ChatGLM Finetuning
v0.1
This project mainly performs fine-tuning in different ways (Freeze method, Lora method, P-Tuning method, full parameters, etc.) for ChatGLM, ChatGLM2 and ChatGLM3 models, and compares the effects of the large model on different fine-tuning methods, mainly targeting information extraction tasks, generation tasks, classification tasks, etc.
This project supports single-card training and multiple-card training. Due to the single instruction set fine-tuning, there is no serious catastrophic forgetting after the fine-tuning of the model.
Since the official code and model have been updated, the current code and model of ChatGLM1 and 2 is version 20230806 (note that if the code is running incorrectly, you can replace the py file in the file with the ChatGLM-related source code, because the model version you are under may be inconsistent with the code version of this project). ChatGLM3 is version 20231212.
PS: There is no use of Trainer (although the Trainer code is simple, it is not easy to modify. In the era of big models, algorithm engineers have become data engineers, so they need to understand the training process more)
When fine-tuning the model, if there is insufficient video memory, you can turn on parameters such as gradient_checkpointing, zero3, and offload to save video memory.
The following model_name_or_path parameter is the model path. Please modify it according to the address you can save according to your actual model.
Freeze method, that is, parameter freezes, and some parameters are frozen for the original model, and only some parameters are trained to achieve single or multiple cards. If the TP or PP operation is not performed, the big model can be trained.
For fine-tuning code, see train.py, the core part is as follows:
freeze_module_name = args . freeze_module_name . split ( "," )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in freeze_module_name ):
param . requires_grad = FalseFor modifications to different layers of the model, you can modify the freeze_module_name parameter configuration yourself, such as "layers.27.,layers.26.,layers.25.,layers.24." The training codes are all trained using DeepSpeed. The parameters can be set including train_path, model_name_or_path, mode, train_type, freeze_module_name, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir, etc., and can be configured according to your own tasks.
ChatGLM single card training
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGLM four-card training, CUDA_VISIBLE_DEVICES controls which cards are trained. If this parameter is not added, it means that all cards on the running machine are trained.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGLM2 single card training
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGLM2 four-card training, control which cards are trained through CUDA_VISIBLE_DEVICES. If this parameter is not added, it means that all cards on the running machine are trained.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGLM3 single card training
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
ChatGLM3 four-card training, control which cards are trained through CUDA_VISIBLE_DEVICES. If this parameter is not added, it means that all cards on the running machine are trained.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: The video memory used for fine-tuning of ChatGLM is more than that of ChatGLM2, and the detailed video memory accounts for the following:
| Model | DeepSpeed-Stage | Offload | Gradient Checkpointing | Batch Size | Max Length | GPU-A40 Number | Consumed video memory |
|---|---|---|---|---|---|---|---|
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 1 | 36G |
| ChaGLM | zero2 | No | No | 1 | 1560 | 1 | 38G |
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 4 | 24G |
| ChaGLM | zero2 | No | No | 1 | 1560 | 4 | 29G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 1 | 35G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 1 | 36G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 4 | 22G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 4 | 27G |
The PT method, namely the P-Tuning method, refers to the official code of ChatGLM, is a soft-prompt method for large models.
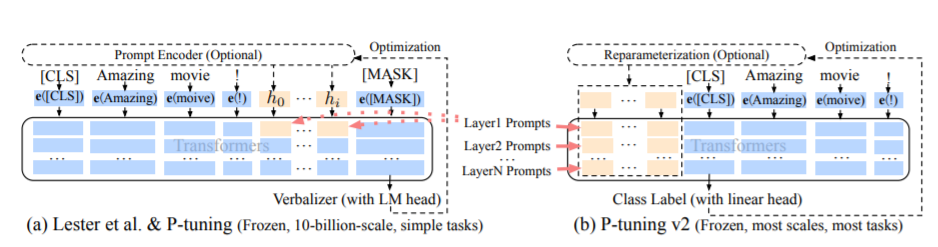
For fine-tuning code, see train.py, the core part is as follows:
config = MODE [ args . mode ][ "config" ]. from_pretrained ( args . model_name_or_path )
config . pre_seq_len = args . pre_seq_len
config . prefix_projection = args . prefix_projection
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path , config = config )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in [ "prefix_encoder" ]):
param . requires_grad = FalseWhen prefix_projection is True, new parameters are added to the Embedding and each layer of the big model; when False, new parameters are added to the Embedding of the big model only.
