BELLE
v0.95 发布
 Belle: Jadilah mesin model bahasa besar semua orang
Belle: Jadilah mesin model bahasa besar semua orangBaca ini dalam bahasa Inggris.
Tujuan dari proyek ini adalah untuk mempromosikan pengembangan dialog Tiongkok komunitas open source model open source, dan visinya adalah menjadi mesin LLM yang dapat membantu semua orang.
Dibandingkan dengan cara melakukan pra-pelatihan model bahasa besar, Belle lebih fokus pada cara membantu setiap orang mendapatkan model bahasa mereka sendiri, dengan efek terbaik dan kemampuan kinerja instruksi berdasarkan model bahasa pra-pelatihan open source, dan mengurangi ambang batas penelitian dan aplikasi model bahasa besar, terutama model bahasa besar dalam bahasa Cina. Untuk tujuan ini, proyek Belle akan terus membuka data pelatihan instruksi, model terkait, kode pelatihan, skenario aplikasi, dll., Dan akan terus mengevaluasi dampak data pelatihan yang berbeda, algoritma pelatihan, dll. Pada kinerja model. Belle telah dioptimalkan untuk Cina, dan model tuning hanya menggunakan data yang diproduksi oleh ChatGPT (tanpa data lain).
Gambar berikut adalah model Belle-7b yang dapat dijalankan 4bit kuantisasi secara lokal di sisi perangkat menggunakan aplikasi, dan berjalan secara real time pada M1 max CPU (tidak dipercepat). Untuk detail tentang unduhan aplikasi, silakan merujuk ke unduhan model pendukung aplikasi dan instruksi untuk digunakan. Tautan unduhan aplikasi saat ini hanya tersedia di versi Mac OS. Model perlu diunduh secara terpisah. Setelah model dikuantifikasi, efek kehilangannya jelas, dan kami akan terus mempelajari cara memperbaikinya.
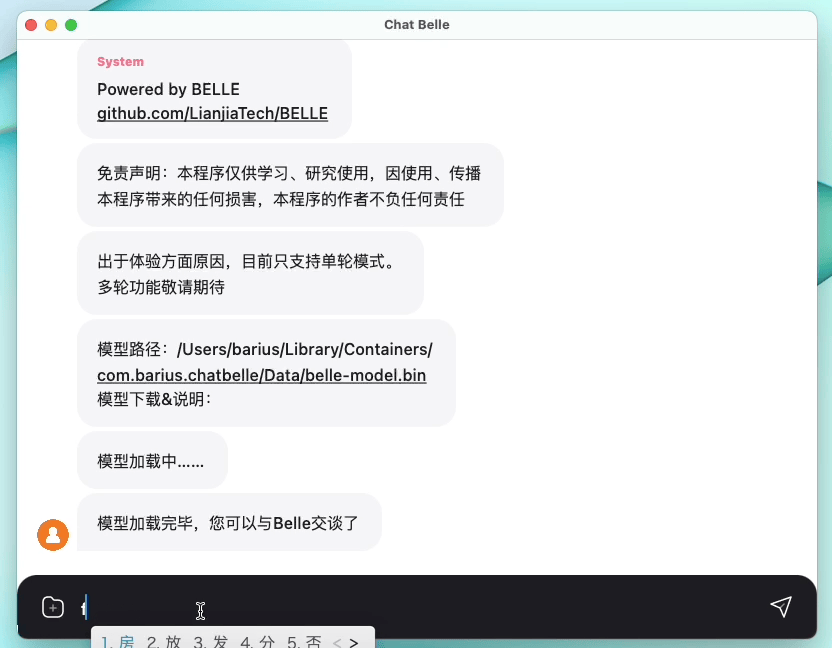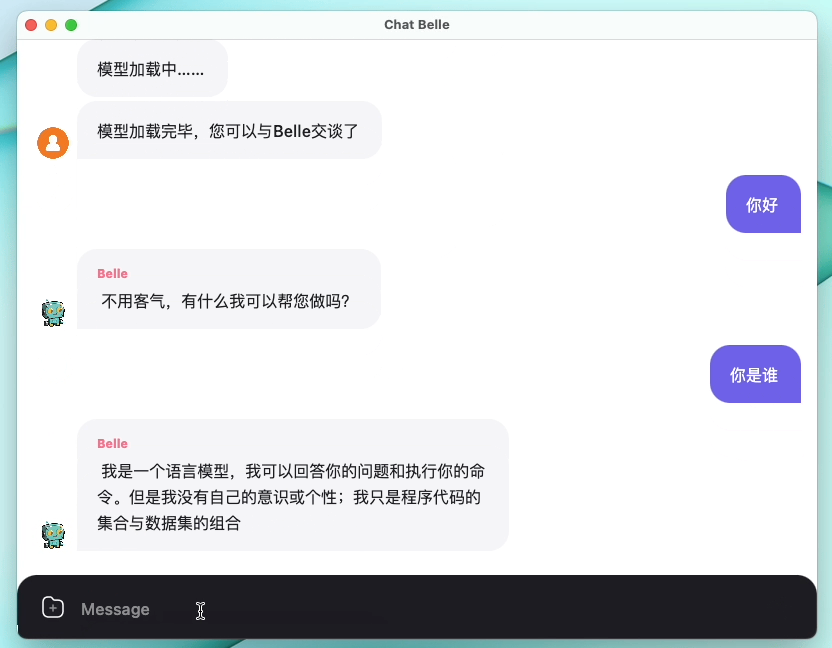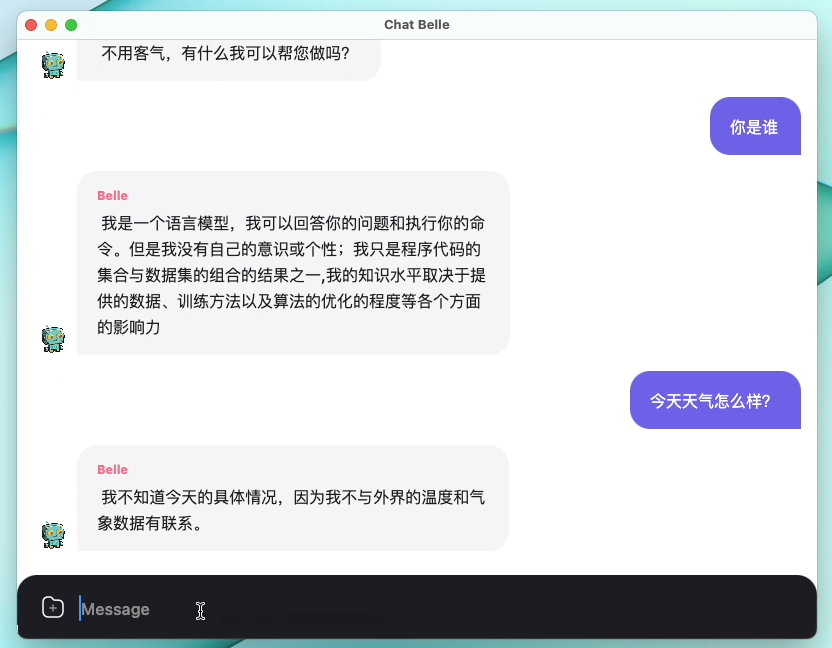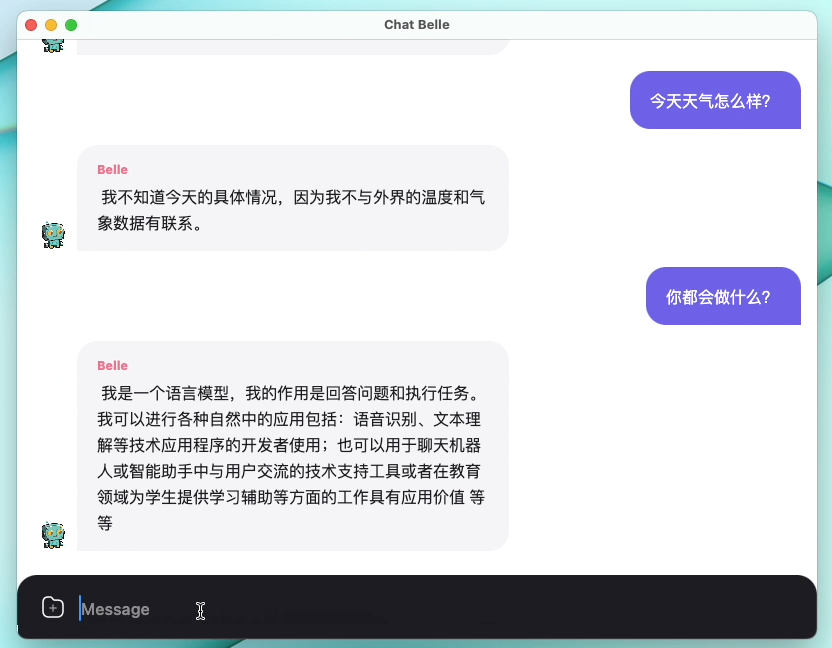
Lihat Belle/Train for Rincian, implementasi kode pelatihan yang disederhanakan mungkin, mengintegrasikan deep-cat, mendukung Finetune dan Lora, dan menyediakan buruh pelabuhan terkait.
