ChatGLM Finetuning
v0.1
이 프로젝트는 주로 ChatGLM, ChatGLM2 및 ChatGLM3 모델에 대한 다양한 방식 (Freeze Method, LORA 메소드, P 튜닝 메소드, 전체 매개 변수 등)으로 미세 조정을 수행하고 대규모 모델의 영향을 다양한 미세 조정 방법, 주로 정보 추출 작업, 생성 작업, 분류 작업 등을 대상으로합니다.
이 프로젝트는 단일 카드 교육 및 다중 카드 교육을 지원합니다. 단일 명령어 세트 미세 조정으로 인해 모델을 미세 조정 한 후에는 심각한 치명적인 잊을 수 없습니다 .
공식 코드와 모델이 업데이트되었으므로 ChatGLM1 및 2의 현재 코드 및 모델은 버전 20230806입니다 (코드가 잘못 실행되면 파일의 PY 파일을 ChatGLM 관련 소스 코드로 바꾸면이 프로젝트의 코드 버전과 비해서 없을 수 있기 때문입니다). ChatGLM3은 버전 20231212입니다.
추신 : 트레이너 사용은 없습니다 (트레이너 코드는 간단하지만 수정하기는 쉽지 않습니다. 대형 모델의 시대에는 알고리즘 엔지니어가 데이터 엔지니어가되었으므로 교육 프로세스를 더 이해해야합니다).
모델을 미세 조정할 때 비디오 메모리가 충분하지 않은 경우 Gradient_checkpointing, Zero3 및 Offload와 같은 매개 변수를 켜서 비디오 메모리를 저장할 수 있습니다.
다음 model_name_or_path 매개 변수는 모델 경로입니다. 실제 모델에 따라 저장할 수있는 주소에 따라 수정하십시오.
동결 방법, 즉 매개 변수 동결 및 일부 매개 변수는 원래 모델에 대해 동결되며 일부 매개 변수 만 단일 또는 여러 카드를 달성하도록 훈련됩니다. TP 또는 PP 작업이 수행되지 않으면 큰 모델을 교육 할 수 있습니다.
미세 조정 코드의 경우 Train.py를 참조하십시오. 핵심 부분은 다음과 같습니다.
freeze_module_name = args . freeze_module_name . split ( "," )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in freeze_module_name ):
param . requires_grad = False모델의 다른 레이어로 수정하려면 Freeze_Module_name 매개 변수 구성을 직접 수정할 수 있습니다. "Layers.27., Layers.26., Layers.25., Layers.24". 훈련 코드는 모두 깊이를 사용하여 훈련됩니다. train_path, model_name_or_path, mode, train_type, freeze_module_name, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir 등을 포함하여 매개 변수를 설정할 수 있으며 자신의 작업에 따라 구성 할 수 있습니다.
chatglm 단일 카드 교육
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Chatglm 4 카드 교육, cuda_visible_devices 컨트롤 어떤 카드가 훈련되는지 컨트롤. 이 매개 변수가 추가되지 않으면 러닝 머신의 모든 카드가 훈련되었음을 의미합니다.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGLM2 단일 카드 교육
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Chatglm2 4 카드 교육, Cuda_visible_devices를 통해 훈련되는 카드를 제어합니다. 이 매개 변수가 추가되지 않으면 러닝 머신의 모든 카드가 훈련되었음을 의미합니다.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGLM3 단일 카드 교육
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
Chatglm3 4 카드 교육, Cuda_visible_devices를 통해 훈련되는 카드 컨트롤. 이 매개 변수가 추가되지 않으면 러닝 머신의 모든 카드가 훈련되었음을 의미합니다.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type freeze
--freeze_module_name "layers.27.,layers.26.,layers.25.,layers.24."
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
추신 : ChatGLM의 미세 조정에 사용되는 비디오 메모리는 ChatGLM2보다 많으며 자세한 비디오 메모리는 다음을 설명합니다.
| 모델 | 깊은 속도 단계 | 짐을 내리다 | 그라디언트 체크 패인팅 | 배치 크기 | 최대 길이 | GPU-A40 번호 | 소비 된 비디오 메모리 |
|---|---|---|---|---|---|---|---|
| chaglm | Zero2 | 아니요 | 예 | 1 | 1560 | 1 | 36g |
| chaglm | Zero2 | 아니요 | 아니요 | 1 | 1560 | 1 | 38g |
| chaglm | Zero2 | 아니요 | 예 | 1 | 1560 | 4 | 24g |
| chaglm | Zero2 | 아니요 | 아니요 | 1 | 1560 | 4 | 29g |
| chaglm2 | Zero2 | 아니요 | 예 | 1 | 1560 | 1 | 35g |
| chaglm2 | Zero2 | 아니요 | 아니요 | 1 | 1560 | 1 | 36g |
| chaglm2 | Zero2 | 아니요 | 예 | 1 | 1560 | 4 | 22g |
| chaglm2 | Zero2 | 아니요 | 아니요 | 1 | 1560 | 4 | 27g |
PT 방법, 즉 p- 튜닝 방법은 공식 ChatGLM 코드를 지칭하며 대형 모델에 대한 소프트 프롬프트 방법입니다.
