ChatGLM Finetuning
v0.1
Ce projet effectue principalement du réglage fin de différentes manières (méthode de gel, méthode LORA, méthode de réglage P, paramètres complets, etc.) pour les modèles ChatGLM, chatGLM2 et chatGLM3, et compare les effets du grand modèle sur différentes méthodes de réglage fin, principalement des tâches d'extraction d'informations, des tasks de production, des tâches de classification, etc.
Ce projet soutient la formation à cartes à carte et la formation à plusieurs cartes. En raison de l'ensemble d'instructions unique, il n'y a pas de sérieux oublier catastrophique après le réglage fin du modèle.
Étant donné que le code et le modèle officiel ont été mis à jour, le code et le modèle actuels de chatGLM1 et 2 sont la version 20230806 (notez que si le code s'exécute incorrectement, vous pouvez remplacer le fichier PY dans le fichier par le code source lié à ChatGLM, car la version du modèle dans laquelle vous vous trouvez peut être incohérente par la version du code de ce projet). ChatGlm3 est la version 20231212.
PS: Il n'y a aucune utilisation de l'entraîneur (bien que le code du formateur soit simple, il n'est pas facile de modifier. À l'ère des grands modèles, les ingénieurs d'algorithme sont devenus des ingénieurs de données, ils doivent donc comprendre davantage le processus de formation)
Lorsque vous affinez le modèle, en cas de mémoire vidéo insuffisante, vous pouvez activer des paramètres tels que gradient_checkpointing, zéro3 et décharger pour enregistrer la mémoire vidéo.
Le paramètre Model_Name_OR_PATH suivant est le chemin du modèle. Veuillez le modifier en fonction de l'adresse que vous pouvez enregistrer en fonction de votre modèle réel.
La méthode de congélation, c'est-à-dire les congélations de paramètres, et certains paramètres sont gelés pour le modèle d'origine, et seuls certains paramètres sont formés pour obtenir des cartes uniques ou multiples. Si l'opération TP ou PP n'est pas effectuée, le grand modèle peut être formé.
Pour un code de réglage fin, voir Train.py, la partie principale est la suivante:
freeze_module_name = args . freeze_module_name . split ( "," )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in freeze_module_name ):
param . requires_grad = FalsePour les modifications de différentes couches du modèle, vous pouvez modifier vous-même la configuration du paramètre Freeze_Module_Name, telles que "couches.27., Couches.26., Couches.25., Couches.24." Les codes de formation sont tous formés en utilisant Deeppeed. Les paramètres peuvent être définis, notamment Train_Path, Model_Name_Or_Path, Mode, Train_Type, Freeze_Module_Name, DS_File, NUM_TRAIN_EPOCHS, PER_DEVICE_TRAIN_BATCH_SIZE, Gradient_Accumulation_steps, output_dir, etc., et peuvent être configurés selon vos propres tasks.
Formation de carte simple chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Formation de quatre cartes chatglm, CUDA_VISIBLE_DEVICES CONTRÔLE Quelles cartes sont formées. Si ce paramètre n'est pas ajouté, cela signifie que toutes les cartes de la machine en cours d'exécution sont formées.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Formation par carte simple chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Formation à quatre cartes chatglm2, contrôlez les cartes formées via CUDA_VISIBLE_DEVICES. Si ce paramètre n'est pas ajouté, cela signifie que toutes les cartes de la machine en cours d'exécution sont formées.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Formation à carte simple chatglm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
Formation à quatre cartes chatGLM3, contrôlez les cartes formées via CUDA_VISIBLE_DEVICES. Si ce paramètre n'est pas ajouté, cela signifie que toutes les cartes de la machine en cours d'exécution sont formées.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: La mémoire vidéo utilisée pour le réglage fin de chatGLM est supérieure à celle de ChatGlm2, et la mémoire vidéo détaillée explique ce qui suit:
| Modèle | Étage à vitesse profonde | Décharger | Poignage de contrôle du gradient | Taille de lot | Longueur maximale | Numéro GPU-A40 | Mémoire vidéo consommée |
|---|---|---|---|---|---|---|---|
| Chaglm | zéro2 | Non | Oui | 1 | 1560 | 1 | 36g |
| Chaglm | zéro2 | Non | Non | 1 | 1560 | 1 | 38g |
| Chaglm | zéro2 | Non | Oui | 1 | 1560 | 4 | 24g |
| Chaglm | zéro2 | Non | Non | 1 | 1560 | 4 | 29 g |
| Chaglm2 | zéro2 | Non | Oui | 1 | 1560 | 1 | 35g |
| Chaglm2 | zéro2 | Non | Non | 1 | 1560 | 1 | 36g |
| Chaglm2 | zéro2 | Non | Oui | 1 | 1560 | 4 | 22g |
| Chaglm2 | zéro2 | Non | Non | 1 | 1560 | 4 | 27G |
La méthode PT, à savoir la méthode de réglage P, fait référence au code officiel de chatGLM, est une méthode de soft pour les grands modèles.
