ChatGLM Finetuning
v0.1
يقوم هذا المشروع بشكل أساسي بعملية ضبطها بطرق مختلفة (طريقة التجميد ، طريقة Lora ، طريقة صقل p ، المعلمات الكاملة ، وما إلى ذلك) لنماذج ChatGlm ، ChatGlm2 و chatGlm3 ، ويقارن تأثيرات النموذج الكبير على طرق التماثيل الدقيقة المختلفة ، واستهداف مهام استخراج المعلومات بشكل رئيسي ، ومموعات التوليد ، ومخططات التصنيف ، إلخ ، إلخ.
يدعم هذا المشروع التدريب على البطاقة الواحدة والتدريب متعدد البطاقات. نظرًا لتعليم التعليمات الفردية ، لا يوجد نسيان خطيرة بعد النسيان بعد صقل النموذج.
نظرًا لأن الكود الرسمي والنموذج قد تم تحديثهما ، فإن الكود الحالي ونموذج chatGLM1 و 2 هو الإصدار 20230806 (لاحظ أنه إذا كان الكود يعمل بشكل غير صحيح ، فيمكنك استبدال ملف PY في الملف برمز المصدر المتعلق بـ ChatGLM ، لأن إصدار النموذج الذي تخضع إليه قد لا يتفق مع إصدار الكود من هذا المشروع). ChatGlm3 هو الإصدار 20231212.
ملاحظة: لا يوجد فائدة من المدرب (على الرغم من أن رمز المدرب بسيط ، إلا أنه ليس من السهل تعديله. في عصر النماذج الكبيرة ، أصبح مهندسو الخوارزمية مهندسين للبيانات ، لذلك يحتاجون إلى فهم عملية التدريب أكثر)
عند ضبط النموذج ، إذا لم يكن هناك ذاكرة فيديو كافية ، فيمكنك تشغيل معلمات مثل Gradient_CheckPointing و Zero3 و Offload لحفظ ذاكرة الفيديو.
معلمة model_name_or_path التالية هي مسار النموذج. يرجى تعديله وفقًا للعنوان الذي يمكنك حفظه وفقًا لنموذجك الفعلي.
طريقة التجميد ، أي تجميد المعلمة ، ويتم تجميد بعض المعلمات للنموذج الأصلي ، ويتم تدريب بعض المعلمات فقط لتحقيق بطاقات واحدة أو متعددة. إذا لم يتم تنفيذ عملية TP أو PP ، فيمكن تدريب النموذج الكبير.
للاطلاع على رمز الضبط ، انظر Train.py ، الجزء الأساسي هو كما يلي:
freeze_module_name = args . freeze_module_name . split ( "," )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in freeze_module_name ):
param . requires_grad = Falseللحصول على تعديلات على طبقات مختلفة من النموذج ، يمكنك تعديل تكوين المعلمة freeze_module_name بنفسك ، مثل "الطبقات 27. ، الطبقات 26. ، الطبقات. يتم تدريب جميع رموز التدريب باستخدام السرعة العميقة. يمكن تعيين المعلمات بما في ذلك Train_Path ، model_name_or_path ، mode ، train_type ، freeze_module_name ، ds_file ، num_train_epochs ، per_device_train_batch_size ، gradient_accumulation_steps ، output_dir ، وما إلى ذلك ، ويمكن تكوينها وفقًا للمغذيات الخاصة.
ChatGlm تدريب بطاقة واحدة
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
تدريب ChatGlm من أربع بطاقة ، CUDA_VISIBLE_DEVICES عناصر التحكم التي يتم تدريب البطاقات. إذا لم تتم إضافة هذه المعلمة ، فهذا يعني أن جميع البطاقات الموجودة على جهاز الجري يتم تدريبها.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGlm2 تدريب بطاقة واحدة
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
تدريب chatglm2 من أربع بطاقة ، والتحكم الذي يتم تدريب البطاقات من خلال cuda_visible_devices. إذا لم تتم إضافة هذه المعلمة ، فهذا يعني أن جميع البطاقات الموجودة على جهاز الجري يتم تدريبها.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGlm3 تدريب بطاقة واحدة
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
ChatGlm3 التدريب الأربع بطاقات ، والتحكم الذي يتم تدريب البطاقات من خلال CUDA_VISIBLE_DEVICES. إذا لم تتم إضافة هذه المعلمة ، فهذا يعني أن جميع البطاقات الموجودة على جهاز الجري يتم تدريبها.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
ملاحظة: إن ذاكرة الفيديو المستخدمة في صقل ChatGLM هي أكثر من تلك الخاصة بـ ChatGLM2 ، وحسابات ذاكرة الفيديو التفصيلية لما يلي:
| نموذج | مرحلة السرعة العميقة | تفريغ | التدرج checkpointing | حجم الدُفعة | الحد الأقصى طول | رقم GPU-A40 | ذاكرة الفيديو المستهلكة |
|---|---|---|---|---|---|---|---|
| chaglm | Zero2 | لا | نعم | 1 | 1560 | 1 | 36 جم |
| chaglm | Zero2 | لا | لا | 1 | 1560 | 1 | 38g |
| chaglm | Zero2 | لا | نعم | 1 | 1560 | 4 | 24g |
| chaglm | Zero2 | لا | لا | 1 | 1560 | 4 | 29 جم |
| chaglm2 | Zero2 | لا | نعم | 1 | 1560 | 1 | 35 جم |
| chaglm2 | Zero2 | لا | لا | 1 | 1560 | 1 | 36 جم |
| chaglm2 | Zero2 | لا | نعم | 1 | 1560 | 4 | 22g |
| chaglm2 | Zero2 | لا | لا | 1 | 1560 | 4 | 27 جم |
تشير طريقة PT ، وهي طريقة الضبط P ، إلى الكود الرسمي لـ ChatGlm ، وهي طريقة ناعمة للنماذج الكبيرة.
