ChatGLM Finetuning
v0.1
Dieses Projekt führt hauptsächlich Feinabstimmungen auf unterschiedliche Weise (Freeze-Methode, LORA-Methode, P-Tuning-Methode, vollständige Parameter usw.) für Chatglm-, Chatglm2- und Chatglm3-Modelle durch und vergleicht die Auswirkungen des großen Modells auf verschiedene Feinabstimmungsmethoden, hauptsächlich Targeting-Extraktionsaufgaben, Generierung, Klassifizierungsaufgaben usw. usw. usw. usw. usw. usw. usw.
Dieses Projekt unterstützt Einzelkartenschulungen und Mehrfachkartentraining. Aufgrund der Feinabstimmung der einzelnen Anweisungen gibt es nach der Feinabstimmung des Modells kein ernstes katastrophales Vergessen .
Da der offizielle Code und das offizielle Modell aktualisiert wurden, ist der aktuelle Code und das Modell von Chatglm1 und 2 Version 20230806 (beachten Sie, dass Sie die PY-Datei in der Datei durch den Chatglm-bezogenen Quellcode ersetzen können, da die Modellversion möglicherweise nicht mit der Codeversion dieses Projekts nicht stimmt. Chatglm3 ist Version 20231212.
PS: Es wird keine Trainer verwendet (obwohl der Trainercode einfach ist, ist er nicht einfach zu ändern. Im Zeitalter großer Modelle sind Algorithmus -Ingenieure zu Dateningenieuren geworden, sodass sie den Trainingsprozess mehr verstehen müssen)
Wenn Sie das Modell Feinabstimmung haben, können Sie bei unzureichender Videospeicher Parameter wie gradient_checkpointing, Zero3 und Ausladen einschalten, um den Videospeicher zu speichern.
Der folgende Parameter model_name_or_path ist der Modellpfad. Bitte ändern Sie es gemäß der Adresse, die Sie entsprechend Ihrem tatsächlichen Modell speichern können.
Freeze -Methode, dh Parameter -Gefrierungen, und einige Parameter sind für das ursprüngliche Modell gefroren, und nur einige Parameter werden geschult, um einzelne oder mehrere Karten zu erreichen. Wenn der TP- oder PP -Betrieb nicht durchgeführt wird, kann das große Modell trainiert werden.
Für den Feinabstimmungscode siehe Train.py, der Kernteil lautet wie folgt:
freeze_module_name = args . freeze_module_name . split ( "," )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in freeze_module_name ):
param . requires_grad = FalseFür Änderungen an verschiedenen Ebenen des Modells können Sie die Parameterkonfiguration freeze_module_name selbst ändern, z. B. "Ebenen.27., Layers.26., Layers.25., Layers.24". Die Trainingscodes werden alle mit DeepSpeed geschult. Die Parameter können eingestellt werden, einschließlich Train_path, model_name_or_path, modus, train_type, freeze_module_name, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir usw. und können nach Ihren eigenen Täken konfiguriert werden.
Chatglm Einzelkartentraining
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Chatglm Vier-Karten-Training, CUDA_VISIBLE_DEVICES-Steuerelemente, welche Karten geschult werden. Wenn dieser Parameter nicht hinzugefügt wird, bedeutet dies, dass alle Karten auf der Laufmaschine trainiert werden.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Chatglm2 Einzelkartentraining
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Chatglm2-Vier-Karten-Training, Kontrolle, welche Karten über cuda_visible_devices trainiert werden. Wenn dieser Parameter nicht hinzugefügt wird, bedeutet dies, dass alle Karten auf der Laufmaschine trainiert werden.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Chatglm3 Einzelkartentraining
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
Chatglm3-Vier-Karten-Training, Kontrolle, welche Karten über CUDA_VISIBLE_DEVICES geschult werden. Wenn dieser Parameter nicht hinzugefügt wird, bedeutet dies, dass alle Karten auf der Laufmaschine trainiert werden.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: Der für die Feinabstimmung von Chatglm verwendete Videospeicher ist mehr als der von Chatglm2, und die detaillierten Videospeicherbeschwerden werden Folgendes enthält:
| Modell | Deepspeed-Stufe | Ausladen | Gradientenprüfung | Chargengröße | Maximale Länge | GPU-A40-Nummer | Verbraucher Videospeicher |
|---|---|---|---|---|---|---|---|
| Chaglm | Null2 | NEIN | Ja | 1 | 1560 | 1 | 36g |
| Chaglm | Null2 | NEIN | NEIN | 1 | 1560 | 1 | 38g |
| Chaglm | Null2 | NEIN | Ja | 1 | 1560 | 4 | 24g |
| Chaglm | Null2 | NEIN | NEIN | 1 | 1560 | 4 | 29g |
| Chaglm2 | Null2 | NEIN | Ja | 1 | 1560 | 1 | 35G |
| Chaglm2 | Null2 | NEIN | NEIN | 1 | 1560 | 1 | 36g |
| Chaglm2 | Null2 | NEIN | Ja | 1 | 1560 | 4 | 22g |
| Chaglm2 | Null2 | NEIN | NEIN | 1 | 1560 | 4 | 27g |
Die PT-Methode, nämlich die P-Tuning-Methode, bezieht sich auf den offiziellen Code von Chatglm, ist eine Soft-Prompt-Methode für große Modelle.
