ChatGLM Finetuning
v0.1
Este proyecto realiza principalmente ajustes de diferentes maneras (método de congelación, método Lora, método de ajuste P, parámetros completos, etc.) para los modelos CHATGLM, CHATGLM2 y CHATGLM3, y compara los efectos del modelo grande en diferentes métodos de ajuste fino, dirigiendo principalmente tareas de extracción de información, tareas de generación, tareas de clasificación, etc. etc. etc.
Este proyecto admite capacitación de una sola tarjeta y capacitación en múltiples tarjetas. Debido al ajuste de instrucción única, no hay un olvido catastrófico serio después del ajuste del modelo.
Dado que el código y el modelo oficial se han actualizado, el código actual y el modelo de ChatGlm1 y 2 son la versión 20230806 (tenga en cuenta que si el código se ejecuta incorrectamente, puede reemplazar el archivo PY en el archivo con el código fuente relacionado con el CHATGLM, porque la versión del modelo en el que se encuentra puede ser inconsistente con la versión del código de este proyecto). ChatGlm3 es la versión 20231212.
PD: No se usa el entrenador (aunque el código del entrenador es simple, no es fácil de modificar. En la era de los grandes modelos, los ingenieros de algoritmo se han convertido en ingenieros de datos, por lo que deben comprender más el proceso de entrenamiento)
Al ajustar el modelo, si no hay suficiente memoria de video, puede activar parámetros como gradiente_checkpointing, Zero3, y descargar para guardar la memoria de video.
El siguiente parámetro model_name_or_path es la ruta del modelo. Modifíquelo de acuerdo con la dirección que puede guardar de acuerdo con su modelo real.
El método de congelación, es decir, los parámetros se congelan, y algunos parámetros están congelados para el modelo original, y solo algunos parámetros están entrenados para lograr tarjetas simples o múltiples. Si no se realiza la operación TP o PP, el modelo grande puede ser entrenado.
Para el código de ajuste fino, ver Train.py, la parte central es la siguiente:
freeze_module_name = args . freeze_module_name . split ( "," )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in freeze_module_name ):
param . requires_grad = FalsePara modificaciones a diferentes capas del modelo, puede modificar la configuración de parámetros Freeze_Module_Name usted mismo, como "Capas.27., Capas.26., Capas.25., Capas.24". Todos los códigos de entrenamiento están entrenados con una velocidad profunda. Los parámetros se pueden establecer que incluya Train_Path, Model_name_or_path, Mode, Train_Type, Freeze_Module_Name, DS_File, Num_Train_Epochs, per_device_train_batch_size, gradiente_accumulación_steps, salida_dir, etc., y se puede configurar de acuerdo con sus propias tareas.
Entrenamiento de tarjetas individuales de chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Entrenamiento de cuatro tarjetas CHATGLM, controles CUDA_VISIBLE_DEVICES qué tarjetas están entrenadas. Si no se agrega este parámetro, significa que todas las tarjetas en la máquina en ejecución están entrenadas.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
CHATGLM2 Capacitación de tarjetas individuales
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Entrenamiento de cuatro tarjetas CHATGLM2, control qué tarjetas se entrenan a través de CUDA_VISIBLE_DEVICES. Si no se agrega este parámetro, significa que todas las tarjetas en la máquina en ejecución están entrenadas.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
CHATGLM3 Capacitación de tarjetas individuales
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
CHATGLM3 Entrenamiento de cuatro cartas, control qué tarjetas se entrenan a través de CUDA_VISIBLE_DEVICES. Si no se agrega este parámetro, significa que todas las tarjetas en la máquina en ejecución están entrenadas.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PD: La memoria de video utilizada para el ajuste de chatglm es más que la de ChatGlm2, y la memoria de video detallada representa lo siguiente:
| Modelo | Estribo | Descargar | Punta de control de gradiente | Tamaño por lotes | Longitud máxima | Número de GPU-A40 | Memoria de video consumida |
|---|---|---|---|---|---|---|---|
| Chaglm | cero2 | No | Sí | 1 | 1560 | 1 | 36G |
| Chaglm | cero2 | No | No | 1 | 1560 | 1 | 38g |
| Chaglm | cero2 | No | Sí | 1 | 1560 | 4 | 24 g |
| Chaglm | cero2 | No | No | 1 | 1560 | 4 | 29G |
| Chaglm2 | cero2 | No | Sí | 1 | 1560 | 1 | 35g |
| Chaglm2 | cero2 | No | No | 1 | 1560 | 1 | 36G |
| Chaglm2 | cero2 | No | Sí | 1 | 1560 | 4 | 22G |
| Chaglm2 | cero2 | No | No | 1 | 1560 | 4 | 27G |
El método PT, a saber, el método de ajuste P, se refiere al código oficial de ChatGLM, es un método de promutación suave para modelos grandes.
