ChatGLM Finetuning
v0.1
このプロジェクトは、主にCHATGLM、CHATGLM2、CHATGLM3モデルのさまざまな方法(フリーズメソッド、LORAメソッド、P調整方法、完全なパラメーターなど)で微調整を実行し、主に情報抽出タスク、世代のタスク、分類などをターゲットにしたさまざまな微調整方法に対する大きなモデルの効果を比較します。
このプロジェクトは、シングルカードトレーニングと複数カードトレーニングをサポートしています。単一の命令セットの微調整により、モデルの微調整後、深刻な壊滅的な忘却はありません。
公式コードとモデルが更新されているため、ChatGlm1と2の現在のコードとモデルはバージョン20230806です(コードが誤って実行されている場合、ファイルのPyファイルをChatGlm関連のソースコードに置き換えることができることに注意してください。 chatglm3はバージョン20231212です。
PS:トレーナーの使用はありません(トレーナーコードは簡単ですが、変更するのは簡単ではありません。大きなモデルの時代では、アルゴリズムエンジニアがデータエンジニアになっているため、トレーニングプロセスをさらに理解する必要があります)
モデルを微調整すると、ビデオメモリが不十分な場合は、Gradient_Checkpointing、Zero3、Offloadなどのパラメーターをオンにしてビデオメモリを保存できます。
次のmodel_name_or_pathパラメーターはモデルパスです。実際のモデルに従って保存できるアドレスに従って変更してください。
フリーズ方法、つまりパラメーターがフリーズし、いくつかのパラメーターは元のモデルに対して凍結されており、シングルまたは複数のカードを達成するためにトレーニングされているパラメーターの一部のみがトレーニングされています。 TPまたはPP操作が実行されない場合、大きなモデルをトレーニングできます。
微調整コードについては、train.pyを参照してください。コア部分は次のとおりです。
freeze_module_name = args . freeze_module_name . split ( "," )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in freeze_module_name ):
param . requires_grad = Falseモデルのさまざまなレイヤーを変更するには、 "layers.27。、layers.26。、layers.25。、layers.24など、freze_module_nameパラメーター構成を自分で変更できます。トレーニングコードはすべて、DeepSpeedを使用してトレーニングされています。パラメーターは、train_path、model_name_or_path、mode、train_type、freze_module_name、ds_file、num_train_epochs、per_device_train_batch_size、gradient_accumulation_steps、output_dirなどを含む設定できます。
Chatglmシングルカードトレーニング
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Chatglm 4カードトレーニング、cuda_visible_devicesは、どのカードがトレーニングされているかを制御します。このパラメーターが追加されていない場合、実行中のマシン上のすべてのカードがトレーニングされていることを意味します。
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Chatglm2シングルカードトレーニング
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
CHATGLM2 4カードトレーニング、CUDA_VISIBLE_DEVICESを介してトレーニングされるカードを制御します。このパラメーターが追加されていない場合、実行中のマシン上のすべてのカードがトレーニングされていることを意味します。
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Chatglm3シングルカードトレーニング
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
Chatglm3 4カードトレーニング、CUDA_VISIBLE_DEVICESを介してトレーニングされるカードを制御します。このパラメーターが追加されていない場合、実行中のマシン上のすべてのカードがトレーニングされていることを意味します。
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS:ChatGlmの微調整に使用されるビデオメモリは、ChatGlm2のビデオよりも多く、詳細なビデオメモリアカウントは次のとおりです。
| モデル | ディープスピードステージ | オフロード | 勾配チェックポイント | バッチサイズ | 最大長 | GPU-A40番号 | 消費されたビデオメモリ |
|---|---|---|---|---|---|---|---|
| チャグルム | zero2 | いいえ | はい | 1 | 1560 | 1 | 36g |
| チャグルム | zero2 | いいえ | いいえ | 1 | 1560 | 1 | 38g |
