ChatGLM Finetuning
v0.1
Proyek ini terutama melakukan fine-tuning dengan cara yang berbeda (metode freeze, metode LORA, metode p-tuning, parameter penuh, dll.) Untuk model chatglm, chatglm2 dan chatglm3, dan membandingkan efek dari model besar pada metode penyempurnaan yang berbeda, terutama menargetkan tugas ekstraksi informasi, tugas pembangkitan, toran klasifikasi, dll. Tower, dll.
Proyek ini mendukung pelatihan kartu tunggal dan pelatihan banyak kartu. Karena instruksi tunggal set fine-tuning, tidak ada bencana serius yang melupakan setelah penyesuaian model.
Karena kode dan model resmi telah diperbarui, kode saat ini dan model ChatGLM1 dan 2 adalah versi 20230806 (perhatikan bahwa jika kode berjalan secara tidak benar, Anda dapat mengganti file PY dalam file dengan kode sumber yang terkait dengan ChatGLM, karena versi model yang Anda bawah mungkin tidak konsisten dengan versi kode proyek ini). Chatglm3 adalah versi 20231212.
PS: Tidak ada penggunaan pelatih (meskipun kode pelatih sederhana, tidak mudah untuk memodifikasi. Di era model besar, insinyur algoritma telah menjadi insinyur data, jadi mereka perlu memahami lebih banyak proses pelatihan)
Saat menyempurnakan model, jika ada memori video yang tidak mencukupi, Anda dapat menyalakan parameter seperti gradient_checkpointing, nol3, dan dibongkar untuk menyimpan memori video.
Parameter model_name_or_path berikut adalah jalur model. Harap ubah sesuai dengan alamat yang dapat Anda simpan sesuai dengan model Anda yang sebenarnya.
Metode beku, yaitu parameter freezes, dan beberapa parameter dibekukan untuk model asli, dan hanya beberapa parameter yang dilatih untuk mencapai kartu tunggal atau ganda. Jika operasi TP atau PP tidak dilakukan, model besar dapat dilatih.
Untuk kode fine tuning, lihat train.py, bagian intinya adalah sebagai berikut:
freeze_module_name = args . freeze_module_name . split ( "," )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in freeze_module_name ):
param . requires_grad = FalseUntuk modifikasi ke berbagai lapisan model, Anda dapat memodifikasi sendiri konfigurasi parameter freeze_module_name, seperti "layer.27., Layers.26., Layers.25., Layers.24." Semua kode pelatihan dilatih menggunakan kecepatan. Parameter dapat ditetapkan termasuk train_path, model_name_or_path, mode, train_type, freeze_module_name, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation TUSTEPS, output_dir, dll, dan dapat dikonfigurasi dengan Anda.
Pelatihan kartu single chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Pelatihan empat kartu chatglm, kontrol cuda_visible_devices kartu mana yang dilatih. Jika parameter ini tidak ditambahkan, itu berarti bahwa semua kartu pada mesin berjalan dilatih.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Pelatihan kartu single chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Pelatihan empat kartu chatglm2, kontrol kartu mana yang dilatih melalui cuda_visible_devices. Jika parameter ini tidak ditambahkan, itu berarti bahwa semua kartu pada mesin berjalan dilatih.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Pelatihan kartu single chatglm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
Pelatihan empat kartu chatglm3, kontrol kartu mana yang dilatih melalui cuda_visible_devices. Jika parameter ini tidak ditambahkan, itu berarti bahwa semua kartu pada mesin berjalan dilatih.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: Memori video yang digunakan untuk fine-tuning chatglm lebih dari chatglm2, dan memori video terperinci akun untuk yang berikut:
| Model | Tahap kecepatan | Di luar beban | CHECKPOINTING GRADIEN | Ukuran batch | Panjang maksimal | Nomor GPU-A40 | Memori video yang dikonsumsi |
|---|---|---|---|---|---|---|---|
| Chaglm | Zero2 | TIDAK | Ya | 1 | 1560 | 1 | 36g |
| Chaglm | Zero2 | TIDAK | TIDAK | 1 | 1560 | 1 | 38g |
| Chaglm | Zero2 | TIDAK | Ya | 1 | 1560 | 4 | 24g |
| Chaglm | Zero2 | TIDAK | TIDAK | 1 | 1560 | 4 | 29g |
| Chaglm2 | Zero2 | TIDAK | Ya | 1 | 1560 | 1 | 35g |
| Chaglm2 | Zero2 | TIDAK | TIDAK | 1 | 1560 | 1 | 36g |
| Chaglm2 | Zero2 | TIDAK | Ya | 1 | 1560 | 4 | 22g |
| Chaglm2 | Zero2 | TIDAK | TIDAK | 1 | 1560 | 4 | 27g |
Metode PT, yaitu metode p-tuning, mengacu pada kode resmi chatglm, adalah metode prompt lunak untuk model besar.
