ChatGLM Finetuning
v0.1
Этот проект в основном выполняет точную настройку по-разному (метод замораживания, метод LORA, метод P-подключения, полные параметры и т. Д.) Для моделей ChatGLM, ChatGLM2 и ChatGLM3, и сравнивает влияние большой модели на различные методы тонкой настройки, в основном нацеливание задач извлечения информации, задачи генерации, классификационных Tasks и т. Д.
Этот проект поддерживает обучение однократным карточкам и обучение с несколькими картами. Из-за единой настройки инструкций не существует серьезных катастрофических забываний после точной настройки модели.
Поскольку официальный код и модель были обновлены, текущий код и модель Chatglm1 и 2-версия 20230806 (обратите внимание, что если код работает неправильно, вы можете заменить файл PY в файле с помощью исходного кода, связанного с ChatGLM, потому что версия модели, под которой вы находитесь, может быть несоответствующим с кодовой версией этого проекта). Chatglm3 - версия 20231212.
PS: Тренер не используется (хотя код тренера прост, его нелегко изменить. В эпоху крупных моделей инженеры по алгоритмам стали инженерами данных, поэтому им необходимо больше понимать процесс обучения)
При тонкой настройке модели, если есть недостаточная видео память, вы можете включить такие параметры, как gradient_checkpointing, Zero3 и разгрузка, чтобы сохранить видео память.
Следующий параметр MODEL_NAME_OR_PATH - это путь модели. Пожалуйста, измените его в соответствии с адресом, который вы можете сохранить в соответствии с вашей реальной моделью.
Метод замораживания, то есть замораживание параметров, и некоторые параметры заморожены для исходной модели, и только некоторые параметры обучаются для достижения отдельных или нескольких карт. Если операция TP или PP не выполнена, большая модель может быть обучена.
Для точной настройки, см. Train.py, основная часть заключается в следующем:
freeze_module_name = args . freeze_module_name . split ( "," )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in freeze_module_name ):
param . requires_grad = FalseДля модификаций на разные слои модели вы можете самостоятельно изменить конфигурацию параметра freeze_module_name, например, «слои.27., слои.26., Слои.25., Слои.24». Все тренировочные коды обучаются с использованием DeepSpeed. Параметры могут быть установлены, включая Train_path, model_name_or_path, mode, train_type, freeze_module_name, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir и т. Д., И можно конфигурировать в соответствии с вашими собственными tasks.
Обучение с одним картом Chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Четырехкарточная обучение Chatglm, CUDA_VISIBLE_DEVICES Управляет, какие карты обучены. Если этот параметр не добавлен, это означает, что все карты на работающей машине обучены.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Обучение однократным картам Chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Четырехкарточная обучение Chatglm2, контроль, какие карты обучаются через cuda_visible_devices. Если этот параметр не добавлен, это означает, что все карты на работающей машине обучены.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Обучение однократным картам Chatglm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
CHATGLM3 Обучение с четырьмя картами, контроль, какие карты обучаются через cuda_visible_devices. Если этот параметр не добавлен, это означает, что все карты на работающей машине обучены.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: видео память, используемая для точной настройки ChatGLM, больше, чем у ChatGlm2, и подробные учетные записи памяти для следующего:
| Модель | Стадия Deepspeed | Разгрузка | Градиент контрольно -пропускной пункт | Размер партии | Максимальная длина | GPU-A40 номер | Потребляется видео память |
|---|---|---|---|---|---|---|---|
| Chaglm | Zero2 | Нет | Да | 1 | 1560 | 1 | 36G |
| Chaglm | Zero2 | Нет | Нет | 1 | 1560 | 1 | 38 г |
| Chaglm | Zero2 | Нет | Да | 1 | 1560 | 4 | 24G |
| Chaglm | Zero2 | Нет | Нет | 1 | 1560 | 4 | 29G |
| Chaglm2 | Zero2 | Нет | Да | 1 | 1560 | 1 | 35 г |
| Chaglm2 | Zero2 | Нет | Нет | 1 | 1560 | 1 | 36G |
| Chaglm2 | Zero2 | Нет | Да | 1 | 1560 | 4 | 22G |
| Chaglm2 | Zero2 | Нет | Нет | 1 | 1560 | 4 | 27G |
Метод PT, а именно метод P-подключения, относится к официальному коду Chatglm, является методом мягкого производства для больших моделей.