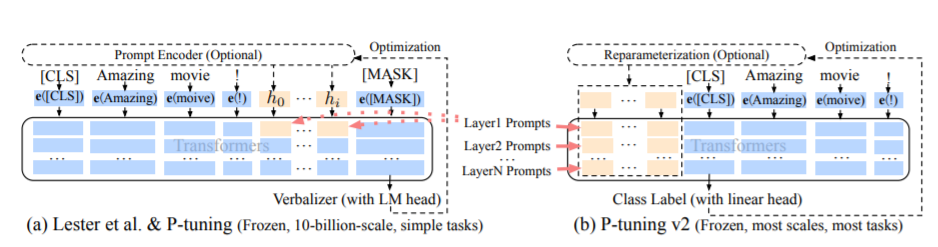
Pour un code de réglage fin, voir Train.py, la partie principale est la suivante:
config = MODE [ args . mode ][ "config" ]. from_pretrained ( args . model_name_or_path )
config . pre_seq_len = args . pre_seq_len
config . prefix_projection = args . prefix_projection
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path , config = config )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in [ "prefix_encoder" ]):
param . requires_grad = FalseLorsque prefix_projection est vrai, de nouveaux paramètres sont ajoutés à l'intégration et à chaque couche du grand modèle; Lorsqu'ils sont faux, de nouveaux paramètres sont ajoutés à l'incorporation du grand modèle uniquement.
Les codes de formation sont formés en utilisant Deeppeed. Les paramètres peuvent être définis, notamment Train_Path, Model_Name_or_Path, Mode, Train_Type, Pre_Seq_Len, Prefix_Projection, DS_File, NUM_TRAIN_EPOCHS, PER_DEVICE_TRAIN_BATCH_SIZE, GRADIENT_ACCUMULATION_STEPS, OUTPUT_DIR, etc., et peuvent être configurés selon To Your Tasks.
Formation de carte simple chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 768
--max_src_len 512
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Formation de quatre cartes chatglm, CUDA_VISIBLE_DEVICES CONTRÔLE Quelles cartes sont formées. Si ce paramètre n'est pas ajouté, cela signifie que toutes les cartes de la machine en cours d'exécution sont formées.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Formation par carte simple chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Formation à quatre cartes chatglm2, contrôlez les cartes formées via CUDA_VISIBLE_DEVICES. Si ce paramètre n'est pas ajouté, cela signifie que toutes les cartes de la machine en cours d'exécution sont formées.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Formation à carte simple chatglm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
Formation à quatre cartes chatGLM3, contrôlez les cartes formées via CUDA_VISIBLE_DEVICES. Si ce paramètre n'est pas ajouté, cela signifie que toutes les cartes de la machine en cours d'exécution sont formées.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
PS: La mémoire vidéo utilisée pour le réglage fin de chatGLM est supérieure à celle de ChatGlm2, et la mémoire vidéo détaillée explique ce qui suit:
| Modèle | Étage à vitesse profonde | Décharger | Poignage de contrôle du gradient | Taille de lot | Longueur maximale | Numéro GPU-A40 | Mémoire vidéo consommée |
|---|---|---|---|---|---|---|---|
| Chaglm | zéro2 | Non | Oui | 1 | 768 | 1 | 43g |
| Chaglm | zéro2 | Non | Non | 1 | 300 | 1 | 44g |
| Chaglm | zéro2 | Non | Oui | 1 | 1560 | 4 | 37g |
| Chaglm | zéro2 | Non | Non | 1 | 1360 | 4 | 44g |
| Chaglm2 | zéro2 | Non | Oui | 1 | 1560 | 1 | 20g |
| Chaglm2 | zéro2 | Non | Non | 1 | 1560 | 1 | 40g |
| Chaglm2 | zéro2 | Non | Oui | 1 | 1560 | 4 | 19 g |
| Chaglm2 | zéro2 | Non | Non | 1 | 1560 | 4 | 39g |
La méthode LORA, c'est-à-dire pour ajouter une matrice de bas rang supplémentaire, aux paramètres spécifiés (matrice de poids) en parallèle sur des modèles de langues importants, et lors de l'entraînement du modèle, seuls les paramètres supplémentaires de la matrice de faible rang parallèle sont entraînés. Lorsque la "valeur de rang" est beaucoup plus petite que la dimension du paramètre d'origine, le nombre de paramètres de matrice de bas rang nouvellement ajoutés est également très faible. Lors du réglage des tâches en aval, seuls les petits paramètres doivent être formés, mais de bons résultats de performances peuvent être obtenus.
