ChatGLM Finetuning
v0.1
本項目主要針對ChatGLM、ChatGLM2和ChatGLM3模型進行不同方式的微調(Freeze方法、Lora方法、P-Tuning方法、全量參數等),並對比大模型在不同微調方法上的效果,主要針對信息抽取任務、生成任務、分類任務等。
本項目支持單卡訓練&多卡訓練,由於採用單指令集方式微調,模型微調之後並沒有出現嚴重的災難性遺忘。
由於官方代碼和模型一直在更新,目前ChatGLM1和2的代碼和模型的為20230806版本(注意如果發現代碼運行有誤,可將ChatGLM相關源碼替換文件中的py文件,因為可能你下的模型版本與本項目代碼版本不一致),ChatGLM3是版本20231212。
PS:沒有用Trainer(雖然Trainer代碼簡單,但不易修改,大模型時代算法工程師本就成為了數據工程師,因此更需了解訓練流程)
模型微調時,如果遇到顯存不夠的情況,可以開啟gradient_checkpointing、zero3、offload等參數來節省顯存。
下面model_name_or_path參數為模型路徑,請根據可根據自己實際模型保存地址進行修改。
Freeze方法,即參數凍結,對原始模型部分參數進行凍結操作,僅訓練部分參數,以達到在單卡或多卡,不進行TP或PP操作就可以對大模型進行訓練。
微調代碼,見train.py,核心部分如下:
freeze_module_name = args . freeze_module_name . split ( "," )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in freeze_module_name ):
param . requires_grad = False針對模型不同層進行修改,可以自行修改freeze_module_name參數配置,例如"layers.27.,layers.26.,layers.25.,layers.24."。 訓練代碼均採用DeepSpeed進行訓練,可設置參數包含train_path、model_name_or_path、mode、train_type、freeze_module_name、ds_file、num_train_epochs、per_device_train_batch_size、gradient_accumulation_steps、output_dir等, 可根據自己的任務配置。
ChatGLM單卡訓練
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGLM四卡訓練,通過CUDA_VISIBLE_DEVICES控制具體哪幾塊卡進行訓練,如果不加該參數,表示使用運行機器上所有卡進行訓練
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGLM2單卡訓練
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGLM2四卡訓練,通過CUDA_VISIBLE_DEVICES控制具體哪幾塊卡進行訓練,如果不加該參數,表示使用運行機器上所有卡進行訓練
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGLM3單卡訓練
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
ChatGLM3四卡訓練,通過CUDA_VISIBLE_DEVICES控制具體哪幾塊卡進行訓練,如果不加該參數,表示使用運行機器上所有卡進行訓練
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS:ChatGLM微調時所用顯存要比ChatGLM2多,詳細顯存佔比如下:
| Model | DeepSpeed-Stage | Offload | Gradient Checkpointing | Batch Size | Max Length | GPU-A40 Number | 所耗顯存 |
|---|---|---|---|---|---|---|---|
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 1 | 36G |
| ChaGLM | zero2 | No | No | 1 | 1560 | 1 | 38G |
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 4 | 24G |
| ChaGLM | zero2 | No | No | 1 | 1560 | 4 | 29G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 1 | 35G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 1 | 36G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 4 | 22G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 4 | 27G |
PT方法,即P-Tuning方法,參考ChatGLM官方代碼,是一種針對於大模型的soft-prompt方法。
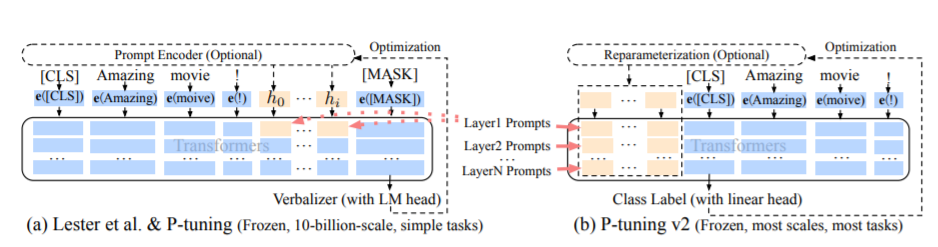
微調代碼,見train.py,核心部分如下:
config = MODE [ args . mode ][ "config" ]. from_pretrained ( args . model_name_or_path )
config . pre_seq_len = args . pre_seq_len
config . prefix_projection = args . prefix_projection
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path , config = config )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in [ "prefix_encoder" ]):
param . requires_grad = False當prefix_projection為True時,為P-Tuning-V2方法,在大模型的Embedding和每一層前都加上新的參數;為False時,為P-Tuning方法,僅在大模型的Embedding上新的參數。