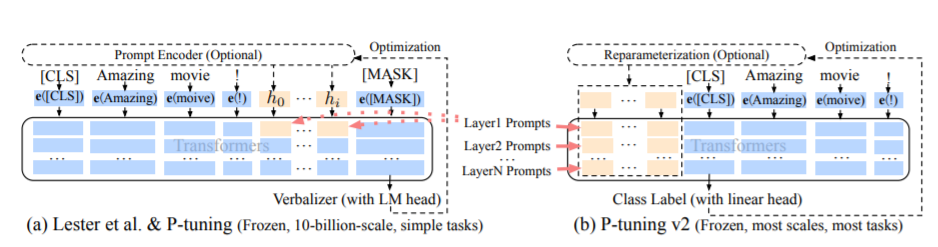
Para el código de ajuste fino, ver Train.py, la parte central es la siguiente:
config = MODE [ args . mode ][ "config" ]. from_pretrained ( args . model_name_or_path )
config . pre_seq_len = args . pre_seq_len
config . prefix_projection = args . prefix_projection
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path , config = config )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in [ "prefix_encoder" ]):
param . requires_grad = FalseCuando prefix_proyección es verdadero, se agregan nuevos parámetros a la incrustación y cada capa del modelo grande; Cuando se falsa, se agregan nuevos parámetros a la incrustación del modelo grande solamente.
Los códigos de entrenamiento se entrenan con una velocidad profunda. Los parámetros se pueden establecer que incluya Train_Path, Model_name_or_path, Mode, Train_Type, Pre_Seq_Len, Prefix_Proyección, DS_FILE, NUM_TRAIN_EPOCHS, Per_device_Train_Batch_Size, Gradient_Accumulation_steps, output_dir, etc., y se puede configurar de acuerdo con la tarea de según la tarea.
Entrenamiento de tarjetas individuales de chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 768
--max_src_len 512
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Entrenamiento de cuatro tarjetas CHATGLM, controles CUDA_VISIBLE_DEVICES qué tarjetas están entrenadas. Si no se agrega este parámetro, significa que todas las tarjetas en la máquina en ejecución están entrenadas.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
CHATGLM2 Capacitación de tarjetas individuales
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Entrenamiento de cuatro tarjetas CHATGLM2, control qué tarjetas se entrenan a través de CUDA_VISIBLE_DEVICES. Si no se agrega este parámetro, significa que todas las tarjetas en la máquina en ejecución están entrenadas.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
CHATGLM3 Capacitación de tarjetas individuales
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
CHATGLM3 Entrenamiento de cuatro cartas, control qué tarjetas se entrenan a través de CUDA_VISIBLE_DEVICES. Si no se agrega este parámetro, significa que todas las tarjetas en la máquina en ejecución están entrenadas.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
PD: La memoria de video utilizada para el ajuste de chatglm es más que la de ChatGlm2, y la memoria de video detallada representa lo siguiente:
| Modelo | Estribo | Descargar | Punta de control de gradiente | Tamaño por lotes | Longitud máxima | Número de GPU-A40 | Memoria de video consumida |
|---|---|---|---|---|---|---|---|
| Chaglm | cero2 | No | Sí | 1 | 768 | 1 | 43g |
| Chaglm | cero2 | No | No | 1 | 300 | 1 | 44G |
| Chaglm | cero2 | No | Sí | 1 | 1560 | 4 | 37G |
| Chaglm | cero2 | No | No | 1 | 1360 | 4 | 44G |
| Chaglm2 | cero2 | No | Sí | 1 | 1560 | 1 | 20G |
| Chaglm2 | cero2 | No | No | 1 | 1560 | 1 | 40 g |
| Chaglm2 | cero2 | No | Sí | 1 | 1560 | 4 | 19G |
| Chaglm2 | cero2 | No | No | 1 | 1560 | 4 | 39G |
El método Lora, es decir, para agregar una matriz adicional de bajo rango a los parámetros especificados (matriz de peso) en paralelo en modelos de lenguaje grande, y durante el entrenamiento de modelos, solo se entrenan los parámetros adicionales de la matriz de bajo rango paralelo. Cuando el "valor de rango" es mucho más pequeño que la dimensión del parámetro original, el número de parámetros de matriz de bajo rango recién agregados también es muy pequeño. Al ajustar las tareas aguas abajo, solo se deben capacitar pequeños parámetros, pero se pueden obtener buenos resultados de rendimiento.