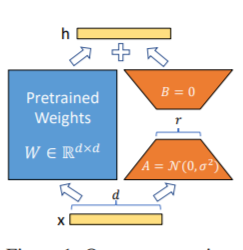
Pour un code de réglage fin, voir Train.py, la partie principale est la suivante:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )
lora_module_name = args . lora_module_name . split ( "," )
config = LoraConfig ( r = args . lora_dim ,
lora_alpha = args . lora_alpha ,
target_modules = lora_module_name ,
lora_dropout = args . lora_dropout ,
bias = "none" ,
task_type = "CAUSAL_LM" ,
inference_mode = False ,
)
model = get_peft_model ( model , config )
model . config . torch_dtype = torch . float32PS: Après la formation LORA, veuillez d'abord fusionner les paramètres et faire des prédictions de modèle.
Les codes de formation sont formés en utilisant Deeppeed. Les paramètres peuvent être définis, notamment Train_Path, Model_Name_Or_Path, Mode, Train_Type, Lora_Dim, Lora_alpha, Lora_dropout, Lora_Module_Name, DS_FILE, NUM_TRAIN_EPOCHS, PER_DEVIC configuré en fonction de vos propres tâches.
Formation de carte simple chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Formation de quatre cartes chatglm, CUDA_VISIBLE_DEVICES CONTRÔLE Quelles cartes sont formées. Si ce paramètre n'est pas ajouté, cela signifie que toutes les cartes de la machine en cours d'exécution sont formées.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Formation par carte simple chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Formation à quatre cartes chatglm2, contrôlez les cartes formées via CUDA_VISIBLE_DEVICES. Si ce paramètre n'est pas ajouté, cela signifie que toutes les cartes de la machine en cours d'exécution sont formées.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Formation à carte simple chatglm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
Formation à quatre cartes chatGLM3, contrôlez les cartes formées via CUDA_VISIBLE_DEVICES. Si ce paramètre n'est pas ajouté, cela signifie que toutes les cartes de la machine en cours d'exécution sont formées.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: La mémoire vidéo utilisée pour le réglage fin de chatGLM est supérieure à celle de ChatGlm2, et la mémoire vidéo détaillée explique ce qui suit:
| Modèle | Étage à vitesse profonde | Décharger | Poignage de contrôle du gradient | Taille de lot | Longueur maximale | Numéro GPU-A40 | Mémoire vidéo consommée |
|---|---|---|---|---|---|---|---|
| Chaglm | zéro2 | Non | Oui | 1 | 1560 | 1 | 20g |
| Chaglm | zéro2 | Non | Non | 1 | 1560 | 1 | 45g |
| Chaglm | zéro2 | Non | Oui | 1 | 1560 | 4 | 20g |
| Chaglm | zéro2 | Non | Non | 1 | 1560 | 4 | 45g |
| Chaglm2 | zéro2 | Non | Oui | 1 | 1560 | 1 | 20g |
| Chaglm2 | zéro2 | Non | Non | 1 | 1560 | 1 | 43g |
| Chaglm2 | zéro2 | Non | Oui | 1 | 1560 | 4 | 19 g |
| Chaglm2 | zéro2 | Non | Non | 1 | 1560 | 4 | 42g |
Remarque: La méthode LORA enregistre uniquement les paramètres de formation LORA lors de la sauvegarde du modèle, les paramètres du modèle doivent donc être fusionnés lors de la prévision du modèle. Pour plus de détails, veuillez consulter Merge_lora.py.
