ChatGLM Finetuning
v0.1
โครงการนี้ส่วนใหญ่ดำเนินการปรับแต่งในรูปแบบที่แตกต่างกัน (วิธีการแช่แข็ง, วิธี LORA, วิธีการปรับแต่ง, พารามิเตอร์เต็ม ฯลฯ ) สำหรับ chatglm, chatglm2 และโมเดล chatglm3 และเปรียบเทียบผลกระทบของโมเดลขนาดใหญ่บนวิธีการปรับแต่งที่แตกต่างกัน
โครงการนี้สนับสนุนการฝึกอบรมบัตรเดี่ยวและการฝึกอบรมหลายบัตร เนื่องจากชุดคำสั่งเดียวที่ปรับแต่งการปรับแต่ง จึงไม่มีหายนะร้ายแรงที่ลืม หลังจากการปรับแต่งแบบจำลองอย่างละเอียด
เนื่องจากรหัสและรุ่นอย่างเป็นทางการได้รับการอัปเดตรหัสปัจจุบันและรุ่นของ ChatGLM1 และ 2 เป็นเวอร์ชัน 20230806 (โปรดทราบว่าหากรหัสทำงานไม่ถูกต้องคุณสามารถแทนที่ไฟล์ PY ในไฟล์ด้วยซอร์สโค้ดที่เกี่ยวข้องกับ ChatGLM chatglm3 เป็นเวอร์ชัน 20231212
PS: ไม่มีการใช้งานเทรนเนอร์ (แม้ว่ารหัสเทรนเนอร์นั้นง่าย แต่ก็ไม่ง่ายที่จะปรับเปลี่ยนในยุคของรุ่นใหญ่วิศวกรอัลกอริทึมได้กลายเป็นวิศวกรข้อมูลดังนั้นพวกเขาจึงต้องเข้าใจกระบวนการฝึกอบรมมากขึ้น)
เมื่อปรับแต่งโมเดลหากมีหน่วยความจำวิดีโอไม่เพียงพอคุณสามารถเปิดพารามิเตอร์เช่นการไล่ระดับสี _CheckPointing, ZERO3 และ Offload เพื่อบันทึกหน่วยความจำวิดีโอ
พารามิเตอร์ model_name_or_path ต่อไปนี้เป็นพา ธ รุ่น โปรดแก้ไขตามที่อยู่ที่คุณสามารถบันทึกได้ตามโมเดลจริงของคุณ
วิธีการแช่แข็งนั่นคือพารามิเตอร์ค้างและพารามิเตอร์บางอย่างจะถูกแช่แข็งสำหรับโมเดลดั้งเดิมและมีเพียงพารามิเตอร์บางตัวเท่านั้นที่ได้รับการฝึกฝนเพื่อให้ได้การ์ดเดี่ยวหรือหลายใบ หากการดำเนินการ TP หรือ PP ไม่ได้ดำเนินการโมเดลขนาดใหญ่สามารถได้รับการฝึกฝน
สำหรับรหัสการปรับแต่งให้ดูที่ Train.py ส่วนหลักมีดังนี้:
freeze_module_name = args . freeze_module_name . split ( "," )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in freeze_module_name ):
param . requires_grad = Falseสำหรับการปรับเปลี่ยนเลเยอร์ที่แตกต่างกันของโมเดลคุณสามารถแก้ไขการกำหนดค่าพารามิเตอร์ freeze_module_name ด้วยตัวคุณเองเช่น "เลเยอร์. 27., layers.26., layers.25., layers.24" รหัสการฝึกอบรมทั้งหมดได้รับการฝึกฝนโดยใช้ DeepSpeed พารามิเตอร์สามารถตั้งค่าได้รวมถึง train_path, model_name_or_path, โหมด, train_type, freeze_module_name, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir ฯลฯ
การฝึกการ์ดใบเดียว chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
การฝึกอบรมสี่การ์ด Chatglm, การควบคุม CUDA_VISIBLE_DEVICES ควบคุมการ์ดที่ได้รับการฝึกฝน หากไม่มีการเพิ่มพารามิเตอร์นี้หมายความว่าการ์ดทั้งหมดในเครื่องที่ผ่านการฝึกอบรม
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
การฝึกอบรมการ์ดใบเดียว chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
การฝึกอบรมสี่ใบ Chatglm2 การควบคุมการ์ดที่ได้รับการฝึกฝนผ่าน cuda_visible_devices หากไม่มีการเพิ่มพารามิเตอร์นี้หมายความว่าการ์ดทั้งหมดในเครื่องที่ผ่านการฝึกอบรม
