ChatGLM Finetuning
v0.1
Este projeto executa principalmente o ajuste fino de diferentes maneiras (método de congelamento, método Lora, método de ajuste P, parâmetros completos, etc.) para modelos ChatGlm, ChatGlm2 e Chatglm3 e compara os efeitos das grandes modelos em diferentes métodos de ajuste fino, principalmente direcionando as tarefas de extração de informações, tarefas de geração, tarefas de classificação, etc.
Este projeto suporta treinamento de cartão único e treinamento de vários cartão. Devido ao conjunto de instruções únicas, não há um esquecimento catastrófico sério após o ajuste fino do modelo.
Como o código e o modelo oficiais foram atualizados, o código atual e o modelo de ChatGLM1 e 2 é a versão 20230806 (observe que, se o código estiver executando incorretamente, você poderá substituir o arquivo py no arquivo pelo código-fonte relacionado ao ChatGLM, porque a versão do modelo em que você está sob a versão de código deste projeto). Chatglm3 é versão 20231212.
PS: Não há uso do treinador (embora o código do treinador seja simples, não é fácil modificar. Na era dos grandes modelos, os engenheiros de algoritmos se tornaram engenheiros de dados, portanto precisam entender mais o processo de treinamento)
Ao ajustar o modelo, se houver memória de vídeo insuficiente, você poderá ativar parâmetros como Gradient_checkPoining, zero3 e descarregar para salvar a memória de vídeo.
O seguinte parâmetro model_name_or_path é o caminho do modelo. Modifique -o de acordo com o endereço que você pode economizar de acordo com o seu modelo real.
O método de congelamento, ou seja, o congelamento dos parâmetros e alguns parâmetros são congelados para o modelo original, e apenas alguns parâmetros são treinados para obter cartões únicos ou múltiplos. Se a operação TP ou PP não for realizada, o grande modelo poderá ser treinado.
Para o código de ajuste fino, consulte Train.py, a parte principal é a seguinte:
freeze_module_name = args . freeze_module_name . split ( "," )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in freeze_module_name ):
param . requires_grad = FalsePara modificações em diferentes camadas do modelo, você pode modificar a configuração do parâmetro Freeze_module_name, como "camadas.27., Layers.26., Camadas.25., Camadas.24". Os códigos de treinamento são todos treinados usando o DeepSpeed. Os parâmetros podem ser definidos, incluindo trens_path, model_name_or_path, modo, trens_type, freeze_module_name, ds_file, num_train_epochs, per_device_train_batch_size, gradiente_acmulation_steps, output_dir, etc. e pode ser confundido de acordo com o seu.
Treinamento de cartão único ChatGlm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
O treinamento em quatro cartas do ChatGLM, CUDA_VISIBLE_DEVICES controla quais cartões são treinados. Se este parâmetro não for adicionado, significa que todos os cartões na máquina em execução serão treinados.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Treinamento de cartão único chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Treinamento de quatro cartões do ChatGlm2, Controle quais cartões são treinados através do CUDA_VISIBLE_DEVICES. Se este parâmetro não for adicionado, significa que todos os cartões na máquina em execução serão treinados.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Treinamento de cartão único ChatGlm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
Treinamento de quatro cartões do ChatGlm3, Controle quais cartões são treinados através do CUDA_VISIBLE_DEVICES. Se este parâmetro não for adicionado, significa que todos os cartões na máquina em execução serão treinados.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: A memória de vídeo usada para ajuste fino do ChatGLM é mais do que a do ChatGlm2, e o vídeo detalhado é contabilizado para o seguinte:
| Modelo | DeepSpeed-Stay | Descarregar | Ponto de verificação de gradiente | Tamanho do lote | Comprimento máximo | Número GPU-A40 | Memória de vídeo consumida |
|---|---|---|---|---|---|---|---|
| Chaglm | zero2 | Não | Sim | 1 | 1560 | 1 | 36g |
| Chaglm | zero2 | Não | Não | 1 | 1560 | 1 | 38G |
| Chaglm | zero2 | Não | Sim | 1 | 1560 | 4 | 24G |
| Chaglm | zero2 | Não | Não | 1 | 1560 | 4 | 29G |
| Chaglm2 | zero2 | Não | Sim | 1 | 1560 | 1 | 35g |
| Chaglm2 | zero2 | Não | Não | 1 | 1560 | 1 | 36g |
| Chaglm2 | zero2 | Não | Sim | 1 | 1560 | 4 | 22G |
| Chaglm2 | zero2 | Não | Não | 1 | 1560 | 4 | 27G |
O método PT, a saber, o método de ajuste P, refere-se ao código oficial do ChatGLM, é um método de promoção suave para modelos grandes.