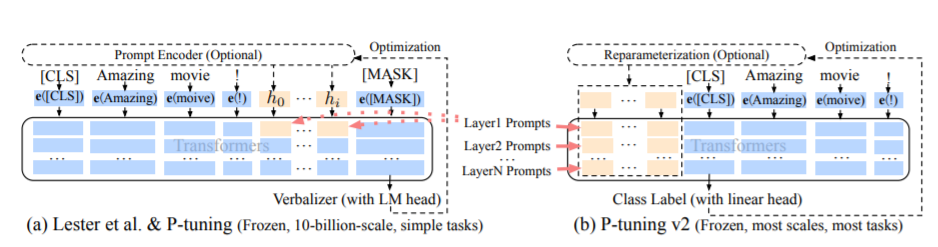
Für den Feinabstimmungscode siehe Train.py, der Kernteil lautet wie folgt:
config = MODE [ args . mode ][ "config" ]. from_pretrained ( args . model_name_or_path )
config . pre_seq_len = args . pre_seq_len
config . prefix_projection = args . prefix_projection
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path , config = config )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in [ "prefix_encoder" ]):
param . requires_grad = FalseWenn Präfix_Projektion wahr ist, werden der Einbettung und jeder Schicht des großen Modells neue Parameter hinzugefügt. Wenn dies falsch ist, werden nur neue Parameter hinzugefügt, nur um das große Modell einzubetten.
Die Trainingscodes werden mit Deepspeed geschult. Die Parameter können festgelegt werden, einschließlich Train_path, model_name_or_path, modus, train_type, pre_seq_len, prefix_projection, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, operation_dir usw. und können nach Ihren Own -Tasks, usw. konfiguriert werden.
Chatglm Einzelkartentraining
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 768
--max_src_len 512
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Chatglm Vier-Karten-Training, CUDA_VISIBLE_DEVICES-Steuerelemente, welche Karten geschult werden. Wenn dieser Parameter nicht hinzugefügt wird, bedeutet dies, dass alle Karten auf der Laufmaschine trainiert werden.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Chatglm2 Einzelkartentraining
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Chatglm2-Vier-Karten-Training, Kontrolle, welche Karten über cuda_visible_devices trainiert werden. Wenn dieser Parameter nicht hinzugefügt wird, bedeutet dies, dass alle Karten auf der Laufmaschine trainiert werden.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Chatglm3 Einzelkartentraining
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
Chatglm3-Vier-Karten-Training, Kontrolle, welche Karten über CUDA_VISIBLE_DEVICES geschult werden. Wenn dieser Parameter nicht hinzugefügt wird, bedeutet dies, dass alle Karten auf der Laufmaschine trainiert werden.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
PS: Der für die Feinabstimmung von Chatglm verwendete Videospeicher ist mehr als der von Chatglm2, und die detaillierten Videospeicherbeschwerden werden Folgendes enthält:
| Modell | Deepspeed-Stufe | Ausladen | Gradientenprüfung | Chargengröße | Maximale Länge | GPU-A40-Nummer | Verbraucher Videospeicher |
|---|---|---|---|---|---|---|---|
| Chaglm | Null2 | NEIN | Ja | 1 | 768 | 1 | 43g |
| Chaglm | Null2 | NEIN | NEIN | 1 | 300 | 1 | 44g |
| Chaglm | Null2 | NEIN | Ja | 1 | 1560 | 4 | 37G |
| Chaglm | Null2 | NEIN | NEIN | 1 | 1360 | 4 | 44g |
| Chaglm2 | Null2 | NEIN | Ja | 1 | 1560 | 1 | 20g |
| Chaglm2 | Null2 | NEIN | NEIN | 1 | 1560 | 1 | 40g |
| Chaglm2 | Null2 | NEIN | Ja | 1 | 1560 | 4 | 19g |
| Chaglm2 | Null2 | NEIN | NEIN | 1 | 1560 | 4 | 39g |
Die LORA-Methode, dh, um den angegebenen Parametern (Gewichtsmatrix) parallel zu großer Sprachmodellen zusätzliche niedrige Matrix hinzuzufügen, und während des Modelltrainings werden nur die zusätzlichen Parameter der parallelen niedrigrangigen Matrix geschult. Wenn der "Rangwert" viel kleiner als die ursprüngliche Parametermessung ist, ist die Anzahl der neu hinzugefügten Matrixparameter mit niedrigem Rang ebenfalls sehr gering. Beim Abtauchen nachgeschalteter Aufgaben müssen nur kleine Parameter geschult werden, aber es können gute Leistungsergebnisse erzielt werden.