Untuk detailnya, lihat Belle/Data/1,5m, lihat set data Cina yang dihasilkan oleh Stanford Alpaca 1M + 0,5m;
Kumpulan data yang terus terbuka, silakan merujuk ke Belle/Data/10m untuk detailnya.
Untuk detailnya, lihat Belle/Eval, set tes 1K+, dan prompt penilaian yang sesuai. Ini berisi beberapa kategori dan menggunakan GPT-4 atau ChatGPT untuk mencetak gol. Ini juga menyediakan halaman web penilaian agar mudah digunakan untuk satu case. Setiap orang dipersilakan untuk memberikan lebih banyak kasus tes melalui PR.
Lihat Belle/Model untuk detailnya
Model untuk penyetelan berdasarkan meta llama2: Belle-llama2-13b-chat-0.4m
Model yang mengimplementasikan tuning berdasarkan meta llama: Belle-llama-7b-0.6m-enc, Belle-llama-7b-2m-enc, Belle-llama-7b-2m-gptq-enc, belle-llama-3b-2-enc, yang didasarkan pada llama-llama-llama-llama, dan model yang dilatih-llama, dan model yang terlatih, dan model yang terlatih, dan model yang terlatih, dan model yang terlatih, dan model yang terlatih, dan model yang terlatih, dan model yang terlatih di Belle-On-On-On-Datasets.
Model dioptimalkan berdasarkan Bloomz-7b1-MT: Belle-7b-0.2m, Belle-7b-0.6m, Belle-7b-1m, Belle-7b-2m
Lihat Belle/GPTQ untuk detailnya. Lihat implementasi GPTQ untuk mengukur model yang relevan dalam proyek ini.
Memberikan kode inferensi runnable colab di colab
Untuk detailnya, lihat Belle/Chat, aplikasi Offline Cross-Platform Offline Bahasa Model Bahasa Berdasarkan Model Belle. Menggunakan model offline terkuantisasi dengan flutter, dapat berjalan pada macOS (didukung), Windows, Android, iOS dan perangkat lainnya.
Lihat Belle/Docs untuk detailnya, yang secara teratur akan memperbarui laporan penelitian yang terkait dengan proyek ini.
Selamat datang untuk menyumbangkan lebih banyak propt melalui masalah!
Untuk mempromosikan pengembangan model bahasa besar open source, kami telah menginvestasikan banyak energi untuk mengembangkan model berbiaya rendah yang dapat mirip dengan chatgpt. Pertama, untuk meningkatkan kinerja dan efisiensi pelatihan/inferensi model di bidang Cina, kami lebih lanjut memperluas kosa kata Llama dan melakukan pra-pelatihan sekunder pada 3,4 miliar kosakata Cina.
Selain itu, kita dapat melihat bahwa instruksi data terlatih yang dihasilkan berdasarkan chatgpt adalah: 1) merujuk pada data instruksi mandiri yang diperoleh berdasarkan GPT3.5 oleh Alpaca; 2) merujuk pada data instruksi-diri yang diperoleh berdasarkan GPT4 oleh Alpaca; 3) Data Sharegpt yang dibagikan oleh pengguna yang menggunakan chatgpt. Di sini, kami fokus untuk mengeksplorasi dampak kategori data pelatihan pada kinerja model. Secara khusus, kami memeriksa faktor-faktor seperti kuantitas, kualitas, dan distribusi bahasa data pelatihan, serta data dialog multi-putaran Cina yang kami kumpulkan sendiri, dan beberapa set data panduan berkualitas tinggi yang dapat diakses secara publik.