The training codes are trained using DeepSpeed. The parameters can be set including train_path, model_name_or_path, mode, train_type, pre_seq_len, prefix_projection, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir, etc., and can be configured according to your own tasks.
ChatGLM single card training
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 768
--max_src_len 512
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
ChatGLM four-card training, CUDA_VISIBLE_DEVICES controls which cards are trained. If this parameter is not added, it means that all cards on the running machine are trained.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
ChatGLM2 single card training
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
ChatGLM2 four-card training, control which cards are trained through CUDA_VISIBLE_DEVICES. If this parameter is not added, it means that all cards on the running machine are trained.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
ChatGLM3 single card training
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
ChatGLM3 four-card training, control which cards are trained through CUDA_VISIBLE_DEVICES. If this parameter is not added, it means that all cards on the running machine are trained.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
PS: The video memory used for fine-tuning of ChatGLM is more than that of ChatGLM2, and the detailed video memory accounts for the following:
| Model | DeepSpeed-Stage | Offload | Gradient Checkpointing | Batch Size | Max Length | GPU-A40 Number | Consumed video memory |
|---|---|---|---|---|---|---|---|
| ChaGLM | zero2 | No | Yes | 1 | 768 | 1 | 43G |
| ChaGLM | zero2 | No | No | 1 | 300 | 1 | 44G |
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 4 | 37G |
| ChaGLM | zero2 | No | No | 1 | 1360 | 4 | 44G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 1 | 20G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 1 | 40G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 4 | 19G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 4 | 39G |
The Lora method, that is, to add additional low-rank matrix to the specified parameters (weight matrix) in parallel on large language models, and during model training, only the additional parameters of the parallel low-rank matrix are trained. When the "rank value" is much smaller than the original parameter dimension, the number of newly added low-rank matrix parameters is also very small. When tuning downstream tasks, only small parameters must be trained, but good performance results can be obtained.
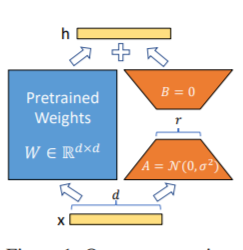
For fine-tuning code, see train.py, the core part is as follows:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )
lora_module_name = args . lora_module_name . split ( "," )
config = LoraConfig ( r = args . lora_dim ,
lora_alpha = args . lora_alpha ,
target_modules = lora_module_name ,
lora_dropout = args . lora_dropout ,
bias = "none" ,
task_type = "CAUSAL_LM" ,
inference_mode = False ,
)
model = get_peft_model ( model , config )
model . config . torch_dtype = torch . float32PS: After Lora training, please merge the parameters first and make model predictions.
The training codes are trained using DeepSpeed. The parameters can be set including train_path, model_name_or_path, mode, train_type, lora_dim, lora_alpha, lora_dropout, lora_module_name, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir, etc., and can be configured according to your own tasks.