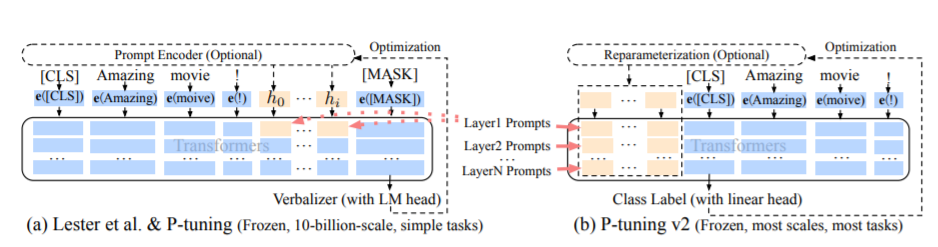
للاطلاع على رمز الضبط ، انظر Train.py ، الجزء الأساسي هو كما يلي:
config = MODE [ args . mode ][ "config" ]. from_pretrained ( args . model_name_or_path )
config . pre_seq_len = args . pre_seq_len
config . prefix_projection = args . prefix_projection
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path , config = config )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in [ "prefix_encoder" ]):
param . requires_grad = Falseعندما تكون prepix_projection صحيحة ، تتم إضافة معلمات جديدة إلى التضمين وكل طبقة من النموذج الكبير ؛ عندما تكون خاطئة ، تتم إضافة معلمات جديدة إلى تضمين النموذج الكبير فقط.
يتم تدريب رموز التدريب باستخدام السرعة العميقة. يمكن تعيين المعلمات بما في ذلك Train_Path ، model_name_or_path ، mode ، train_type ، pre_seq_len ، prefix_projection ، ds_file ، num_train_epochs ، per_device_train_batch_size ، gradient_ascumulation_steps ، output_dir ، إلخ.
ChatGlm تدريب بطاقة واحدة
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 768
--max_src_len 512
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
تدريب ChatGlm من أربع بطاقة ، CUDA_VISIBLE_DEVICES عناصر التحكم التي يتم تدريب البطاقات. إذا لم تتم إضافة هذه المعلمة ، فهذا يعني أن جميع البطاقات الموجودة على جهاز الجري يتم تدريبها.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
ChatGlm2 تدريب بطاقة واحدة
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
تدريب chatglm2 من أربع بطاقة ، والتحكم الذي يتم تدريب البطاقات من خلال cuda_visible_devices. إذا لم تتم إضافة هذه المعلمة ، فهذا يعني أن جميع البطاقات الموجودة على جهاز الجري يتم تدريبها.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
ChatGlm3 تدريب بطاقة واحدة
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
ChatGlm3 التدريب الأربع بطاقات ، والتحكم الذي يتم تدريب البطاقات من خلال CUDA_VISIBLE_DEVICES. إذا لم تتم إضافة هذه المعلمة ، فهذا يعني أن جميع البطاقات الموجودة على جهاز الجري يتم تدريبها.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
ملاحظة: إن ذاكرة الفيديو المستخدمة في صقل ChatGLM هي أكثر من تلك الخاصة بـ ChatGLM2 ، وحسابات ذاكرة الفيديو التفصيلية لما يلي:
| نموذج | مرحلة السرعة العميقة | تفريغ | التدرج checkpointing | حجم الدُفعة | الحد الأقصى طول | رقم GPU-A40 | ذاكرة الفيديو المستهلكة |
|---|---|---|---|---|---|---|---|
| chaglm | Zero2 | لا | نعم | 1 | 768 | 1 | 43 جم |
| chaglm | Zero2 | لا | لا | 1 | 300 | 1 | 44 جم |
| chaglm | Zero2 | لا | نعم | 1 | 1560 | 4 | 37 جم |
| chaglm | Zero2 | لا | لا | 1 | 1360 | 4 | 44 جم |
| chaglm2 | Zero2 | لا | نعم | 1 | 1560 | 1 | 20g |
| chaglm2 | Zero2 | لا | لا | 1 | 1560 | 1 | 40 جم |
| chaglm2 | Zero2 | لا | نعم | 1 | 1560 | 4 | 19G |
| chaglm2 | Zero2 | لا | لا | 1 | 1560 | 4 | 39 جم |
طريقة LORA ، أي إضافة مصفوفة منخفضة الرتبة إلى المعلمات المحددة (مصفوفة الوزن) بالتوازي مع نماذج اللغة الكبيرة ، وخلال التدريب النموذجي ، يتم تدريب فقط المعلمات الإضافية لمصفوفة منخفضة الرتبة المتوازية. عندما تكون "قيمة الرتبة" أصغر بكثير من البعد الأصلي للمعلمة ، فإن عدد معلمات المصفوفة المنخفضة المضافة حديثًا هو صغير جدًا أيضًا. عند ضبط مهام المصب ، يجب تدريب المعلمات الصغيرة فقط ، ولكن يمكن الحصول على نتائج أداء جيدة.