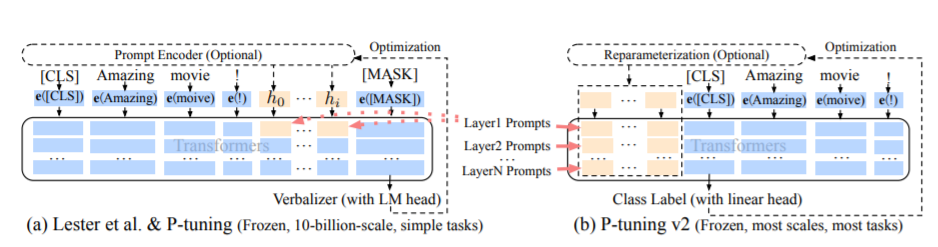
Для точной настройки, см. Train.py, основная часть заключается в следующем:
config = MODE [ args . mode ][ "config" ]. from_pretrained ( args . model_name_or_path )
config . pre_seq_len = args . pre_seq_len
config . prefix_projection = args . prefix_projection
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path , config = config )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in [ "prefix_encoder" ]):
param . requires_grad = FalseКогда префикс_проректификация правда, новые параметры добавляются в внедрение и каждый слой большой модели; Когда ложно, новые параметры добавляются только к внедрению большой модели.
Учебные коды обучаются с использованием DeepSpeed. Параметры могут быть установлены, включая Train_path, model_name_or_path, mode, train_type, pre_seq_len, prefix_projection, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir, и т. Д., И и может быть в соответствии с вами.
Обучение с одним картом Chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 768
--max_src_len 512
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Четырехкарточная обучение Chatglm, CUDA_VISIBLE_DEVICES Управляет, какие карты обучены. Если этот параметр не добавлен, это означает, что все карты на работающей машине обучены.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Обучение однократным картам Chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Четырехкарточная обучение Chatglm2, контроль, какие карты обучаются через cuda_visible_devices. Если этот параметр не добавлен, это означает, что все карты на работающей машине обучены.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Обучение однократным картам Chatglm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
CHATGLM3 Обучение с четырьмя картами, контроль, какие карты обучаются через cuda_visible_devices. Если этот параметр не добавлен, это означает, что все карты на работающей машине обучены.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
PS: видео память, используемая для точной настройки ChatGLM, больше, чем у ChatGlm2, и подробные учетные записи памяти для следующего:
| Модель | Стадия Deepspeed | Разгрузка | Градиент контрольно -пропускной пункт | Размер партии | Максимальная длина | GPU-A40 номер | Потребляется видео память |
|---|---|---|---|---|---|---|---|
| Chaglm | Zero2 | Нет | Да | 1 | 768 | 1 | 43 г |
| Chaglm | Zero2 | Нет | Нет | 1 | 300 | 1 | 44 г |
| Chaglm | Zero2 | Нет | Да | 1 | 1560 | 4 | 37G |
| Chaglm | Zero2 | Нет | Нет | 1 | 1360 | 4 | 44 г |
| Chaglm2 | Zero2 | Нет | Да | 1 | 1560 | 1 | 20 г |
| Chaglm2 | Zero2 | Нет | Нет | 1 | 1560 | 1 | 40 г |
| Chaglm2 | Zero2 | Нет | Да | 1 | 1560 | 4 | 19G |
| Chaglm2 | Zero2 | Нет | Нет | 1 | 1560 | 4 | 39 г |
Метод LORA, то есть добавить дополнительную матрицу с низким уровнем ранга в указанные параметры (матрица веса) параллельно на больших языковых моделях, и во время обучения модели обучаются только дополнительные параллельные параллельные параллельные низкопорядочные матрицы. Когда «значение ранга» намного меньше исходного размера параметра, количество недавно добавленных параметров матрицы с низким уровнем ранга также очень мало. При настройке вниз по течению задач необходимо обучить только небольшие параметры, но можно получить хорошие результаты производительности.
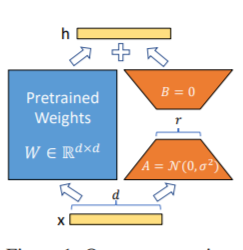
Для точной настройки, см. Train.py, основная часть заключается в следующем:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )
lora_module_name = args . lora_module_name . split ( "," )
config = LoraConfig ( r = args . lora_dim ,
lora_alpha = args . lora_alpha ,
target_modules = lora_module_name ,
lora_dropout = args . lora_dropout ,
bias = "none" ,
task_type = "CAUSAL_LM" ,
inference_mode = False ,
)
model = get_peft_model ( model , config )
model . config . torch_dtype = torch . float32PS: После обучения LORA, пожалуйста, сначала объедините параметры и сделайте прогнозы модели.
Учебные коды обучаются с использованием DeepSpeed. Параметры могут быть установлены, включая Train_path, model_name_or_path, mode, train_type, lora_dim, lora_alpha, lora_dropout, lora_module_name, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_step, per_device_train_batch_size, gradient_accumulation_steps. собственные задачи.