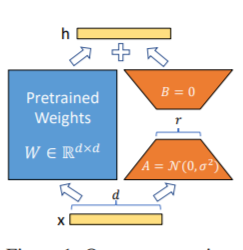
Für den Feinabstimmungscode siehe Train.py, der Kernteil lautet wie folgt:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )
lora_module_name = args . lora_module_name . split ( "," )
config = LoraConfig ( r = args . lora_dim ,
lora_alpha = args . lora_alpha ,
target_modules = lora_module_name ,
lora_dropout = args . lora_dropout ,
bias = "none" ,
task_type = "CAUSAL_LM" ,
inference_mode = False ,
)
model = get_peft_model ( model , config )
model . config . torch_dtype = torch . float32PS: Nach LORA -Training fusionieren Sie bitte zuerst die Parameter und machen Sie Modellvorhersagen.
Die Trainingscodes werden mit Deepspeed geschult. The parameters can be set including train_path, model_name_or_path, mode, train_type, lora_dim, lora_alpha, lora_dropout, lora_module_name, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir, etc., and can be configured according to Ihre eigenen Aufgaben.
Chatglm Einzelkartentraining
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Chatglm Vier-Karten-Training, CUDA_VISIBLE_DEVICES-Steuerelemente, welche Karten geschult werden. Wenn dieser Parameter nicht hinzugefügt wird, bedeutet dies, dass alle Karten auf der Laufmaschine trainiert werden.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Chatglm2 Einzelkartentraining
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Chatglm2-Vier-Karten-Training, Kontrolle, welche Karten über cuda_visible_devices trainiert werden. Wenn dieser Parameter nicht hinzugefügt wird, bedeutet dies, dass alle Karten auf der Laufmaschine trainiert werden.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Chatglm3 Einzelkartentraining
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
Chatglm3-Vier-Karten-Training, Kontrolle, welche Karten über CUDA_VISIBLE_DEVICES geschult werden. Wenn dieser Parameter nicht hinzugefügt wird, bedeutet dies, dass alle Karten auf der Laufmaschine trainiert werden.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: Der für die Feinabstimmung von Chatglm verwendete Videospeicher ist mehr als der von Chatglm2, und die detaillierten Videospeicherbeschwerden werden Folgendes enthält:
| Modell | Deepspeed-Stufe | Ausladen | Gradientenprüfung | Chargengröße | Maximale Länge | GPU-A40-Nummer | Verbraucher Videospeicher |
|---|---|---|---|---|---|---|---|
| Chaglm | Null2 | NEIN | Ja | 1 | 1560 | 1 | 20g |
| Chaglm | Null2 | NEIN | NEIN | 1 | 1560 | 1 | 45G |
| Chaglm | Null2 | NEIN | Ja | 1 | 1560 | 4 | 20g |
| Chaglm | Null2 | NEIN | NEIN | 1 | 1560 | 4 | 45G |
| Chaglm2 | Null2 | NEIN | Ja | 1 | 1560 | 1 | 20g |
| Chaglm2 | Null2 | NEIN | NEIN | 1 | 1560 | 1 | 43g |
| Chaglm2 | Null2 | NEIN | Ja | 1 | 1560 | 4 | 19g |
| Chaglm2 | Null2 | NEIN | NEIN | 1 | 1560 | 4 | 42g |
HINWEIS: Die LORA -Methode speichert nur die LORA -Trainingsparameter beim Speichern des Modells, sodass die Modellparameter bei der Vorhersage des Modells zusammengeführt werden müssen. Weitere Informationen finden Sie unter merge_lora.py.