訓練代碼均採用DeepSpeed進行訓練,可設置參數包含train_path、model_name_or_path、mode、train_type、pre_seq_len、prefix_projection、ds_file、num_train_epochs、per_device_train_batch_size、gradient_accumulation_steps、output_dir等, 可根據自己的任務配置。
ChatGLM單卡訓練
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 768
--max_src_len 512
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
ChatGLM四卡訓練,通過CUDA_VISIBLE_DEVICES控制具體哪幾塊卡進行訓練,如果不加該參數,表示使用運行機器上所有卡進行訓練
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
ChatGLM2單卡訓練
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
ChatGLM2四卡訓練,通過CUDA_VISIBLE_DEVICES控制具體哪幾塊卡進行訓練,如果不加該參數,表示使用運行機器上所有卡進行訓練
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
ChatGLM3單卡訓練
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
ChatGLM3四卡訓練,通過CUDA_VISIBLE_DEVICES控制具體哪幾塊卡進行訓練,如果不加該參數,表示使用運行機器上所有卡進行訓練
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
PS:ChatGLM微調時所用顯存要比ChatGLM2多,詳細顯存佔比如下:
| Model | DeepSpeed-Stage | Offload | Gradient Checkpointing | Batch Size | Max Length | GPU-A40 Number | 所耗顯存 |
|---|---|---|---|---|---|---|---|
| ChaGLM | zero2 | No | Yes | 1 | 768 | 1 | 43G |
| ChaGLM | zero2 | No | No | 1 | 300 | 1 | 44G |
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 4 | 37G |
| ChaGLM | zero2 | No | No | 1 | 1360 | 4 | 44G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 1 | 20G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 1 | 40G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 4 | 19G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 4 | 39G |
Lora方法,即在大型語言模型上對指定參數(權重矩陣)並行增加額外的低秩矩陣,並在模型訓練過程中,僅訓練額外增加的並行低秩矩陣的參數。 當“秩值”遠小於原始參數維度時,新增的低秩矩陣參數量也就很小。在下游任務tuning時,僅須訓練很小的參數,但能獲取較好的表現結果。
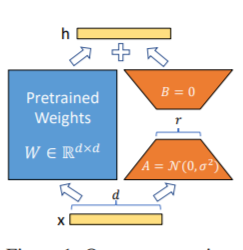
微調代碼,見train.py,核心部分如下:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )
lora_module_name = args . lora_module_name . split ( "," )
config = LoraConfig ( r = args . lora_dim ,
lora_alpha = args . lora_alpha ,
target_modules = lora_module_name ,
lora_dropout = args . lora_dropout ,
bias = "none" ,
task_type = "CAUSAL_LM" ,
inference_mode = False ,
)
model = get_peft_model ( model , config )
model . config . torch_dtype = torch . float32PS: Lora訓練之後,請先參數合併,在進行模型預測。
訓練代碼均採用DeepSpeed進行訓練,可設置參數包含train_path、model_name_or_path、mode、train_type、lora_dim、lora_alpha、lora_dropout、lora_module_name、ds_file、num_train_epochs、per_device_train_batch_size、gradient_accumulation_steps、output_dir等, 可根據自己的任務配置。
ChatGLM單卡訓練
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGLM四卡訓練,通過CUDA_VISIBLE_DEVICES控制具體哪幾塊卡進行訓練,如果不加該參數,表示使用運行機器上所有卡進行訓練
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGLM2單卡訓練
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGLM2四卡訓練,通過CUDA_VISIBLE_DEVICES控制具體哪幾塊卡進行訓練,如果不加該參數,表示使用運行機器上所有卡進行訓練
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGLM3單卡訓練