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
การฝึกการ์ดใบเดียว chatglm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
การฝึกอบรมสี่การ์ด ChatglM3 การควบคุมใดที่ได้รับการฝึกฝนผ่าน CUDA_VISIBLE_DEVICES หากไม่มีการเพิ่มพารามิเตอร์นี้หมายความว่าการ์ดทั้งหมดในเครื่องที่ผ่านการฝึกอบรม
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: หน่วยความจำวิดีโอที่ใช้สำหรับการปรับแต่ง Chatglm เป็นมากกว่าของ ChatglM2 และบัญชีหน่วยความจำวิดีโอโดยละเอียดสำหรับสิ่งต่อไปนี้:
| แบบอย่าง | เวที DeepSpeed | ขนถ่าย | จุดตรวจการไล่ระดับสี | ขนาดแบทช์ | ความยาวสูงสุด | หมายเลข GPU-A40 | ใช้หน่วยความจำวิดีโอ |
|---|---|---|---|---|---|---|---|
| ความรู้ | Zero2 | เลขที่ | ใช่ | 1 | ค.ศ. 1560 | 1 | 36G |
| ความรู้ | Zero2 | เลขที่ | เลขที่ | 1 | ค.ศ. 1560 | 1 | 38 กรัม |
| ความรู้ | Zero2 | เลขที่ | ใช่ | 1 | ค.ศ. 1560 | 4 | 24G |
| ความรู้ | Zero2 | เลขที่ | เลขที่ | 1 | ค.ศ. 1560 | 4 | 29G |
| chaglm2 | Zero2 | เลขที่ | ใช่ | 1 | ค.ศ. 1560 | 1 | 35 กรัม |
| chaglm2 | Zero2 | เลขที่ | เลขที่ | 1 | ค.ศ. 1560 | 1 | 36G |
| chaglm2 | Zero2 | เลขที่ | ใช่ | 1 | ค.ศ. 1560 | 4 | 22 กรัม |
| chaglm2 | Zero2 | เลขที่ | เลขที่ | 1 | ค.ศ. 1560 | 4 | 27G |
วิธีการ PT คือวิธีการปรับแต่งหมายถึงรหัสอย่างเป็นทางการของ Chatglm เป็นวิธีการเสนอขายแบบนุ่มสำหรับรุ่นขนาดใหญ่
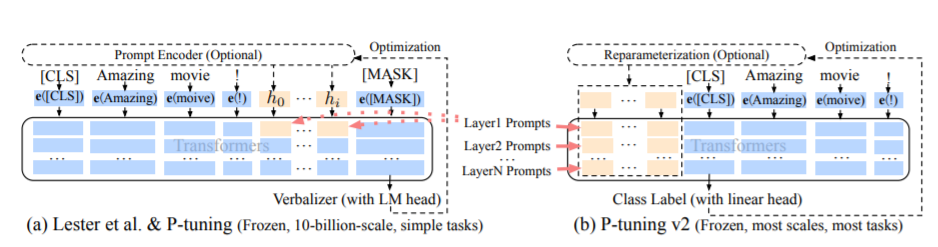
สำหรับรหัสการปรับแต่งให้ดูที่ Train.py ส่วนหลักมีดังนี้:
config = MODE [ args . mode ][ "config" ]. from_pretrained ( args . model_name_or_path )
config . pre_seq_len = args . pre_seq_len
config . prefix_projection = args . prefix_projection
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path , config = config )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in [ "prefix_encoder" ]):
param . requires_grad = Falseเมื่อ Prefix_project เป็นจริงพารามิเตอร์ใหม่จะถูกเพิ่มเข้าไปในการฝังและแต่ละชั้นของโมเดลขนาดใหญ่ เมื่อเท็จพารามิเตอร์ใหม่จะถูกเพิ่มเข้าไปในการฝังรุ่นใหญ่เท่านั้น
รหัสการฝึกอบรมได้รับการฝึกฝนโดยใช้ DeepSpeed พารามิเตอร์สามารถตั้งค่าได้รวมถึง train_path, model_name_or_path, โหมด, train_type, pre_seq_len, prefix_project, ds_file, num_train_epochs, per_device_train_batch_size
การฝึกการ์ดใบเดียว chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 768
--max_src_len 512
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
การฝึกอบรมสี่การ์ด Chatglm, การควบคุม CUDA_VISIBLE_DEVICES ควบคุมการ์ดที่ได้รับการฝึกฝน หากไม่มีการเพิ่มพารามิเตอร์นี้หมายความว่าการ์ดทั้งหมดในเครื่องที่ผ่านการฝึกอบรม
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