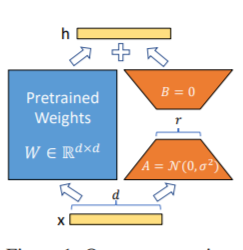
للاطلاع على رمز الضبط ، انظر Train.py ، الجزء الأساسي هو كما يلي:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )
lora_module_name = args . lora_module_name . split ( "," )
config = LoraConfig ( r = args . lora_dim ,
lora_alpha = args . lora_alpha ,
target_modules = lora_module_name ,
lora_dropout = args . lora_dropout ,
bias = "none" ,
task_type = "CAUSAL_LM" ,
inference_mode = False ,
)
model = get_peft_model ( model , config )
model . config . torch_dtype = torch . float32ملاحظة: بعد تدريب لورا ، يرجى دمج المعلمات أولاً وجعل تنبؤات النموذج.
يتم تدريب رموز التدريب باستخدام السرعة العميقة. يمكن تعيين المعلمات بما في ذلك train_path ، model_name_or_path ، mode ، train_type ، lora_dim ، lora_alpha ، lora_dropout ، lora_module_name ، ds_file ، num_train_epochs ، per_device_tain_batch_siz مهامك الخاصة.
ChatGlm تدريب بطاقة واحدة
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
تدريب ChatGlm من أربع بطاقة ، CUDA_VISIBLE_DEVICES عناصر التحكم التي يتم تدريب البطاقات. إذا لم تتم إضافة هذه المعلمة ، فهذا يعني أن جميع البطاقات الموجودة على جهاز الجري يتم تدريبها.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGlm2 تدريب بطاقة واحدة
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
تدريب chatglm2 من أربع بطاقة ، والتحكم الذي يتم تدريب البطاقات من خلال cuda_visible_devices. إذا لم تتم إضافة هذه المعلمة ، فهذا يعني أن جميع البطاقات الموجودة على جهاز الجري يتم تدريبها.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGlm3 تدريب بطاقة واحدة
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
ChatGlm3 التدريب الأربع بطاقات ، والتحكم الذي يتم تدريب البطاقات من خلال CUDA_VISIBLE_DEVICES. إذا لم تتم إضافة هذه المعلمة ، فهذا يعني أن جميع البطاقات الموجودة على جهاز الجري يتم تدريبها.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
ملاحظة: إن ذاكرة الفيديو المستخدمة في صقل ChatGLM هي أكثر من تلك الخاصة بـ ChatGLM2 ، وحسابات ذاكرة الفيديو التفصيلية لما يلي:
| نموذج | مرحلة السرعة العميقة | تفريغ | التدرج checkpointing | حجم الدُفعة | الحد الأقصى طول | رقم GPU-A40 | ذاكرة الفيديو المستهلكة |
|---|---|---|---|---|---|---|---|
| chaglm | Zero2 | لا | نعم | 1 | 1560 | 1 | 20g |
| chaglm | Zero2 | لا | لا | 1 | 1560 | 1 | 45 جم |
| chaglm | Zero2 | لا | نعم | 1 | 1560 | 4 | 20g |
| chaglm | Zero2 | لا | لا | 1 | 1560 | 4 | 45 جم |
| chaglm2 | Zero2 | لا | نعم | 1 | 1560 | 1 | 20g |
| chaglm2 | Zero2 | لا | لا | 1 | 1560 | 1 | 43 جم |
| chaglm2 | Zero2 | لا | نعم | 1 | 1560 | 4 | 19G |
| chaglm2 | Zero2 | لا | لا | 1 | 1560 | 4 | 42 جم |
ملاحظة: تقوم طريقة LORA فقط بحفظ معلمات تدريب LORA عند حفظ النموذج ، لذلك يجب دمج معلمات النموذج عند التنبؤ بالنموذج. للحصول على التفاصيل ، يرجى الرجوع إلى merge_lora.py.