Die vollständige Parametermethode wird verwendet, um das große Modell in vollständigen Parametern zu trainieren. Es wird hauptsächlich die DeepSpeed-Zero3-Methode verwendet, um die Modellparameter in mehrere Karten zu unterteilen, und die Offload-Methode zum Entladen der Optimiererparameter in die CPU zur Lösung des Problems unzureichender Grafikkarten.
Für den Feinabstimmungscode siehe Train.py, der Kernteil lautet wie folgt:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )Die Trainingscodes werden mit Deepspeed geschult. Die Parameter können eingestellt werden, einschließlich Train_path, model_name_or_path, modus, train_type, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir usw., die nach Ihrer eigenen Aufgabe konfiguriert werden können.
Chatglm Vier-Karten-Training, CUDA_VISIBLE_DEVICES-Steuerelemente, welche Karten geschult werden. Wenn dieser Parameter nicht hinzugefügt wird, bedeutet dies, dass alle Karten auf der Laufmaschine trainiert werden.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type all
--seed 1234
--ds_file ds_zero3_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Chatglm2-Vier-Karten-Training, Kontrolle, welche Karten über cuda_visible_devices trainiert werden. Wenn dieser Parameter nicht hinzugefügt wird, bedeutet dies, dass alle Karten auf der Laufmaschine trainiert werden.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Chatglm3-Vier-Karten-Training, Kontrolle, welche Karten über CUDA_VISIBLE_DEVICES geschult werden. Wenn dieser Parameter nicht hinzugefügt wird, bedeutet dies, dass alle Karten auf der Laufmaschine trainiert werden.
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: Der für die Feinabstimmung von Chatglm verwendete Videospeicher ist mehr als der von Chatglm2, und die detaillierten Videospeicherbeschwerden werden Folgendes enthält:
| Modell | Deepspeed-Stufe | Ausladen | Gradientenprüfung | Chargengröße | Maximale Länge | GPU-A40-Nummer | Verbraucher Videospeicher |
|---|---|---|---|---|---|---|---|
| Chaglm | Null3 | Ja | Ja | 1 | 1560 | 4 | 33g |
| Chaglm2 | Null3 | NEIN | Ja | 1 | 1560 | 4 | 44g |
| Chaglm2 | Null3 | Ja | Ja | 1 | 1560 | 4 | 26g |
Das Folgende ist eine Beschreibung des relevanten Inhalts von DeepSpeeds Nullstufe.
Anforderungen anzeigen.txt Datei
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为"性能故障", "部件故障", "组成"和 "检测工具"的相关三元组,三元组内部用"_"连接,三元组之间用\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高n风扇_部件故障_低速转动"
}
| Feinabstimmungsmethode | PT-Nur-Embedding | Pt | Einfrieren | Lora |
|---|---|---|---|---|
| Testergebnisse F1 | 0,0 | 0,6283 | 0,5675 | 0,5359 |
Strukturanalyse:
Viele Schüler erlebten katastrophale Vergessen nach der Feinabstimmung, aber der Trainingscode dieses Projekts erschien nicht. Sie testeten die "Übersetzungsaufgabe", "Codeaufgabe" und "Frage und Antwortaufgabe". Die spezifischen Testergebnisse sind wie folgt:


{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
Da der Inhalt des generativen Modells nicht wie die Aufgabe zur Informationsextraktion bewertet werden kann, ist es nicht angemessen, vorhandene Blau oder Rouge zur Bewertung zu verwenden, sodass eine Bewertungsregel formuliert wurde. Das D2Q -Modell wird anhand der beiden Perspektiven von Vielfalt und Genauigkeit beurteilt. Jede Probe hat insgesamt 5 Punkte mit insgesamt 20 Proben.
| Feinabstimmungsmethode | Originalmodell | PT-Nur-Embedding | Pt | Einfrieren | Lora |
|---|---|---|---|---|---|
| Fraktion | 51.75 | 73,75 | 87.75 | 79,25 | 86,75 |
Siehe Code Beschreibung: Pipeline Parallelism (Pipeline) Praxis
Bitte beachten Sie das V0.1 -Tag