La méthode des paramètres complète est utilisée pour former le grand modèle en paramètres complets. Il utilise principalement la méthode Deeppeed-Zero3 pour diviser les paramètres du modèle en plusieurs cartes, et utilise la méthode de déchargement pour décharger les paramètres d'optimiseur au CPU pour résoudre le problème des cartes graphiques insuffisantes.
Pour un code de réglage fin, voir Train.py, la partie principale est la suivante:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )Les codes de formation sont formés en utilisant Deeppeed. Les paramètres peuvent être définis, notamment Train_Path, Model_Name_Or_Path, Mode, Train_Type, DS_File, NUM_TRAIN_EPOCHS, PER_DEVICE_TRAIN_BATCH_SIZE, Gradient_Accumulation_steps, output_dir, etc., qui peut être configuré selon vos propres tâches.
Formation de quatre cartes chatglm, CUDA_VISIBLE_DEVICES CONTRÔLE Quelles cartes sont formées. Si ce paramètre n'est pas ajouté, cela signifie que toutes les cartes de la machine en cours d'exécution sont formées.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type all
--seed 1234
--ds_file ds_zero3_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Formation à quatre cartes chatglm2, contrôlez les cartes formées via CUDA_VISIBLE_DEVICES. Si ce paramètre n'est pas ajouté, cela signifie que toutes les cartes de la machine en cours d'exécution sont formées.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Formation à quatre cartes chatGLM3, contrôlez les cartes formées via CUDA_VISIBLE_DEVICES. Si ce paramètre n'est pas ajouté, cela signifie que toutes les cartes de la machine en cours d'exécution sont formées.
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: La mémoire vidéo utilisée pour le réglage fin de chatGLM est supérieure à celle de ChatGlm2, et la mémoire vidéo détaillée explique ce qui suit:
| Modèle | Étage à vitesse profonde | Décharger | Poignage de contrôle du gradient | Taille de lot | Longueur maximale | Numéro GPU-A40 | Mémoire vidéo consommée |
|---|---|---|---|---|---|---|---|
| Chaglm | zéro3 | Oui | Oui | 1 | 1560 | 4 | 33g |
| Chaglm2 | zéro3 | Non | Oui | 1 | 1560 | 4 | 44g |
| Chaglm2 | zéro3 | Oui | Oui | 1 | 1560 | 4 | 26g |
Ce qui suit est une description du contenu pertinent du stade zéro de Deeppeed.
Afficher le fichier exigences.txt
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为"性能故障", "部件故障", "组成"和 "检测工具"的相关三元组,三元组内部用"_"连接,三元组之间用\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高n风扇_部件故障_低速转动"
}
| Méthode de réglage fin | Pt uniquement | Pt | Geler | Lora |
|---|---|---|---|---|
| Résultats des tests F1 | 0.0 | 0,6283 | 0,5675 | 0,5359 |
Analyse structurelle:
De nombreux étudiants ont connu l'oubli catastrophique après un réglage fin, mais le code de formation de ce projet n'est pas apparu. Ils ont testé la "tâche de traduction", la "tâche de code" et la "tâche de question et de réponse". Les résultats des tests spécifiques sont les suivants:


{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
Étant donné que le contenu du modèle génératif ne peut pas être évalué comme la tâche d'extraction des informations, il n'est pas approprié d'utiliser le bleu ou le rouge existant pour évaluer, de sorte qu'une règle de score a été formulée. Le modèle D2Q est jugé à travers les deux perspectives de diversité et de précision. Chaque échantillon a un total de 5 points, avec un total de 20 échantillons.
| Méthode de réglage fin | Modèle d'origine | Pt uniquement | Pt | Geler | Lora |
|---|---|---|---|---|---|
| Fraction | 51,75 | 73,75 | 87.75 | 79.25 | 86.75 |
Voir la description du code: Parallélisme du pipeline (Pipeline) Pratique
Veuillez voir la balise V0.1