يتم استخدام طريقة المعلمة الكاملة لتدريب النموذج الكبير في المعلمات الكاملة. يستخدم بشكل أساسي طريقة DeepEd-Zero3 لتقسيم معلمات النموذج إلى بطاقات متعددة ، ويستخدم طريقة الإزالة لتفريغ معلمات المُحسّنة إلى وحدة المعالجة المركزية لحل مشكلة بطاقات الرسومات غير الكافية.
للاطلاع على رمز الضبط ، انظر Train.py ، الجزء الأساسي هو كما يلي:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )يتم تدريب رموز التدريب باستخدام السرعة العميقة. يمكن تعيين المعلمات بما في ذلك Train_Path ، model_name_or_path ، mode ، train_type ، ds_file ، num_train_epochs ، per_device_train_batch_size ، gradient_accumulation_steps ، output_dir ، وما إلى ذلك ، والتي يمكن تكوينها وفقًا لمادةك الخاصة.
تدريب ChatGlm من أربع بطاقة ، CUDA_VISIBLE_DEVICES عناصر التحكم التي يتم تدريب البطاقات. إذا لم تتم إضافة هذه المعلمة ، فهذا يعني أن جميع البطاقات الموجودة على جهاز الجري يتم تدريبها.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type all
--seed 1234
--ds_file ds_zero3_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
تدريب chatglm2 من أربع بطاقة ، والتحكم الذي يتم تدريب البطاقات من خلال cuda_visible_devices. إذا لم تتم إضافة هذه المعلمة ، فهذا يعني أن جميع البطاقات الموجودة على جهاز الجري يتم تدريبها.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGlm3 التدريب الأربع بطاقات ، والتحكم الذي يتم تدريب البطاقات من خلال CUDA_VISIBLE_DEVICES. إذا لم تتم إضافة هذه المعلمة ، فهذا يعني أن جميع البطاقات الموجودة على جهاز الجري يتم تدريبها.
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
ملاحظة: إن ذاكرة الفيديو المستخدمة في صقل ChatGLM هي أكثر من تلك الخاصة بـ ChatGLM2 ، وحسابات ذاكرة الفيديو التفصيلية لما يلي:
| نموذج | مرحلة السرعة العميقة | تفريغ | التدرج checkpointing | حجم الدُفعة | الحد الأقصى طول | رقم GPU-A40 | ذاكرة الفيديو المستهلكة |
|---|---|---|---|---|---|---|---|
| chaglm | Zero3 | نعم | نعم | 1 | 1560 | 4 | 33 جم |
| chaglm2 | Zero3 | لا | نعم | 1 | 1560 | 4 | 44 جم |
| chaglm2 | Zero3 | نعم | نعم | 1 | 1560 | 4 | 26 جم |
فيما يلي وصفًا للمحتوى ذي الصلة ذات المرحلة الصفر في DeepSpeed.
عرض الملف
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为"性能故障", "部件故障", "组成"和 "检测工具"的相关三元组,三元组内部用"_"连接,三元组之间用\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高n风扇_部件故障_低速转动"
}
| طريقة الضبط | PT-only-embedding | حزب العمال | تجميد | لورا |
|---|---|---|---|---|
| نتائج الاختبار F1 | 0.0 | 0.6283 | 0.5675 | 0.5359 |
التحليل الهيكلي:
عانى العديد من الطلاب من نسيان الكارثي بعد الضبط ، لكن رمز التدريب لهذا المشروع لم يظهر. لقد اختبروا "مهمة الترجمة" و "مهمة الكود" و "مهمة السؤال والجيب". نتائج الاختبار المحددة هي كما يلي:


{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
نظرًا لأنه لا يمكن تقييم محتوى النموذج التوليدي مثل مهمة استخراج المعلومات ، فليس من المناسب استخدام الأزرق أو Rouge الحالي للتقييم ، لذلك تمت صياغة قاعدة تسجيل. يتم الحكم على نموذج D2Q من خلال وجهات نظر التنوع والدقة. كل عينة لديها ما مجموعه 5 نقاط ، مع ما مجموعه 20 عينة.
| طريقة الضبط | النموذج الأصلي | PT-only-embedding | حزب العمال | تجميد | لورا |
|---|---|---|---|---|---|
| جزء | 51.75 | 73.75 | 87.75 | 79.25 | 86.75 |
انظر وصف الكود: ممارسة خط الأنابيب (خط الأنابيب)
يرجى الاطلاع على علامة v0.1