การฝึกอบรมการ์ดใบเดียว chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
การฝึกอบรมสี่ใบ Chatglm2 การควบคุมการ์ดที่ได้รับการฝึกฝนผ่าน cuda_visible_devices หากไม่มีการเพิ่มพารามิเตอร์นี้หมายความว่าการ์ดทั้งหมดในเครื่องที่ผ่านการฝึกอบรม
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
การฝึกการ์ดใบเดียว chatglm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
การฝึกอบรมสี่การ์ด ChatglM3 การควบคุมใดที่ได้รับการฝึกฝนผ่าน CUDA_VISIBLE_DEVICES หากไม่มีการเพิ่มพารามิเตอร์นี้หมายความว่าการ์ดทั้งหมดในเครื่องที่ผ่านการฝึกอบรม
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
PS: หน่วยความจำวิดีโอที่ใช้สำหรับการปรับแต่ง Chatglm เป็นมากกว่าของ ChatglM2 และบัญชีหน่วยความจำวิดีโอโดยละเอียดสำหรับสิ่งต่อไปนี้:
| แบบอย่าง | เวที DeepSpeed | ขนถ่าย | จุดตรวจการไล่ระดับสี | ขนาดแบทช์ | ความยาวสูงสุด | หมายเลข GPU-A40 | ใช้หน่วยความจำวิดีโอ |
|---|---|---|---|---|---|---|---|
| ความรู้ | Zero2 | เลขที่ | ใช่ | 1 | 768 | 1 | 43G |
| ความรู้ | Zero2 | เลขที่ | เลขที่ | 1 | 300 | 1 | 44 กรัม |
| ความรู้ | Zero2 | เลขที่ | ใช่ | 1 | ค.ศ. 1560 | 4 | 37G |
| ความรู้ | Zero2 | เลขที่ | เลขที่ | 1 | 1360 | 4 | 44 กรัม |
| chaglm2 | Zero2 | เลขที่ | ใช่ | 1 | ค.ศ. 1560 | 1 | 20 กรัม |
| chaglm2 | Zero2 | เลขที่ | เลขที่ | 1 | ค.ศ. 1560 | 1 | 40 กรัม |
| chaglm2 | Zero2 | เลขที่ | ใช่ | 1 | ค.ศ. 1560 | 4 | 19G |
| chaglm2 | Zero2 | เลขที่ | เลขที่ | 1 | ค.ศ. 1560 | 4 | 39 กรัม |
วิธี LORA นั่นคือเพื่อเพิ่มเมทริกซ์ระดับต่ำเพิ่มเติมลงในพารามิเตอร์ที่ระบุ (เมทริกซ์น้ำหนัก) ในแบบขนานในแบบจำลองภาษาขนาดใหญ่และในระหว่างการฝึกอบรมแบบจำลองจะได้รับการฝึกฝนเฉพาะพารามิเตอร์เพิ่มเติมของเมทริกซ์ระดับต่ำแบบขนานเท่านั้น เมื่อ "ค่าอันดับ" มีขนาดเล็กกว่ามิติพารามิเตอร์ดั้งเดิมมากจำนวนพารามิเตอร์เมทริกซ์ต่ำที่เพิ่มขึ้นใหม่ก็มีขนาดเล็กมากเช่นกัน เมื่อปรับแต่งงานดาวน์สตรีมจะต้องได้รับการฝึกฝนเฉพาะพารามิเตอร์ขนาดเล็กเท่านั้น แต่สามารถรับผลลัพธ์ที่ดีได้
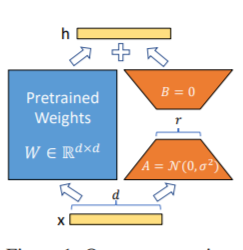
สำหรับรหัสการปรับแต่งให้ดูที่ Train.py ส่วนหลักมีดังนี้:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )
lora_module_name = args . lora_module_name . split ( "," )
config = LoraConfig ( r = args . lora_dim ,
lora_alpha = args . lora_alpha ,
target_modules = lora_module_name ,
lora_dropout = args . lora_dropout ,
bias = "none" ,
task_type = "CAUSAL_LM" ,
inference_mode = False ,
)
model = get_peft_model ( model , config )
model . config . torch_dtype = torch . float32PS: หลังจากการฝึกอบรม LORA โปรดรวมพารามิเตอร์ก่อนและทำการคาดการณ์แบบจำลอง