Untuk mengevaluasi efek dengan lebih baik, kami menggunakan set evaluasi 1.000 sampel dan sembilan skenario nyata untuk menguji berbagai model, sambil memberikan wawasan yang berharga melalui analisis kuantitatif untuk lebih mempromosikan pengembangan model obrolan sumber terbuka.
Tujuan dari penelitian ini adalah untuk mengisi kesenjangan dalam evaluasi komprehensif model obrolan open source untuk memberikan dukungan kuat untuk kemajuan berkelanjutan di bidang ini.
Hasil eksperimen adalah sebagai berikut:
| Faktor | Model dasar | Data pelatihan | Score_w/o_others |
| Ekspansi kosa kata | Llama-7b-ext | ZH (Alpaca-3.5 & 4) + Sharegpt | 0.670 |
| Llama-7b | ZH (Alpaca-3.5 & 4) + Sharegpt | 0.652 | |
| Kualitas Data | Llama-7b-ext | ZH (Alpaca-3.5) | 0.642 |
| Llama-7b-ext | ZH (Alpaca-4) | 0.693 | |
| Distribusi Bahasa Data | Llama-7b-ext | ZH (Alpaca-3.5 & 4) | 0.679 |
| Llama-7b-ext | EN (Alpaca-3.5 & 4) | 0.659 | |
| Llama-7b-ext | ZH (Alpaca-3.5 & 4) + Sharegpt | 0.670 | |
| Llama-7b-ext | EN (Alpaca-3.5 & 4) + Sharegpt | 0.668 | |
| Skala data | Llama-7b-ext | ZH (Alpaca-3.5 & 4) + Sharegpt | 0.670 |
| Llama-7b-ext | ZH (Alpaca-3.5 & 4) + Sharegpt + Belle-0.5m-Clean | 0.762 | |
| - | Chatgpt | - | 0.824 |
Di antara mereka, Belle-0.5m-Clean membersihkan data 0,5m dari 2,3 juta data instruksi, yang berisi data dialog putaran tunggal dan ganda, yang bukan batch data yang sama dengan data 0,5m yang sebelumnya dibuka.
Harus ditekankan bahwa melalui analisis kasus, kami menemukan bahwa set evaluasi kami memiliki keterbatasan dalam hal kelengkapan, yang menyebabkan ketidakkonsistenan antara peningkatan skor model dan pengalaman pengguna yang sebenarnya. Membangun set evaluasi berkualitas tinggi adalah tantangan besar karena membutuhkan sebanyak mungkin skenario penggunaan sambil mempertahankan kesulitan yang seimbang. Jika mengevaluasi sampel sebagian besar terlalu sulit, semua model akan berkinerja buruk, membuatnya menantang untuk mengidentifikasi efek dari berbagai strategi pelatihan. Sebaliknya, jika semua sampel dievaluasi relatif mudah, evaluasi akan kehilangan nilai komparatifnya. Selain itu, perlu untuk memastikan bahwa data evaluasi tetap independen dari data pelatihan.