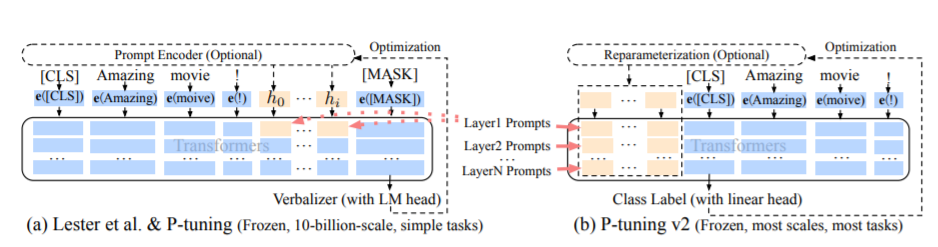
Para o código de ajuste fino, consulte Train.py, a parte principal é a seguinte:
config = MODE [ args . mode ][ "config" ]. from_pretrained ( args . model_name_or_path )
config . pre_seq_len = args . pre_seq_len
config . prefix_projection = args . prefix_projection
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path , config = config )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in [ "prefix_encoder" ]):
param . requires_grad = FalseQuando o prefix_projeção é verdadeiro, novos parâmetros são adicionados à incorporação e a cada camada do grande modelo; Quando falsos, novos parâmetros são adicionados apenas à incorporação do grande modelo.
Os códigos de treinamento são treinados usando o DeepSpeed. Os parâmetros podem ser definidos, incluindo trens_path, model_name_or_path, modo, trens_type, pre_seq_len, prefix_projection, ds_file, num_train_epochs, seu tathevice_train_batch_size, grad_acmulation_steps, ousad_dir, etc.
Treinamento de cartão único ChatGlm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 768
--max_src_len 512
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
O treinamento em quatro cartas do ChatGLM, CUDA_VISIBLE_DEVICES controla quais cartões são treinados. Se este parâmetro não for adicionado, significa que todos os cartões na máquina em execução serão treinados.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Treinamento de cartão único chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Treinamento de quatro cartões do ChatGlm2, Controle quais cartões são treinados através do CUDA_VISIBLE_DEVICES. Se este parâmetro não for adicionado, significa que todos os cartões na máquina em execução serão treinados.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Treinamento de cartão único ChatGlm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
Treinamento de quatro cartões do ChatGlm3, Controle quais cartões são treinados através do CUDA_VISIBLE_DEVICES. Se este parâmetro não for adicionado, significa que todos os cartões na máquina em execução serão treinados.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
PS: A memória de vídeo usada para ajuste fino do ChatGLM é mais do que a do ChatGlm2, e o vídeo detalhado é contabilizado para o seguinte:
| Modelo | DeepSpeed-Stay | Descarregar | Ponto de verificação de gradiente | Tamanho do lote | Comprimento máximo | Número GPU-A40 | Memória de vídeo consumida |
|---|---|---|---|---|---|---|---|
| Chaglm | zero2 | Não | Sim | 1 | 768 | 1 | 43g |
| Chaglm | zero2 | Não | Não | 1 | 300 | 1 | 44G |
| Chaglm | zero2 | Não | Sim | 1 | 1560 | 4 | 37G |
| Chaglm | zero2 | Não | Não | 1 | 1360 | 4 | 44G |
| Chaglm2 | zero2 | Não | Sim | 1 | 1560 | 1 | 20G |
| Chaglm2 | zero2 | Não | Não | 1 | 1560 | 1 | 40G |
| Chaglm2 | zero2 | Não | Sim | 1 | 1560 | 4 | 19G |
| Chaglm2 | zero2 | Não | Não | 1 | 1560 | 4 | 39G |
O método LORA, isto é, para adicionar matriz adicional de baixo rank aos parâmetros especificados (matriz de peso) em paralelo em modelos de linguagem grandes e durante o treinamento do modelo, apenas os parâmetros adicionais da matriz de baixo rank paralela são treinados. Quando o "valor da classificação" é muito menor que a dimensão do parâmetro original, o número de parâmetros de matriz de baixa classificação recém-adicionados também é muito pequeno. Ao ajustar as tarefas a jusante, apenas pequenos parâmetros devem ser treinados, mas bons resultados de desempenho podem ser obtidos.