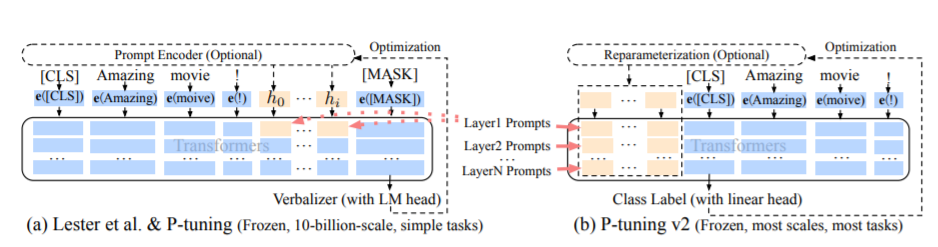
Untuk kode fine tuning, lihat train.py, bagian intinya adalah sebagai berikut:
config = MODE [ args . mode ][ "config" ]. from_pretrained ( args . model_name_or_path )
config . pre_seq_len = args . pre_seq_len
config . prefix_projection = args . prefix_projection
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path , config = config )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in [ "prefix_encoder" ]):
param . requires_grad = FalseKetika prefix_proyjection benar, parameter baru ditambahkan ke embedding dan setiap lapisan model besar; Ketika false, parameter baru ditambahkan ke embedding model besar saja.
Kode pelatihan dilatih menggunakan kecepatan. Parameter dapat diatur termasuk train_path, model_name_or_path, mode, train_type, pre_seq_len, prefix_proyjection, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir, dll.
Pelatihan kartu single chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 768
--max_src_len 512
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Pelatihan empat kartu chatglm, kontrol cuda_visible_devices kartu mana yang dilatih. Jika parameter ini tidak ditambahkan, itu berarti bahwa semua kartu pada mesin berjalan dilatih.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Pelatihan kartu single chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Pelatihan empat kartu chatglm2, kontrol kartu mana yang dilatih melalui cuda_visible_devices. Jika parameter ini tidak ditambahkan, itu berarti bahwa semua kartu pada mesin berjalan dilatih.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Pelatihan kartu single chatglm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
Pelatihan empat kartu chatglm3, kontrol kartu mana yang dilatih melalui cuda_visible_devices. Jika parameter ini tidak ditambahkan, itu berarti bahwa semua kartu pada mesin berjalan dilatih.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
PS: Memori video yang digunakan untuk fine-tuning chatglm lebih dari chatglm2, dan memori video terperinci akun untuk yang berikut:
| Model | Tahap kecepatan | Di luar beban | CHECKPOINTING GRADIEN | Ukuran batch | Panjang maksimal | Nomor GPU-A40 | Memori video yang dikonsumsi |
|---|---|---|---|---|---|---|---|
| Chaglm | Zero2 | TIDAK | Ya | 1 | 768 | 1 | 43g |
| Chaglm | Zero2 | TIDAK | TIDAK | 1 | 300 | 1 | 44g |
| Chaglm | Zero2 | TIDAK | Ya | 1 | 1560 | 4 | 37g |
| Chaglm | Zero2 | TIDAK | TIDAK | 1 | 1360 | 4 | 44g |
| Chaglm2 | Zero2 | TIDAK | Ya | 1 | 1560 | 1 | 20g |
| Chaglm2 | Zero2 | TIDAK | TIDAK | 1 | 1560 | 1 | 40g |
| Chaglm2 | Zero2 | TIDAK | Ya | 1 | 1560 | 4 | 19g |
| Chaglm2 | Zero2 | TIDAK | TIDAK | 1 | 1560 | 4 | 39g |
Metode LORA, yaitu, untuk menambahkan matriks peringkat rendah tambahan ke parameter yang ditentukan (matriks berat) secara paralel pada model bahasa besar, dan selama pelatihan model, hanya parameter tambahan dari matriks peringkat rendah paralel yang dilatih. Ketika "nilai peringkat" jauh lebih kecil dari dimensi parameter asli, jumlah parameter matriks peringkat rendah yang baru ditambahkan juga sangat kecil. Saat menyetel tugas hilir, hanya parameter kecil yang harus dilatih, tetapi hasil kinerja yang baik dapat diperoleh.