| チャグルム | zero2 | いいえ | はい | 1 | 1560 | 4 | 24g |
| チャグルム | zero2 | いいえ | いいえ | 1 | 1560 | 4 | 29g |
| Chaglm2 | zero2 | いいえ | はい | 1 | 1560 | 1 | 35g |
| Chaglm2 | zero2 | いいえ | いいえ | 1 | 1560 | 1 | 36g |
| Chaglm2 | zero2 | いいえ | はい | 1 | 1560 | 4 | 22g |
| Chaglm2 | zero2 | いいえ | いいえ | 1 | 1560 | 4 | 27g |
PTメソッド、つまりP調整法は、ChatGlmの公式コードを指し、大規模なモデルのソフトプロムプトメソッドです。
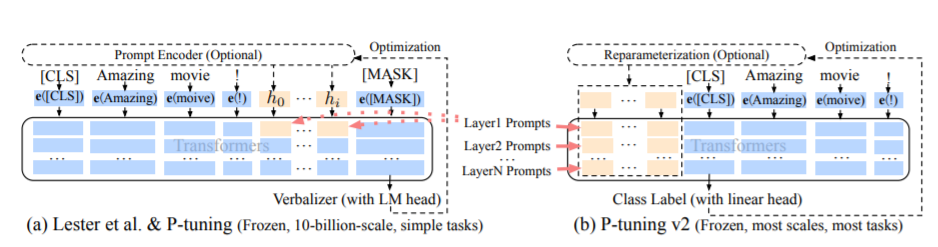
微調整コードについては、train.pyを参照してください。コア部分は次のとおりです。
config = MODE [ args . mode ][ "config" ]. from_pretrained ( args . model_name_or_path )
config . pre_seq_len = args . pre_seq_len
config . prefix_projection = args . prefix_projection
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path , config = config )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in [ "prefix_encoder" ]):
param . requires_grad = Falseprefix_projectionがtrueの場合、新しいパラメーターが埋め込みに追加され、大きなモデルの各層が追加されます。 falseの場合、新しいパラメーターが大きなモデルのみの埋め込みに追加されます。
トレーニングコードは、DeepSpeedを使用してトレーニングされます。パラメーターは、train_path、model_name_or_path、mode、train_type、pre_seq_len、prefix_projection、ds_file、num_train_epochs、per_device_train_batch_size、gradient_accumulation_stepsなどを含む設定を設定できます。
Chatglmシングルカードトレーニング
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 768
--max_src_len 512
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Chatglm 4カードトレーニング、cuda_visible_devicesは、どのカードがトレーニングされているかを制御します。このパラメーターが追加されていない場合、実行中のマシン上のすべてのカードがトレーニングされていることを意味します。
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Chatglm2シングルカードトレーニング
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
CHATGLM2 4カードトレーニング、CUDA_VISIBLE_DEVICESを介してトレーニングされるカードを制御します。このパラメーターが追加されていない場合、実行中のマシン上のすべてのカードがトレーニングされていることを意味します。
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Chatglm3シングルカードトレーニング
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
Chatglm3 4カードトレーニング、CUDA_VISIBLE_DEVICESを介してトレーニングされるカードを制御します。このパラメーターが追加されていない場合、実行中のマシン上のすべてのカードがトレーニングされていることを意味します。
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
PS:ChatGlmの微調整に使用されるビデオメモリは、ChatGlm2のビデオよりも多く、詳細なビデオメモリアカウントは次のとおりです。
| モデル | ディープスピードステージ | オフロード | 勾配チェックポイント | バッチサイズ | 最大長 | GPU-A40番号 | 消費されたビデオメモリ |
|---|---|---|---|---|---|---|---|
| チャグルム | zero2 | いいえ | はい | 1 | 768 | 1 | 43g |
| チャグルム | zero2 | いいえ | いいえ | 1 | 300 | 1 | 44g |
| チャグルム | zero2 | いいえ | はい | 1 | 1560 | 4 | 37g |
| チャグルム | zero2 | いいえ | いいえ | 1 | 1360 | 4 | 44g |
| Chaglm2 | zero2 | いいえ | はい | 1 | 1560 | 1 | 20g |