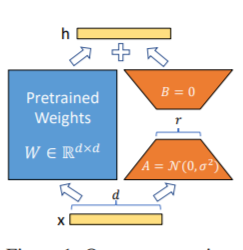
Para o código de ajuste fino, consulte Train.py, a parte principal é a seguinte:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )
lora_module_name = args . lora_module_name . split ( "," )
config = LoraConfig ( r = args . lora_dim ,
lora_alpha = args . lora_alpha ,
target_modules = lora_module_name ,
lora_dropout = args . lora_dropout ,
bias = "none" ,
task_type = "CAUSAL_LM" ,
inference_mode = False ,
)
model = get_peft_model ( model , config )
model . config . torch_dtype = torch . float32PS: Após o treinamento da Lora, mescle os parâmetros primeiro e faça previsões de modelos.
Os códigos de treinamento são treinados usando o DeepSpeed. Os parâmetros podem ser definidos, incluindo trens_path, model_name_or_path, modo, trens_type, lora_dim, lora_alpha, lora_dropout, lora_module_name, ds_file, num_train_epochs, percursice_train_batch_size, gradrain_act, gradrain, gradrain, gradrain, gradrain, gradrain, gradrain, gradrain, gradrain, grad De acordo com suas próprias tarefas.
Treinamento de cartão único ChatGlm
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
O treinamento em quatro cartas do ChatGLM, CUDA_VISIBLE_DEVICES controla quais cartões são treinados. Se este parâmetro não for adicionado, significa que todos os cartões na máquina em execução serão treinados.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Treinamento de cartão único chatglm2
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Treinamento de quatro cartões do ChatGlm2, Controle quais cartões são treinados através do CUDA_VISIBLE_DEVICES. Se este parâmetro não for adicionado, significa que todos os cartões na máquina em execução serão treinados.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Treinamento de cartão único ChatGlm3
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
Treinamento de quatro cartões do ChatGlm3, Controle quais cartões são treinados através do CUDA_VISIBLE_DEVICES. Se este parâmetro não for adicionado, significa que todos os cartões na máquina em execução serão treinados.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: A memória de vídeo usada para ajuste fino do ChatGLM é mais do que a do ChatGlm2, e o vídeo detalhado é contabilizado para o seguinte:
| Modelo | DeepSpeed-Stay | Descarregar | Ponto de verificação de gradiente | Tamanho do lote | Comprimento máximo | Número GPU-A40 | Memória de vídeo consumida |
|---|---|---|---|---|---|---|---|
| Chaglm | zero2 | Não | Sim | 1 | 1560 | 1 | 20G |
| Chaglm | zero2 | Não | Não | 1 | 1560 | 1 | 45g |
| Chaglm | zero2 | Não | Sim | 1 | 1560 | 4 | 20G |
| Chaglm | zero2 | Não | Não | 1 | 1560 | 4 | 45g |
| Chaglm2 | zero2 | Não | Sim | 1 | 1560 | 1 | 20G |
| Chaglm2 | zero2 | Não | Não | 1 | 1560 | 1 | 43g |
| Chaglm2 | zero2 | Não | Sim | 1 | 1560 | 4 | 19G |
| Chaglm2 | zero2 | Não | Não | 1 | 1560 | 4 | 42g |
Nota: O método Lora salva apenas os parâmetros de treinamento da LORA ao salvar o modelo, para que os parâmetros do modelo precisem ser mesclados ao prever o modelo. Para detalhes, consulte Merge_lora.py.