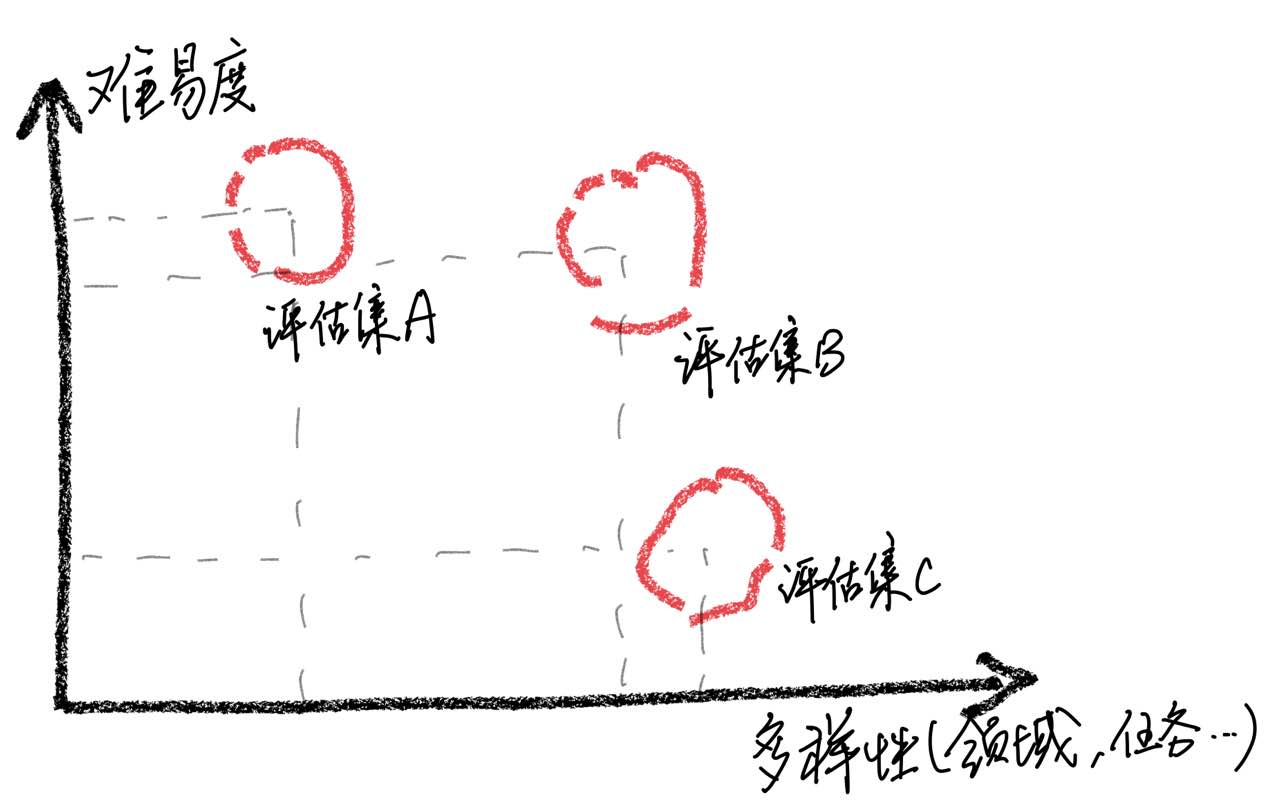
Berdasarkan pengamatan ini, kami berhati -hati terhadap asumsi bahwa model telah mencapai tingkat kinerja yang sebanding dengan chatgpt dengan hanya mendapatkan hasil yang baik pada sejumlah sampel uji yang terbatas. Kami percaya bahwa memprioritaskan pengembangan set penilaian komprehensif sangat penting.
Untuk mencapai penyetelan instruksi model bahasa besar, karena sumber daya dan biaya, banyak peneliti telah mulai menggunakan teknik penyetelan yang efisien parameter, seperti LORA, untuk melakukan penyetelan instruksi, yang juga telah mencapai beberapa hasil yang menggembirakan. Dibandingkan dengan penyempurnaan parameter penuh, tuning yang berbasis di Lora menunjukkan keunggulan yang jelas dalam biaya pelatihan. Dalam laporan penelitian ini, kami menggunakan LLAMA sebagai model dasar untuk secara eksperimental membandingkan metode penyesuaian parameter penuh dan metode tuning berbasis LORA.
Hasil eksperimen mengungkapkan bahwa pemilihan model dasar yang sesuai, skala kumpulan data pelatihan, jumlah parameter yang dapat dipelajari, dan biaya pelatihan model adalah semua faktor penting.
Kami berharap bahwa kesimpulan eksperimental dari makalah ini dapat memberikan implikasi yang berguna untuk pelatihan model bahasa besar, terutama di bidang Cina, untuk membantu para peneliti menemukan pertukaran yang lebih baik antara biaya pelatihan dan kinerja model. Hasil eksperimen adalah sebagai berikut:
| Model | Skor rata -rata | Param tambahan. | Waktu pelatihan (jam/zaman) |
|---|---|---|---|
| Llama-13b + lora (2m) | 0.648 | 28m | 8 |
| Llama-7b + lora (4m) | 0.624 | 17.9m | 11 |
| Llama-7b + lora (2m) | 0.609 | 17.9m | 7 |
| Llama-7b + lora (0,6m) | 0,589 | 17.9m | 5 |
| Llama-7b + ft (2m) | 0.710 | - | 31 |
| Llama-7b + lora (4m) | 0.686 | - | 17 |
| Llama-7b + ft (2m) + Lora (Math_0.25m) | 0.729 | 17.9m | 3 |
| Llama-7b + ft (2m) + Ft (Math_0.25m) | 0.738 | - | 6 |
Skor diperoleh berdasarkan 1.000 set evaluasi yang saat ini terbuka di set proyek ini.