| Chaglm2 | zero2 | いいえ | いいえ | 1 | 1560 | 1 | 40g |
| Chaglm2 | zero2 | いいえ | はい | 1 | 1560 | 4 | 19g |
| Chaglm2 | zero2 | いいえ | いいえ | 1 | 1560 | 4 | 39g |
LORAメソッド、つまり、大きな言語モデルで並行して指定されたパラメーター(重量マトリックス)に追加の低ランクマトリックスを追加し、モデルトレーニング中に、並列低ランクマトリックスの追加パラメーターのみがトレーニングされます。 「ランク値」が元のパラメーターディメンションよりもはるかに小さい場合、新しく追加された低ランクマトリックスパラメーターの数も非常に少ないです。ダウンストリームタスクを調整する場合、小さなパラメーターのみをトレーニングする必要がありますが、優れたパフォーマンスの結果を取得できます。
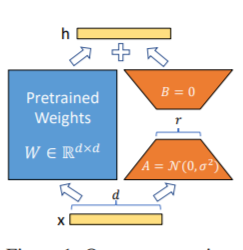
微調整コードについては、train.pyを参照してください。コア部分は次のとおりです。
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )
lora_module_name = args . lora_module_name . split ( "," )
config = LoraConfig ( r = args . lora_dim ,
lora_alpha = args . lora_alpha ,
target_modules = lora_module_name ,
lora_dropout = args . lora_dropout ,
bias = "none" ,
task_type = "CAUSAL_LM" ,
inference_mode = False ,
)
model = get_peft_model ( model , config )
model . config . torch_dtype = torch . float32PS:LORAトレーニングの後、最初にパラメーターをマージし、モデルの予測を行います。
トレーニングコードは、DeepSpeedを使用してトレーニングされます。パラメーターは、train_path、model_name_or_path、mode、train_type、lora_dim、lora_alpha、lora_dropout、lora_module_name、ds_fileなど、設定できます。独自のタスクに従って構成されています。
Chatglmシングルカードトレーニング
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Chatglm 4カードトレーニング、cuda_visible_devicesは、どのカードがトレーニングされているかを制御します。このパラメーターが追加されていない場合、実行中のマシン上のすべてのカードがトレーニングされていることを意味します。
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Chatglm2シングルカードトレーニング
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
CHATGLM2 4カードトレーニング、CUDA_VISIBLE_DEVICESを介してトレーニングされるカードを制御します。このパラメーターが追加されていない場合、実行中のマシン上のすべてのカードがトレーニングされていることを意味します。
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Chatglm3シングルカードトレーニング
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
Chatglm3 4カードトレーニング、CUDA_VISIBLE_DEVICESを介してトレーニングされるカードを制御します。このパラメーターが追加されていない場合、実行中のマシン上のすべてのカードがトレーニングされていることを意味します。
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS:ChatGlmの微調整に使用されるビデオメモリは、ChatGlm2のビデオよりも多く、詳細なビデオメモリアカウントは次のとおりです。
| モデル | ディープスピードステージ | オフロード | 勾配チェックポイント | バッチサイズ | 最大長 | GPU-A40番号 | 消費されたビデオメモリ |
|---|---|---|---|---|---|---|---|
| チャグルム | zero2 | いいえ | はい | 1 | 1560 | 1 | 20g |
| チャグルム | zero2 | いいえ | いいえ | 1 | 1560 | 1 | 45g |
| チャグルム | zero2 | いいえ | はい | 1 | 1560 | 4 | 20g |
| チャグルム | zero2 | いいえ | いいえ | 1 | 1560 | 4 | 45g |
| Chaglm2 | zero2 | いいえ | はい | 1 | 1560 | 1 | 20g |
| Chaglm2 | zero2 | いいえ | いいえ | 1 | 1560 | 1 | 43g |
| Chaglm2 | zero2 | いいえ | はい | 1 | 1560 | 4 | 19g |