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
ChatGLM3四卡訓練,通過CUDA_VISIBLE_DEVICES控制具體哪幾塊卡進行訓練,如果不加該參數,表示使用運行機器上所有卡進行訓練
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS:ChatGLM微調時所用顯存要比ChatGLM2多,詳細顯存佔比如下:
| Model | DeepSpeed-Stage | Offload | Gradient Checkpointing | Batch Size | Max Length | GPU-A40 Number | 所耗顯存 |
|---|---|---|---|---|---|---|---|
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 1 | 20G |
| ChaGLM | zero2 | No | No | 1 | 1560 | 1 | 45G |
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 4 | 20G |
| ChaGLM | zero2 | No | No | 1 | 1560 | 4 | 45G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 1 | 20G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 1 | 43G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 4 | 19G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 4 | 42G |
注意:Lora方法在模型保存時僅保存了Lora訓練參數,因此在模型預測時需要將模型參數進行合併,具體參考merge_lora.py。
全參方法,對大模型進行全量參數訓練,主要藉助DeepSpeed-Zero3方法,對模型參數進行多卡分割,並藉助Offload方法,將優化器參數卸載到CPU上以解決顯卡不足問題。
微調代碼,見train.py,核心部分如下:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )訓練代碼均採用DeepSpeed進行訓練,可設置參數包含train_path、model_name_or_path、mode、train_type、ds_file、num_train_epochs、per_device_train_batch_size、gradient_accumulation_steps、output_dir等, 可根據自己的任務配置。
ChatGLM四卡訓練,通過CUDA_VISIBLE_DEVICES控制具體哪幾塊卡進行訓練,如果不加該參數,表示使用運行機器上所有卡進行訓練
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type all
--seed 1234
--ds_file ds_zero3_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGLM2四卡訓練,通過CUDA_VISIBLE_DEVICES控制具體哪幾塊卡進行訓練,如果不加該參數,表示使用運行機器上所有卡進行訓練
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGLM3四卡訓練,通過CUDA_VISIBLE_DEVICES控制具體哪幾塊卡進行訓練,如果不加該參數,表示使用運行機器上所有卡進行訓練
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS:ChatGLM微調時所用顯存要比ChatGLM2多,詳細顯存佔比如下:
| Model | DeepSpeed-Stage | Offload | Gradient Checkpointing | Batch Size | Max Length | GPU-A40 Number | 所耗顯存 |
|---|---|---|---|---|---|---|---|
| ChaGLM | zero3 | Yes | Yes | 1 | 1560 | 4 | 33G |
| ChaGLM2 | zero3 | No | Yes | 1 | 1560 | 4 | 44G |
| ChaGLM2 | zero3 | Yes | Yes | 1 | 1560 | 4 | 26G |
後面補充DeepSpeed的Zero-Stage的相關內容說明。
查看requirements.txt文件
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为"性能故障", "部件故障", "组成"和 "检测工具"的相关三元组,三元组内部用"_"连接,三元组之间用\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高n风扇_部件故障_低速转动"
}
| 微調方法 | PT-Only-Embedding | PT | Freeze | Lora |
|---|---|---|---|---|
| 測試結果F1 | 0.0 | 0.6283 | 0.5675 | 0.5359 |
結構分析:
很多同學在微調後出現了災難性遺忘現象,但本項目的訓練代碼並沒有出現,對“翻譯任務”、“代碼任務”、“問答任務”進行測試,具體測試效果如下:


{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
由於生成模型的內容不能想信息抽取任務一樣評價,用現有的BLUE或者Rouge來評價也是不合適,因此制定了評分規則。 通過多樣性和準確性兩個角度判斷D2Q模型好壞,每個樣本總計5分,共20個樣本。
| 微調方法 | 原始模型 | PT-Only-Embedding | PT | Freeze | Lora |
|---|---|---|---|---|---|
| 分數 | 51.75 | 73.75 | 87.75 | 79.25 | 86.75 |
代碼說明見:大模型流水線並行(Pipeline)實戰
請看v0.1 Tag