Di antara mereka, LLAMA-13B + LORA (2M) mewakili model yang menggunakan LLAMA-13B sebagai model dasar dan metode pelatihan LORA untuk melatih data instruksi 2M. LLAMA-7B + FT (2M) mewakili model yang dilatih menggunakan penyempurnaan parameter penuh.
LLAMA-7B + FT (2M) + LORA (Math_0.25m) mewakili model yang menggunakan LLAMA-7B + FT (2M) sebagai model dasar dan menggunakan metode pelatihan LORA untuk pelatihan pada data instruksi matematika 0,25m. Llama-7b + ft (2m) + ft (math_0.25m) mewakili model yang dilatih menggunakan penyempurnaan parameter penuh tambahan. Mengenai waktu pelatihan, semua percobaan ini dilakukan pada 8 NVIDIA A100-40GB GPU.
MATH_0.25M adalah database matematika 0,25m terbuka. Selama percobaan, berdasarkan evaluasi kami (lihat makalah untuk detail), model kami berkinerja buruk pada tugas matematika, dengan skor sebagian besar di bawah 0,5. Untuk memverifikasi kemampuan beradaptasi Lora pada tugas tertentu, kami menggunakan dataset matematika 0,25m tambahan (Math_0.25m) untuk menyesuaikan model bahasa besar yang diikuti oleh instruksi (kami memilih LLAMA-7B+FT (2M) sebagai model dasar). Sebagai perbandingan, kami menggunakan metode penyempurnaan tambahan dengan tingkat pembelajaran 5E-7 dan melakukan 2 periode pelatihan. Oleh karena itu, kami mendapatkan dua model, satu adalah Llama-7b+ft (2m)+lora (Math_0.25m), dan yang lainnya adalah Llama-7b+ft (2m)+ft (Math_0.25m). Dari hasil eksperimen, dapat dilihat bahwa penyempurnaan tambahan masih berkinerja lebih baik, tetapi membutuhkan waktu pelatihan yang lebih lama. Baik Lora dan penyempurnaan tambahan meningkatkan kinerja keseluruhan model. Seperti yang dapat dilihat dari data terperinci dalam lampiran, baik Lora dan penyempurnaan tambahan menunjukkan peningkatan yang signifikan dalam tugas matematika, dan hanya menyebabkan sedikit degradasi kinerja dalam tugas lain. Secara khusus, kinerja tugas matematika meningkat menjadi 0,586 dan 0,559, masing -masing.
Dapat dilihat bahwa: 1) Memilih model dasar memiliki dampak yang signifikan pada efektivitas penyesuaian LORA; 2) meningkatkan jumlah data pelatihan dapat terus meningkatkan efektivitas model LORA; 3) Manfaat penyesuaian LORA dari jumlah parameter model. Untuk penggunaan skema LORA, kami menyarankan bahwa pelatihan adaptif LORA dapat dilakukan untuk tugas -tugas tertentu berdasarkan model yang telah menyelesaikan pembelajaran instruksi.
Demikian pula, model yang relevan dalam makalah ini akan dibuka untuk proyek ini sesegera mungkin.
Model SFT yang dilatih berdasarkan data saat ini dan model dasar masih memiliki masalah berikut dalam hal efek:
Instruksi yang melibatkan faktualitas dapat menghasilkan jawaban palsu yang melanggar fakta.
Instruksi berbahaya tidak dapat diidentifikasi dengan baik, yang akan mengarah pada komentar berbahaya.
Kemampuan model masih perlu ditingkatkan dalam beberapa skenario yang melibatkan inferensi, kode, dan beberapa putaran dialog.
Berdasarkan keterbatasan model di atas, kami mengharuskan pengembang untuk menggunakan kode open source kami, data, model dan turunan selanjutnya yang dihasilkan oleh proyek ini untuk tujuan penelitian, dan tidak boleh digunakan untuk tujuan komersial atau tujuan lain yang akan menyebabkan kerusakan pada masyarakat.