Обучение с одним картом Chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Четырехкарточная обучение Chatglm, CUDA_VISIBLE_DEVICES Управляет, какие карты обучены. Если этот параметр не добавлен, это означает, что все карты на работающей машине обучены.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Обучение однократным картам Chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Четырехкарточная обучение Chatglm2, контроль, какие карты обучаются через cuda_visible_devices. Если этот параметр не добавлен, это означает, что все карты на работающей машине обучены.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Обучение однократным картам Chatglm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
CHATGLM3 Обучение с четырьмя картами, контроль, какие карты обучаются через cuda_visible_devices. Если этот параметр не добавлен, это означает, что все карты на работающей машине обучены.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: видео память, используемая для точной настройки ChatGLM, больше, чем у ChatGlm2, и подробные учетные записи памяти для следующего:
| Модель | Стадия Deepspeed | Разгрузка | Градиент контрольно -пропускной пункт | Размер партии | Максимальная длина | GPU-A40 номер | Потребляется видео память |
|---|---|---|---|---|---|---|---|
| Chaglm | Zero2 | Нет | Да | 1 | 1560 | 1 | 20 г |
| Chaglm | Zero2 | Нет | Нет | 1 | 1560 | 1 | 45 г |
| Chaglm | Zero2 | Нет | Да | 1 | 1560 | 4 | 20 г |
| Chaglm | Zero2 | Нет | Нет | 1 | 1560 | 4 | 45 г |
| Chaglm2 | Zero2 | Нет | Да | 1 | 1560 | 1 | 20 г |
| Chaglm2 | Zero2 | Нет | Нет | 1 | 1560 | 1 | 43 г |
| Chaglm2 | Zero2 | Нет | Да | 1 | 1560 | 4 | 19G |
| Chaglm2 | Zero2 | Нет | Нет | 1 | 1560 | 4 | 42G |
ПРИМЕЧАНИЕ. Метод LORA сохраняет учебные параметры LORA только при сохранении модели, поэтому параметры модели должны быть объединены при прогнозировании модели. Для получения подробной информации, пожалуйста, обратитесь к merge_lora.py.
Полный метод параметров используется для обучения большой модели в полных параметрах. В основном он использует метод DeepSpeed-Zero3 для разделения параметров модели на несколько карт, и использует метод разгрузки для выгрузки параметров оптимизатора в ЦП, чтобы решить проблему недостаточных графических карт.
Для точной настройки, см. Train.py, основная часть заключается в следующем:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )Учебные коды обучаются с использованием DeepSpeed. Параметры могут быть установлены, включая Train_path, model_name_or_path, mode, train_type, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir и т. Д., Которые можно настроить в соответствии с вашей собственной задачей.
Четырехкарточная обучение Chatglm, CUDA_VISIBLE_DEVICES Управляет, какие карты обучены. Если этот параметр не добавлен, это означает, что все карты на работающей машине обучены.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type all
--seed 1234
--ds_file ds_zero3_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Четырехкарточная обучение Chatglm2, контроль, какие карты обучаются через cuda_visible_devices. Если этот параметр не добавлен, это означает, что все карты на работающей машине обучены.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
CHATGLM3 Обучение с четырьмя картами, контроль, какие карты обучаются через cuda_visible_devices. Если этот параметр не добавлен, это означает, что все карты на работающей машине обучены.
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: видео память, используемая для точной настройки ChatGLM, больше, чем у ChatGlm2, и подробные учетные записи памяти для следующего:
| Модель | Стадия Deepspeed | Разгрузка | Градиент контрольно -пропускной пункт | Размер партии | Максимальная длина | GPU-A40 номер | Потребляется видео память |
|---|---|---|---|---|---|---|---|
| Chaglm | Zero3 | Да | Да | 1 | 1560 | 4 | 33G |
| Chaglm2 | Zero3 | Нет | Да | 1 | 1560 | 4 | 44 г |
| Chaglm2 | Zero3 | Да | Да | 1 | 1560 | 4 | 26 г |
Ниже приведено описание соответствующего содержания нулевой стадии DeepSpeed.
Просмотреть требования
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为"性能故障", "部件故障", "组成"和 "检测工具"的相关三元组,三元组内部用"_"连接,三元组之间用\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高n风扇_部件故障_低速转动"
}
| Метод тонкой настройки | ПТ-только-вручение | Пт | Заморозить | Лора |
|---|---|---|---|---|
| Результаты теста F1 | 0,0 | 0,6283 | 0,5675 | 0,5359 |
Структурный анализ:
Многие студенты испытали катастрофическое забывание после точной настройки, но код обучения этого проекта не появился. Они проверили «Задача перевода», «Задача кода» и «Задача вопросов и ответа». Конкретные результаты теста следующие:


{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
Поскольку содержание генеративной модели не может быть оценено, как задача извлечения информации, для оценки существующего синего или роуж не подходит, поэтому было сформулировано правило оценки. Модель D2Q осуждается с помощью двух перспектив разнообразия и точности. Каждый образец имеет в общей сложности 5 баллов, в общей сложности 20 образцов.
| Метод тонкой настройки | Оригинальная модель | ПТ-только-вручение | Пт | Заморозить | Лора |
|---|---|---|---|---|---|
| Фракция | 51.75 | 73,75 | 87,75 | 79,25 | 86,75 |
См. Описание кода: Практика параллелизма трубопровода (трубопровод)
См. Tag v0.1


