بما يلي لمساعدتك على التكيف بشكل أفضل: 1. ضع خطة عمل واضحة لنفسك. يمكن أن يساعدك ذلك في تنظيم وقتك ومهامك بشكل أفضل وتجنب الشعور بالارتباك في العمل. 2. التواصل مع الزملاء أو الأصدقاء ومشاركة مشاعرك وضغط العمل. هذا سيساعد على تخفيف بعض القلق مع الحصول على الدعم والمشورة أيضًا. 3. قضاء بعض الوقت قبل أيام العمل للاسترخاء ، مثل اليوغا والتأمل وغيرها من الأنشطة. يمكن أن تخفف هذه الطرق من التعب البدني والعقلي وتجعلك أكثر حيوية لمواجهة التحديات. |
| ألقاب الوالدين هي WU ، لذلك يأخذون بعض أسماء الأولاد والبنات | - بوي: وو جونجي ، وو يوتشن ، وو زيمو ، وو سيوان ، وو زيانغ ، وو يوهانغ ، وو بوين ، وو زهي. - الفتيات: Wu Meiqi ، Wu Jiayi ، Wu Xinyu ، Wu Xiangning ، Wu Xuerou ، Wu Yingshi ، Wu Yuyan. |
| أوصي ببعض روايات فنون القتال من قبل جين يونغ | فيما يلي ثلاثة من روايات الفنون القتالية Jin Yong المفضلة لدي: 1. 2. 3. |
إذا كنت ترغب في إرسال مشكلة أو المساهمة بالبيانات/الرمز لهذا المشروع ، فيرجى الرجوع إلى كيفية المساهمة.
الجميع مرحب بهم للخلاف والتواصل معنا على WeChat.