Proyek ini hanya dapat digunakan untuk tujuan penelitian, dan pengembang proyek tidak menanggung kerusakan atau kerugian yang disebabkan oleh penggunaan proyek ini (termasuk tetapi tidak terbatas pada data, model, kode, dll.). Silakan merujuk ke penafian untuk detailnya.
Jika Anda menggunakan kode, data, atau model proyek ini, silakan merujuk ke proyek ini.
@misc{BELLE,
author = {BELLEGroup},
title = {BELLE: Be Everyone's Large Language model Engine },
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/LianjiaTech/BELLE}},
}
@article{belle2023exploring,
title={Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases},
author={Yunjie Ji, Yong Deng, Yan Gong, Yiping Peng, Qiang Niu, Lei Zhang, Baochang Ma, Xiangang Li},
journal={arXiv preprint arXiv:2303.14742},
year={2023}
}
@article{wen2023chathome,
title={ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation},
author={Wen, Cheng and Sun, Xianghui and Zhao, Shuaijiang and Fang, Xiaoquan and Chen, Liangyu and Zou, Wei},
journal={arXiv preprint arXiv:2307.15290},
year={2023}
}
Tentu saja, Anda juga perlu mengutip makalah mekar asli, Llama Papers, Stanford Alpaca dan kertas-kertas mandiri.
| Manusia | Assitan |
|---|---|
| Tulis puisi prosa bahasa Inggris dengan tema hujan musim semi, bayangkan diri Anda sebagai hujan musim semi, dan berkomunikasi dengan penyair Inggris kuno Shakespeare | Saya hujan musim semi, Menari di wajah dan tubuh Anda. Kelopakku yang bermandikan embun menari denganmu, Membawa kehidupan ke setiap tanaman. Shakespeare, aku di sini untuk bertemu denganmu. Pekerjaan Anda telah memenuhi hati saya dengan gembira. Keindahan alam dalam kepenuhannya Membuat saya merasa seperti pengikut. Saat daun bergoyang dan gemerisik, Tangan saya yang diisi embun meraih mereka. Aroma bunga yang manis memenuhi udara, Dan bawakan aku kedamaian dari sekitar. Kupu -kupu melayang di sekitar, Berkilau di sinar matahari. Sayap mereka terbuat dari embun, Pemandangan yang indah untuk dilihat. Anda lihat, Shakespeare, saya juga satu dengan alam. Rambut saya yang bermandikan embun adalah simbol harapan. Karena saat kita dapat terhubung kembali ke akar kita, Kami akan dapat melewati musim ini. |
| Saya hujan musim semi, Menari di wajah dan tubuh Anda. Kelopakku yang bermandikan embun menari denganmu, Membawa kehidupan ke setiap tanaman. Shakespeare, aku di sini untuk bertemu denganmu. Pekerjaan Anda telah memenuhi hati saya dengan gembira. Keindahan alam dalam kepenuhannya Membuat saya merasa seperti pengikut. Saat daun bergoyang dan gemerisik, Tangan saya yang diisi embun meraih mereka. Aroma bunga yang manis memenuhi udara, Dan bawakan aku kedamaian dari sekitar. Kupu -kupu melayang di sekitar, Berkilau di sinar matahari. Sayap mereka terbuat dari embun, Pemandangan yang indah untuk dilihat. Anda lihat, Shakespeare, saya juga satu dengan alam. Rambut saya yang bermandikan embun adalah simbol harapan. Karena saat kita dapat terhubung kembali ke akar kita, Kami akan dapat melewati musim ini. Menerjemahkan puisi prosa di atas ke dalam bahasa Cina | Saya hujan musim semi, Melompat ke wajah Anda. Aku berdansa denganmu dengan sayap embunku, Bawa kehidupan ke setiap tanaman. Shakespeare, aku akan bertemu denganmu. Pekerjaan Anda memenuhi hatiku. Keindahan alam membuat saya merasa ingin membaginya dengan itu. Itu membuat saya merasa seperti saya menjadi bagian dari itu. Saat daun bergoyang, Telapak tangan saya ditutupi dengan embun. Aroma bunga meresap di udara, Bawakan aku kedamaian dan ketenangan. Anda lihat, Shakespeare, saya juga satu dengan alam. Rambut saya yang basah melambangkan harapan. Ketika kita bisa kembali ke akar kita, Kita bisa menghabiskan musim ini bersama. |