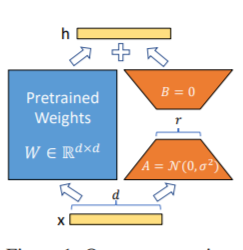
Untuk kode fine tuning, lihat train.py, bagian intinya adalah sebagai berikut:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )
lora_module_name = args . lora_module_name . split ( "," )
config = LoraConfig ( r = args . lora_dim ,
lora_alpha = args . lora_alpha ,
target_modules = lora_module_name ,
lora_dropout = args . lora_dropout ,
bias = "none" ,
task_type = "CAUSAL_LM" ,
inference_mode = False ,
)
model = get_peft_model ( model , config )
model . config . torch_dtype = torch . float32PS: Setelah pelatihan Lora, harap gabungkan parameter terlebih dahulu dan buat prediksi model.
Kode pelatihan dilatih menggunakan kecepatan. The parameters can be set including train_path, model_name_or_path, mode, train_type, lora_dim, lora_alpha, lora_dropout, lora_module_name, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir, etc., and can be configured Menurut tugas Anda sendiri.
Pelatihan kartu single chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Pelatihan empat kartu chatglm, kontrol cuda_visible_devices kartu mana yang dilatih. Jika parameter ini tidak ditambahkan, itu berarti bahwa semua kartu pada mesin berjalan dilatih.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Pelatihan kartu single chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Pelatihan empat kartu chatglm2, kontrol kartu mana yang dilatih melalui cuda_visible_devices. Jika parameter ini tidak ditambahkan, itu berarti bahwa semua kartu pada mesin berjalan dilatih.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Pelatihan kartu single chatglm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
Pelatihan empat kartu chatglm3, kontrol kartu mana yang dilatih melalui cuda_visible_devices. Jika parameter ini tidak ditambahkan, itu berarti bahwa semua kartu pada mesin berjalan dilatih.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: Memori video yang digunakan untuk fine-tuning chatglm lebih dari chatglm2, dan memori video terperinci akun untuk yang berikut:
| Model | Tahap kecepatan | Di luar beban | CHECKPOINTING GRADIEN | Ukuran batch | Panjang maksimal | Nomor GPU-A40 | Memori video yang dikonsumsi |
|---|---|---|---|---|---|---|---|
| Chaglm | Zero2 | TIDAK | Ya | 1 | 1560 | 1 | 20g |
| Chaglm | Zero2 | TIDAK | TIDAK | 1 | 1560 | 1 | 45g |
| Chaglm | Zero2 | TIDAK | Ya | 1 | 1560 | 4 | 20g |
| Chaglm | Zero2 | TIDAK | TIDAK | 1 | 1560 | 4 | 45g |
| Chaglm2 | Zero2 | TIDAK | Ya | 1 | 1560 | 1 | 20g |
| Chaglm2 | Zero2 | TIDAK | TIDAK | 1 | 1560 | 1 | 43g |
| Chaglm2 | Zero2 | TIDAK | Ya | 1 | 1560 | 4 | 19g |
| Chaglm2 | Zero2 | TIDAK | TIDAK | 1 | 1560 | 4 | 42g |
Catatan: Metode LORA hanya menyimpan parameter pelatihan LORA saat menyimpan model, sehingga parameter model perlu digabungkan saat memprediksi model. Untuk detailnya, silakan merujuk ke merge_lora.py.