รหัสการฝึกอบรมได้รับการฝึกฝนโดยใช้ DeepSpeed พารามิเตอร์สามารถตั้งค่าได้รวมถึง train_path, model_name_or_path, โหมด, train_type, lora_dim, lora_alpha, lora_dropout, lora_module_name, ds_file, num_train_epochs ทำงานของคุณเอง
การฝึกการ์ดใบเดียว chatglm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
การฝึกอบรมสี่การ์ด Chatglm, การควบคุม CUDA_VISIBLE_DEVICES ควบคุมการ์ดที่ได้รับการฝึกฝน หากไม่มีการเพิ่มพารามิเตอร์นี้หมายความว่าการ์ดทั้งหมดในเครื่องที่ผ่านการฝึกอบรม
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
การฝึกอบรมการ์ดใบเดียว chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
การฝึกอบรมสี่ใบ Chatglm2 การควบคุมการ์ดที่ได้รับการฝึกฝนผ่าน cuda_visible_devices หากไม่มีการเพิ่มพารามิเตอร์นี้หมายความว่าการ์ดทั้งหมดในเครื่องที่ผ่านการฝึกอบรม
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
การฝึกการ์ดใบเดียว chatglm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
การฝึกอบรมสี่การ์ด ChatglM3 การควบคุมใดที่ได้รับการฝึกฝนผ่าน CUDA_VISIBLE_DEVICES หากไม่มีการเพิ่มพารามิเตอร์นี้หมายความว่าการ์ดทั้งหมดในเครื่องที่ผ่านการฝึกอบรม
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: หน่วยความจำวิดีโอที่ใช้สำหรับการปรับแต่ง Chatglm เป็นมากกว่าของ ChatglM2 และบัญชีหน่วยความจำวิดีโอโดยละเอียดสำหรับสิ่งต่อไปนี้:
| แบบอย่าง | เวที DeepSpeed | ขนถ่าย | จุดตรวจการไล่ระดับสี | ขนาดแบทช์ | ความยาวสูงสุด | หมายเลข GPU-A40 | ใช้หน่วยความจำวิดีโอ |
|---|---|---|---|---|---|---|---|
| ความรู้ | Zero2 | เลขที่ | ใช่ | 1 | ค.ศ. 1560 | 1 | 20 กรัม |
| ความรู้ | Zero2 | เลขที่ | เลขที่ | 1 | ค.ศ. 1560 | 1 | 45 กรัม |
| ความรู้ | Zero2 | เลขที่ | ใช่ | 1 | ค.ศ. 1560 | 4 | 20 กรัม |
| ความรู้ | Zero2 | เลขที่ | เลขที่ | 1 | ค.ศ. 1560 | 4 | 45 กรัม |
| chaglm2 | Zero2 | เลขที่ | ใช่ | 1 | ค.ศ. 1560 | 1 | 20 กรัม |
| chaglm2 | Zero2 | เลขที่ | เลขที่ | 1 | ค.ศ. 1560 | 1 | 43G |
| chaglm2 | Zero2 | เลขที่ | ใช่ | 1 | ค.ศ. 1560 | 4 | 19G |
| chaglm2 | Zero2 | เลขที่ | เลขที่ | 1 | ค.ศ. 1560 | 4 | 42 กรัม |
หมายเหตุ: วิธี LORA จะบันทึกพารามิเตอร์การฝึกอบรม LORA เท่านั้นเมื่อบันทึกแบบจำลองดังนั้นพารามิเตอร์แบบจำลองจะต้องถูกรวมเข้าด้วยกันเมื่อทำนายแบบจำลอง สำหรับรายละเอียดโปรดดูที่ merge_lora.py
วิธีการพารามิเตอร์แบบเต็มใช้ในการฝึกอบรมโมเดลขนาดใหญ่ในพารามิเตอร์เต็ม ส่วนใหญ่ใช้วิธี DeepSpeed-Zero3 เพื่อแบ่งพารามิเตอร์โมเดลเป็นการ์ดหลายใบและใช้วิธีการถ่ายโอนเพื่อยกเลิกการโหลดพารามิเตอร์ Optimizer ไปยัง CPU เพื่อแก้ปัญหาการ์ดกราฟิกที่ไม่เพียงพอ
สำหรับรหัสการปรับแต่งให้ดูที่ Train.py ส่วนหลักมีดังนี้:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )รหัสการฝึกอบรมได้รับการฝึกฝนโดยใช้ DeepSpeed พารามิเตอร์สามารถตั้งค่าได้รวมถึง train_path, model_name_or_path, โหมด, train_type, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir ฯลฯ ซึ่งสามารถกำหนดค่าตาม Tasks ของคุณเอง