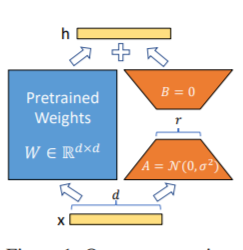
Para el código de ajuste fino, ver Train.py, la parte central es la siguiente:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )
lora_module_name = args . lora_module_name . split ( "," )
config = LoraConfig ( r = args . lora_dim ,
lora_alpha = args . lora_alpha ,
target_modules = lora_module_name ,
lora_dropout = args . lora_dropout ,
bias = "none" ,
task_type = "CAUSAL_LM" ,
inference_mode = False ,
)
model = get_peft_model ( model , config )
model . config . torch_dtype = torch . float32PD: Después de la capacitación de Lora, fusione los parámetros primero y haga predicciones del modelo.
Los códigos de entrenamiento se entrenan con una velocidad profunda. Los parámetros se pueden establecer que incluya Train_Path, Model_name_or_path, Mode, Train_Type, Lora_dim, Lora_alpha, Lora_Dropout, Lora_Module_Name, DS_File, num_train_epochs, per_device_train_batch_size, gradiente_accumulation_steps, y puede ser, etc., y puede ser, y puede ser, y puede ser, y puede ser, y puede ser, y puede ser, y puede ser, y puede ser, y puede ser, y puede ser, y. configurado de acuerdo con sus propias tareas.
Entrenamiento de tarjetas individuales de chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Entrenamiento de cuatro tarjetas CHATGLM, controles CUDA_VISIBLE_DEVICES qué tarjetas están entrenadas. Si no se agrega este parámetro, significa que todas las tarjetas en la máquina en ejecución están entrenadas.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
CHATGLM2 Capacitación de tarjetas individuales
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Entrenamiento de cuatro tarjetas CHATGLM2, control qué tarjetas se entrenan a través de CUDA_VISIBLE_DEVICES. Si no se agrega este parámetro, significa que todas las tarjetas en la máquina en ejecución están entrenadas.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
CHATGLM3 Capacitación de tarjetas individuales
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
CHATGLM3 Entrenamiento de cuatro cartas, control qué tarjetas se entrenan a través de CUDA_VISIBLE_DEVICES. Si no se agrega este parámetro, significa que todas las tarjetas en la máquina en ejecución están entrenadas.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PD: La memoria de video utilizada para el ajuste de chatglm es más que la de ChatGlm2, y la memoria de video detallada representa lo siguiente:
| Modelo | Estribo | Descargar | Punta de control de gradiente | Tamaño por lotes | Longitud máxima | Número de GPU-A40 | Memoria de video consumida |
|---|---|---|---|---|---|---|---|
| Chaglm | cero2 | No | Sí | 1 | 1560 | 1 | 20G |
| Chaglm | cero2 | No | No | 1 | 1560 | 1 | 45g |
| Chaglm | cero2 | No | Sí | 1 | 1560 | 4 | 20G |
| Chaglm | cero2 | No | No | 1 | 1560 | 4 | 45g |
| Chaglm2 | cero2 | No | Sí | 1 | 1560 | 1 | 20G |
| Chaglm2 | cero2 | No | No | 1 | 1560 | 1 | 43g |
| Chaglm2 | cero2 | No | Sí | 1 | 1560 | 4 | 19G |
| Chaglm2 | cero2 | No | No | 1 | 1560 | 4 | 42G |
Nota: El método Lora solo guarda los parámetros de entrenamiento LORA al guardar el modelo, por lo que los parámetros del modelo deben fusionarse al predecir el modelo. Para más detalles, consulte Merge_lora.py.