O método de parâmetro completo é usado para treinar o modelo grande em parâmetros completos. Ele usa principalmente o método DeepSpeed-Zero3 para dividir os parâmetros do modelo em várias placas e usa o método de descarga para descarregar os parâmetros de otimizador na CPU para resolver o problema das placas gráficas insuficientes.
Para o código de ajuste fino, consulte Train.py, a parte principal é a seguinte:
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )Os códigos de treinamento são treinados usando o DeepSpeed. Os parâmetros podem ser definidos, incluindo Train_Path, Model_Name_or_Path, Mode, Train_Type, DS_FILE, NUM_TRAIN_EPOCHS, PER_DEVICE_TRAIN_BATCH_SIZE, GRADIent_Accumulation_Steps, Output_Dir, etc., que podem ser configuidos de acordo com suas próprias tarefas.
O treinamento em quatro cartas do ChatGLM, CUDA_VISIBLE_DEVICES controla quais cartões são treinados. Se este parâmetro não for adicionado, significa que todos os cartões na máquina em execução serão treinados.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type all
--seed 1234
--ds_file ds_zero3_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Treinamento de quatro cartões do ChatGlm2, Controle quais cartões são treinados através do CUDA_VISIBLE_DEVICES. Se este parâmetro não for adicionado, significa que todos os cartões na máquina em execução serão treinados.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Treinamento de quatro cartões do ChatGlm3, Controle quais cartões são treinados através do CUDA_VISIBLE_DEVICES. Se este parâmetro não for adicionado, significa que todos os cartões na máquina em execução serão treinados.
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
PS: A memória de vídeo usada para ajuste fino do ChatGLM é mais do que a do ChatGlm2, e o vídeo detalhado é contabilizado para o seguinte:
| Modelo | DeepSpeed-Stay | Descarregar | Ponto de verificação de gradiente | Tamanho do lote | Comprimento máximo | Número GPU-A40 | Memória de vídeo consumida |
|---|---|---|---|---|---|---|---|
| Chaglm | zero3 | Sim | Sim | 1 | 1560 | 4 | 33g |
| Chaglm2 | zero3 | Não | Sim | 1 | 1560 | 4 | 44G |
| Chaglm2 | zero3 | Sim | Sim | 1 | 1560 | 4 | 26g |
A seguir, é apresentada uma descrição do conteúdo relevante do estágio zero da DeepSpeed.
Exibir requisitos.txt arquivo
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为"性能故障", "部件故障", "组成"和 "检测工具"的相关三元组,三元组内部用"_"连接,三元组之间用\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高n风扇_部件故障_低速转动"
}
| Método de ajuste fino | Somente embebido em PT | Pt | Congelar | Lora |
|---|---|---|---|---|
| Resultados do teste F1 | 0,0 | 0,6283 | 0,5675 | 0,5359 |
Análise Estrutural:
Muitos estudantes experimentaram esquecimento catastrófico após o ajuste fino, mas o código de treinamento deste projeto não apareceu. Eles testaram a "tarefa de tradução", "tarefa de código" e "tarefa de perguntas e respostas". Os resultados específicos dos testes são os seguintes:


{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
Como o conteúdo do modelo generativo não pode ser avaliado como a tarefa de extração da informação, não é apropriado usar o azul ou o ROUGE existente para avaliar, portanto, uma regra de pontuação foi formulada. O modelo D2Q é julgado pelas duas perspectivas de diversidade e precisão. Cada amostra tem um total de 5 pontos, com um total de 20 amostras.
| Método de ajuste fino | Modelo original | Somente embebido em PT | Pt | Congelar | Lora |
|---|---|---|---|---|---|
| Fração | 51.75 | 73.75 | 87,75 | 79.25 | 86,75 |
Veja a descrição do código: Paralelismo do pipeline (pipeline) Prática
Por favor, veja a tag v0.1