ChatGLM single card training
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGLM four-card training, CUDA_VISIBLE_DEVICES controls which cards are trained. If this parameter is not added, it means that all cards on the running machine are trained.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGLM2 single card training
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGLM2 four-card training, control which cards are trained through CUDA_VISIBLE_DEVICES. If this parameter is not added, it means that all cards on the running machine are trained.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGLM3 single card training
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
ChatGLM3 four-card training, control which cards are trained through CUDA_VISIBLE_DEVICES. If this parameter is not added, it means that all cards on the running machine are trained.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: The video memory used for fine-tuning of ChatGLM is more than that of ChatGLM2, and the detailed video memory accounts for the following:
| Model | DeepSpeed-Stage | Offload | Gradient Checkpointing | Batch Size | Max Length | GPU-A40 Number | Consumed video memory |
|---|---|---|---|---|---|---|---|
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 1 | 20G |
| ChaGLM | zero2 | No | No | 1 | 1560 | 1 | 45G |
| ChaGLM | zero2 | No | Yes | 1 | 1560 | 4 | 20G |
| ChaGLM | zero2 | No | No | 1 | 1560 | 4 | 45G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 1 | 20G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 1 | 43G |
| ChaGLM2 | zero2 | No | Yes | 1 | 1560 | 4 | 19G |
| ChaGLM2 | zero2 | No | No | 1 | 1560 | 4 | 42G |
Note: The Lora method only saves the Lora training parameters when saving the model, so the model parameters need to be merged when predicting the model. For details, please refer to merge_lora.py.
The full parameter method is used to train the large model in full parameters. It mainly uses the DeepSpeed-Zero3 method to divide the model parameters into multiple cards, and uses the Offload method to unload the optimizer parameters to the CPU to solve the problem of insufficient graphics cards.
For fine-tuning code, see train.py, the core part is as follows:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )The training codes are trained using DeepSpeed. The parameters can be set including train_path, model_name_or_path, mode, train_type, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir, etc., which can be configured according to your own tasks.
ChatGLM four-card training, CUDA_VISIBLE_DEVICES controls which cards are trained. If this parameter is not added, it means that all cards on the running machine are trained.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type all
--seed 1234
--ds_file ds_zero3_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGLM2 four-card training, control which cards are trained through CUDA_VISIBLE_DEVICES. If this parameter is not added, it means that all cards on the running machine are trained.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGLM3 four-card training, control which cards are trained through CUDA_VISIBLE_DEVICES. If this parameter is not added, it means that all cards on the running machine are trained.
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: The video memory used for fine-tuning of ChatGLM is more than that of ChatGLM2, and the detailed video memory accounts for the following:
| Model | DeepSpeed-Stage | Offload | Gradient Checkpointing | Batch Size | Max Length | GPU-A40 Number | Consumed video memory |
|---|---|---|---|---|---|---|---|
| ChaGLM | zero3 | Yes | Yes | 1 | 1560 | 4 | 33G |
| ChaGLM2 | zero3 | No | Yes | 1 | 1560 | 4 | 44G |
| ChaGLM2 | zero3 | Yes | Yes | 1 | 1560 | 4 | 26G |
The following is a description of the relevant content of DeepSpeed's Zero-Stage.
View requirements.txt file
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为"性能故障", "部件故障", "组成"和 "检测工具"的相关三元组,三元组内部用"_"连接,三元组之间用\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高n风扇_部件故障_低速转动"
}
| Fine-tuning method | PT-Only-Embedding | PT | Freeze | Lora |
|---|---|---|---|---|
| Test results F1 | 0.0 | 0.6283 | 0.5675 | 0.5359 |
Structural Analysis:
Many students experienced catastrophic forgetting after fine-tuning, but the training code of this project did not appear. They tested the "translation task", "code task", and "question and answer task". The specific test results are as follows:


{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
Since the content of the generative model cannot be evaluated like the information extraction task, it is not appropriate to use existing BLUE or Rouge to evaluate, so a scoring rule was formulated. The D2Q model is judged through the two perspectives of diversity and accuracy. Each sample has a total of 5 points, with a total of 20 samples.
| Fine-tuning method | Original model | PT-Only-Embedding | PT | Freeze | Lora |
|---|---|---|---|---|---|
| Fraction | 51.75 | 73.75 | 87.75 | 79.25 | 86.75 |
See the code description: Pipeline parallelism (Pipeline) practice
Please see v0.1 Tag