Metode parameter penuh digunakan untuk melatih model besar dalam parameter penuh. Ini terutama menggunakan metode Deepspeed-Zero3 untuk membagi parameter model menjadi beberapa kartu, dan menggunakan metode offload untuk membongkar parameter pengoptimal ke CPU untuk menyelesaikan masalah kartu grafis yang tidak mencukupi.
Untuk kode fine tuning, lihat train.py, bagian intinya adalah sebagai berikut:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )Kode pelatihan dilatih menggunakan kecepatan. Parameter dapat diatur termasuk train_path, model_name_or_path, mode, train_type, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir, dll., Yang dapat dikonfigurasi sesuai dengan tasks Anda sendiri.
Pelatihan empat kartu chatglm, kontrol cuda_visible_devices kartu mana yang dilatih. Jika parameter ini tidak ditambahkan, itu berarti bahwa semua kartu pada mesin berjalan dilatih.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type all
--seed 1234
--ds_file ds_zero3_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Pelatihan empat kartu chatglm2, kontrol kartu mana yang dilatih melalui cuda_visible_devices. Jika parameter ini tidak ditambahkan, itu berarti bahwa semua kartu pada mesin berjalan dilatih.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Pelatihan empat kartu chatglm3, kontrol kartu mana yang dilatih melalui cuda_visible_devices. Jika parameter ini tidak ditambahkan, itu berarti bahwa semua kartu pada mesin berjalan dilatih.
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: Memori video yang digunakan untuk fine-tuning chatglm lebih dari chatglm2, dan memori video terperinci akun untuk yang berikut:
| Model | Tahap kecepatan | Di luar beban | CHECKPOINTING GRADIEN | Ukuran batch | Panjang maksimal | Nomor GPU-A40 | Memori video yang dikonsumsi |
|---|---|---|---|---|---|---|---|
| Chaglm | Zero3 | Ya | Ya | 1 | 1560 | 4 | 33g |
| Chaglm2 | Zero3 | TIDAK | Ya | 1 | 1560 | 4 | 44g |
| Chaglm2 | Zero3 | Ya | Ya | 1 | 1560 | 4 | 26g |
Berikut ini adalah deskripsi konten yang relevan dari tahap nol Deepedspeed.
Lihat file persyaratan.txt
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为"性能故障", "部件故障", "组成"和 "检测工具"的相关三元组,三元组内部用"_"连接,三元组之间用\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高n风扇_部件故障_低速转动"
}
| Metode penyempurnaan | PT-Hanya-Embedding | Pt | Membekukan | Lora |
|---|---|---|---|---|
| Hasil tes F1 | 0,0 | 0.6283 | 0,5675 | 0,5359 |
Analisis Struktural:
Banyak siswa mengalami lupa bencana setelah menyempurnakan, tetapi kode pelatihan proyek ini tidak muncul. Mereka menguji "Tugas Terjemahan", "Tugas Kode", dan "Tanya Tanya dan Jawaban Tugas". Hasil tes spesifik adalah sebagai berikut:


{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
Karena konten model generatif tidak dapat dievaluasi seperti tugas ekstraksi informasi, tidak tepat untuk menggunakan biru atau merah yang ada untuk dievaluasi, sehingga aturan penilaian dirumuskan. Model D2Q dinilai melalui dua perspektif keanekaragaman dan akurasi. Setiap sampel memiliki total 5 poin, dengan total 20 sampel.
| Metode penyempurnaan | Model asli | PT-Hanya-Embedding | Pt | Membekukan | Lora |
|---|---|---|---|---|---|
| Pecahan | 51.75 | 73.75 | 87.75 | 79.25 | 86.75 |
Lihat Kode Deskripsi: Praktek Pipa Paralelisme (Pipeline)
Silakan lihat tag v0.1