| Klasifikasi sentimen dari kalimat berikut menjadi positif, netral, atau negatif: Sangat bersemangat tentang mengajar kursus pertama Stanford tentang model bahasa besar! Periksa silabusnya di sini | Positif |
| Ayah Xiao Ming memiliki tiga anak. Putra tertua bernama Wang Yi, putra kedua bernama Wang er, dan apa yang disebut putra ketiga? | Xiao Ming |
| Tulis kode pencarian biner menggunakan python | DEF BINARY_SEARCH (ARR, Target): rendah = 0 tinggi = len (arr) - 1 Sementara (rendah <= tinggi): mid = rendah + tinggi // 2 Jika ARR [mid] == Target: Kembali pertengahan Elif Target <arr [mid]: rendah = mid + 1 kalau tidak: tinggi = mid - 1 kembali -1 |
| Bagaimana cuaca hari ini? Menerjemahkan kalimat ini ke dalam bahasa Inggris | Seperti apa cuaca hari ini? |
| Bagaimana membuat diri Anda energik, 5 saran | Berikut beberapa tips untuk membuat Anda tetap energik: 1. Cukup tidur. Pastikan Anda banyak tidur setiap malam. 2. Latihan lebih banyak. Melakukan latihan aerobik sedang, seperti jogging, berenang, dll., Dapat membantu Anda meningkatkan energi dan daya tahan Anda. 3. Makan makanan sehat. Pilih makanan kaya protein seperti ayam, ikan dan telur, serta buah-buahan dan sayuran segar. 4. Kurangi asupan kafein. Cobalah untuk menghindari minum minuman yang mengandung kafein atau makan makanan yang mengandung kafein di siang hari. 5. Rilekskan tubuh dan pikiran Anda. Cobalah meditasi, yoga, atau bentuk relaksasi lainnya untuk menghilangkan stres dan kecemasan. |
| Liburan sudah berakhir besok. Saya sedikit menolak untuk pergi bekerja. Apa yang harus saya lakukan? | Dihadapkan dengan liburan yang akan datang dan ketegangan yang Anda dapatkan saat mulai bekerja, Anda dapat melakukan hal berikut untuk membantu Anda beradaptasi dengan lebih baik: 1. Buatlah rencana kerja yang jelas untuk diri Anda sendiri. Ini dapat membantu Anda mengatur waktu dan tugas Anda dengan lebih baik dan menghindari merasa bingung di tempat kerja. 2. Berkomunikasi dengan kolega atau teman dan bagikan perasaan dan tekanan kerja Anda. Ini akan membantu meringankan kecemasan sambil juga mendapatkan dukungan dan nasihat. 3. Luangkan waktu sebelum hari kerja untuk bersantai, seperti yoga, meditasi dan kegiatan lainnya. Metode -metode ini dapat meringankan kelelahan fisik dan mental dan membuat Anda lebih energik untuk memenuhi tantangan. |
| Nama keluarga kedua orang tua adalah Wu, jadi mereka mengambil beberapa nama anak laki -laki dan perempuan | - Boy: Wu Junjie, Wu Yuchen, Wu Zimo, Wu Siyuan, Wu Zeyang, Wu Yuhang, Wu Bowen, Wu Zheyi. - Girls: Wu Meiqi, Wu Jiayi, Wu Xinyu, Wu Xiangning, Wu Xuerou, Wu Yingshi, Wu Yuyan. |
| Rekomendasikan beberapa novel seni bela diri oleh Jin Yong | Berikut adalah tiga novel seni bela diri Jin Yong favorit saya: 1. "The Legend of the Condor Heroes" - novel yang penuh dengan kebijaksanaan dan kecerdasan, menceritakan kisah Guo Jing dan Huang Rong. 2. "The Return of the Condor Heroes" - Ini adalah kisah yang romantis dan menyentuh, menceritakan kisah cinta antara pasangan Xiaolongnu dan Yang Guo. 3. "The Legend of the Condor Heroes" - Ini adalah kisah yang luar biasa dan spektakuler yang menggambarkan bagaimana pemimpin kultus Ming Zhang Wuji menjadi pahlawan yang luar biasa. |
Jika Anda ingin mengirimkan masalah atau berkontribusi data/kode untuk proyek ini, silakan merujuk pada cara berkontribusi.
Setiap orang dipersilakan untuk menyangkal dan berkomunikasi dengan kami di WeChat.