| Chaglm2 | zero2 | いいえ | いいえ | 1 | 1560 | 4 | 42g |
注:LORAメソッドは、モデルを保存するときにLORAトレーニングパラメーターのみを保存するため、モデルを予測するときにモデルパラメーターをマージする必要があります。詳細については、merge_lora.pyを参照してください。
完全なパラメーター法を使用して、完全なパラメーターで大きなモデルをトレーニングします。主にDeepSpeed-Zero3メソッドを使用してモデルパラメーターを複数のカードに分割し、オフロードメソッドを使用してオプティマイザーパラメーターをCPUにアンロードして、グラフィックスカードが不十分な問題を解決します。
微調整コードについては、train.pyを参照してください。コア部分は次のとおりです。
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )トレーニングコードは、DeepSpeedを使用してトレーニングされます。パラメーターは、train_path、model_name_or_path、mode、train_type、ds_file、num_train_epochs、per_device_train_batch_size、gradient_accumulation_steps、output_dirなどを含む、自分のタスクに従って構成できます。
Chatglm 4カードトレーニング、cuda_visible_devicesは、どのカードがトレーニングされているかを制御します。このパラメーターが追加されていない場合、実行中のマシン上のすべてのカードがトレーニングされていることを意味します。
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type all
--seed 1234
--ds_file ds_zero3_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
CHATGLM2 4カードトレーニング、CUDA_VISIBLE_DEVICESを介してトレーニングされるカードを制御します。このパラメーターが追加されていない場合、実行中のマシン上のすべてのカードがトレーニングされていることを意味します。
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Chatglm3 4カードトレーニング、CUDA_VISIBLE_DEVICESを介してトレーニングされるカードを制御します。このパラメーターが追加されていない場合、実行中のマシン上のすべてのカードがトレーニングされていることを意味します。
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS:ChatGlmの微調整に使用されるビデオメモリは、ChatGlm2のビデオよりも多く、詳細なビデオメモリアカウントは次のとおりです。
| モデル | ディープスピードステージ | オフロード | 勾配チェックポイント | バッチサイズ | 最大長 | GPU-A40番号 | 消費されたビデオメモリ |
|---|---|---|---|---|---|---|---|
| チャグルム | zero3 | はい | はい | 1 | 1560 | 4 | 33g |
| Chaglm2 | zero3 | いいえ | はい | 1 | 1560 | 4 | 44g |
| Chaglm2 | zero3 | はい | はい | 1 | 1560 | 4 | 26g |
以下は、DeepSpeedのゼロステージの関連コンテンツの説明です。
要件を表示します。txtファイル
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为"性能故障", "部件故障", "组成"和 "检测工具"的相关三元组,三元组内部用"_"连接,三元组之间用\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高n风扇_部件故障_低速转动"
}
| 微調整方法 | PTのみの埋め込み | pt | フリーズ | ロラ |
|---|---|---|---|---|
| テスト結果F1 | 0.0 | 0.6283 | 0.5675 | 0.5359 |
構造分析:
多くの学生は、微調整後に壊滅的な忘却を経験しましたが、このプロジェクトのトレーニングコードは登場しませんでした。彼らは、「翻訳タスク」、「コードタスク」、および「質問と回答のタスク」をテストしました。特定のテスト結果は次のとおりです。


{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
生成モデルの内容は情報抽出タスクのように評価できないため、既存の青またはルージュを使用して評価することは適切ではないため、スコアリングルールが策定されました。 D2Qモデルは、多様性と精度の2つの視点から審査されます。各サンプルには合計5ポイントがあり、合計20個のサンプルがあります。
| 微調整方法 | オリジナルモデル | PTのみの埋め込み | pt | フリーズ | ロラ |
|---|---|---|---|---|---|
| 分数 | 51.75 | 73.75 | 87.75 | 79.25 | 86.75 |
コードの説明:パイプライン並列処理(パイプライン)練習を参照してください
V0.1タグをご覧ください