El método de parámetro completo se utiliza para entrenar el modelo grande en parámetros completos. Utiliza principalmente el método Deepeed-Zero3 para dividir los parámetros del modelo en múltiples tarjetas, y utiliza el método de descarga para descargar los parámetros de optimizador a la CPU para resolver el problema de las tarjetas gráficas insuficientes.
Para el código de ajuste fino, ver Train.py, la parte central es la siguiente:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )Los códigos de entrenamiento se entrenan con una velocidad profunda. Los parámetros se pueden establecer que incluya Train_Path, Model_name_or_path, Mode, Train_Type, DS_File, Num_Train_Epochs, Per_device_Train_Batch_Size, Gradient_Accumulation_steps, Output_dir, etc., que se puede configurar de acuerdo con su propia tarea.
Entrenamiento de cuatro tarjetas CHATGLM, controles CUDA_VISIBLE_DEVICES qué tarjetas están entrenadas. Si no se agrega este parámetro, significa que todas las tarjetas en la máquina en ejecución están entrenadas.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type all
--seed 1234
--ds_file ds_zero3_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Entrenamiento de cuatro tarjetas CHATGLM2, control qué tarjetas se entrenan a través de CUDA_VISIBLE_DEVICES. Si no se agrega este parámetro, significa que todas las tarjetas en la máquina en ejecución están entrenadas.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
CHATGLM3 Entrenamiento de cuatro cartas, control qué tarjetas se entrenan a través de CUDA_VISIBLE_DEVICES. Si no se agrega este parámetro, significa que todas las tarjetas en la máquina en ejecución están entrenadas.
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PD: La memoria de video utilizada para el ajuste de chatglm es más que la de ChatGlm2, y la memoria de video detallada representa lo siguiente:
| Modelo | Estribo | Descargar | Punta de control de gradiente | Tamaño por lotes | Longitud máxima | Número de GPU-A40 | Memoria de video consumida |
|---|---|---|---|---|---|---|---|
| Chaglm | cero3 | Sí | Sí | 1 | 1560 | 4 | 33G |
| Chaglm2 | cero3 | No | Sí | 1 | 1560 | 4 | 44G |
| Chaglm2 | cero3 | Sí | Sí | 1 | 1560 | 4 | 26G |
La siguiente es una descripción del contenido relevante de la etapa cero de DeepSpeed.
Ver requisitos.txt archivo
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为"性能故障", "部件故障", "组成"和 "检测工具"的相关三元组,三元组内部用"_"连接,三元组之间用\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高n风扇_部件故障_低速转动"
}
| Método de ajuste | Pt-solo incrustación | PT | Congelar | Lora |
|---|---|---|---|---|
| Resultados de la prueba F1 | 0.0 | 0.6283 | 0.5675 | 0.5359 |
Análisis estructural:
Muchos estudiantes experimentaron un olvido catastrófico después del ajuste fino, pero el código de entrenamiento de este proyecto no apareció. Probaron la "tarea de traducción", la "tarea de código" y la "tarea de preguntas y respuestas". Los resultados de la prueba específicos son los siguientes:


{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
Dado que el contenido del modelo generativo no puede evaluarse como la tarea de extracción de información, no es apropiado usar azul o rojo existente para evaluar, por lo que se formuló una regla de puntuación. El modelo D2Q se juzga a través de las dos perspectivas de diversidad y precisión. Cada muestra tiene un total de 5 puntos, con un total de 20 muestras.
| Método de ajuste | Modelo original | Pt-solo incrustación | PT | Congelar | Lora |
|---|---|---|---|---|---|
| Fracción | 51.75 | 73.75 | 87.75 | 79.25 | 86.75 |
Consulte la descripción del código: práctica de paralelismo de tubería (tubería)
Consulte la etiqueta V0.1