การฝึกอบรมสี่การ์ด Chatglm, การควบคุม CUDA_VISIBLE_DEVICES ควบคุมการ์ดที่ได้รับการฝึกฝน หากไม่มีการเพิ่มพารามิเตอร์นี้หมายความว่าการ์ดทั้งหมดในเครื่องที่ผ่านการฝึกอบรม
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type all
--seed 1234
--ds_file ds_zero3_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
การฝึกอบรมสี่ใบ Chatglm2 การควบคุมการ์ดที่ได้รับการฝึกฝนผ่าน cuda_visible_devices หากไม่มีการเพิ่มพารามิเตอร์นี้หมายความว่าการ์ดทั้งหมดในเครื่องที่ผ่านการฝึกอบรม
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
การฝึกอบรมสี่การ์ด ChatglM3 การควบคุมใดที่ได้รับการฝึกฝนผ่าน CUDA_VISIBLE_DEVICES หากไม่มีการเพิ่มพารามิเตอร์นี้หมายความว่าการ์ดทั้งหมดในเครื่องที่ผ่านการฝึกอบรม
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: หน่วยความจำวิดีโอที่ใช้สำหรับการปรับแต่ง Chatglm เป็นมากกว่าของ ChatglM2 และบัญชีหน่วยความจำวิดีโอโดยละเอียดสำหรับสิ่งต่อไปนี้:
| แบบอย่าง | เวที DeepSpeed | ขนถ่าย | จุดตรวจการไล่ระดับสี | ขนาดแบทช์ | ความยาวสูงสุด | หมายเลข GPU-A40 | ใช้หน่วยความจำวิดีโอ |
|---|---|---|---|---|---|---|---|
| ความรู้ | Zero3 | ใช่ | ใช่ | 1 | ค.ศ. 1560 | 4 | 33G |
| chaglm2 | Zero3 | เลขที่ | ใช่ | 1 | ค.ศ. 1560 | 4 | 44 กรัม |
| chaglm2 | Zero3 | ใช่ | ใช่ | 1 | ค.ศ. 1560 | 4 | 26G |
ต่อไปนี้เป็นคำอธิบายของเนื้อหาที่เกี่ยวข้องของ Zero-Stage ของ Deepspeed
ดูข้อกำหนด. txt ไฟล์
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为"性能故障", "部件故障", "组成"和 "检测工具"的相关三元组,三元组内部用"_"连接,三元组之间用\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高n风扇_部件故障_低速转动"
}
| วิธีการปรับแต่ง | PT-only-lembedding | PT | แช่แข็ง | Lora |
|---|---|---|---|---|
| ผลการทดสอบ F1 | 0.0 | 0.6283 | 0.5675 | 0.5359 |
การวิเคราะห์โครงสร้าง:
นักเรียนหลายคนประสบกับความหายนะที่ลืมหลังจากการปรับแต่ง แต่รหัสการฝึกอบรมของโครงการนี้ไม่ปรากฏขึ้น พวกเขาทดสอบ "งานการแปล", "งานรหัส" และ "งานและตอบคำถาม" ผลการทดสอบเฉพาะมีดังนี้:


{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
เนื่องจากเนื้อหาของแบบจำลองการกำเนิดไม่สามารถประเมินได้เช่นงานสกัดข้อมูลจึงไม่เหมาะสมที่จะใช้สีน้ำเงินหรือรูจที่มีอยู่เพื่อประเมินดังนั้นจึงมีการกำหนดกฎการให้คะแนน โมเดล D2Q ถูกตัดสินผ่านมุมมองทั้งสองของความหลากหลายและความแม่นยำ แต่ละตัวอย่างมีทั้งหมด 5 คะแนนรวมทั้งหมด 20 ตัวอย่าง
| วิธีการปรับแต่ง | รุ่นดั้งเดิม | PT-only-lembedding | PT | แช่แข็ง | Lora |
|---|---|---|---|---|---|
| เศษส่วน | 51.75 | 73.75 | 87.75 | 79.25 | 86.75 |
ดูคำอธิบายรหัส: การฝึกฝน Pipeline Parallelism (Pipeline)
โปรดดู tag v0.1