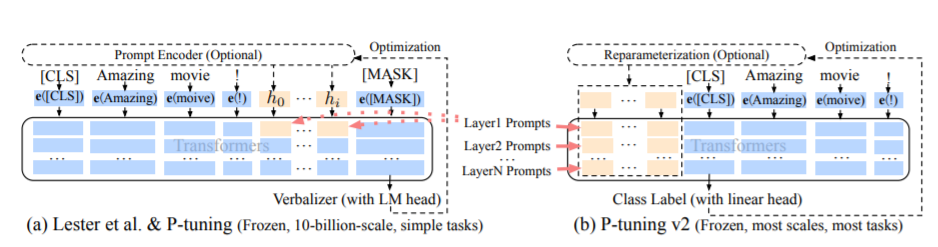
미세 조정 코드의 경우 Train.py를 참조하십시오. 핵심 부분은 다음과 같습니다.
config = MODE [ args . mode ][ "config" ]. from_pretrained ( args . model_name_or_path )
config . pre_seq_len = args . pre_seq_len
config . prefix_projection = args . prefix_projection
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path , config = config )
for name , param in model . named_parameters ():
if not any ( nd in name for nd in [ "prefix_encoder" ]):
param . requires_grad = Falseprefix_projection이 true 일 때, 새로운 매개 변수는 큰 모델의 임베딩 및 각 층에 추가됩니다. False 일 때, 새로운 매개 변수는 큰 모델의 임베딩에만 추가됩니다.
교육 코드는 DeepSpeed를 사용하여 교육됩니다. train_path, model_name_or_path, mode, train_type, pre_seq_len, prefix_projection, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir 등을 포함하여 매개 변수를 설정할 수 있으며, 자신의 작업에 따라 구성 할 수 있습니다.
chatglm 단일 카드 교육
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 768
--max_src_len 512
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
Chatglm 4 카드 교육, cuda_visible_devices 컨트롤 어떤 카드가 훈련되는지 컨트롤. 이 매개 변수가 추가되지 않으면 러닝 머신의 모든 카드가 훈련되었음을 의미합니다.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm
ChatGLM2 단일 카드 교육
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
Chatglm2 4 카드 교육, Cuda_visible_devices를 통해 훈련되는 카드를 제어합니다. 이 매개 변수가 추가되지 않으면 러닝 머신의 모든 카드가 훈련되었음을 의미합니다.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm2
ChatGLM3 단일 카드 교육
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
Chatglm3 4 카드 교육, Cuda_visible_devices를 통해 훈련되는 카드 컨트롤. 이 매개 변수가 추가되지 않으면 러닝 머신의 모든 카드가 훈련되었음을 의미합니다.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type ptuning
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--pre_seq_len 16
--prefix_projection True
--output_dir ./output-glm3
추신 : ChatGLM의 미세 조정에 사용되는 비디오 메모리는 ChatGLM2보다 많으며 자세한 비디오 메모리는 다음을 설명합니다.
| 모델 | 깊은 속도 단계 | 짐을 내리다 | 그라디언트 체크 패인팅 | 배치 크기 | 최대 길이 | GPU-A40 번호 | 소비 된 비디오 메모리 |
|---|---|---|---|---|---|---|---|
| chaglm | Zero2 | 아니요 | 예 | 1 | 768 | 1 | 43g |
| chaglm | Zero2 | 아니요 | 아니요 | 1 | 300 | 1 | 44g |
| chaglm | Zero2 | 아니요 | 예 | 1 | 1560 | 4 | 37g |
| chaglm | Zero2 | 아니요 | 아니요 | 1 | 1360 | 4 | 44g |
| chaglm2 | Zero2 | 아니요 | 예 | 1 | 1560 | 1 | 20g |
| chaglm2 | Zero2 | 아니요 | 아니요 | 1 | 1560 | 1 | 40g |
| chaglm2 | Zero2 | 아니요 | 예 | 1 | 1560 | 4 | 19g |
| chaglm2 | Zero2 | 아니요 | 아니요 | 1 | 1560 | 4 | 39g |
LORA 방법, 즉 대형 언어 모델에서 병렬로 지정된 매개 변수 (중량 매트릭스)에 추가 저급 매트릭스를 추가하고 모델 훈련 중에 평행 한 저 순위 매트릭스의 추가 매개 변수 만 훈련됩니다. "순위 값"이 원래 매개 변수 차원보다 훨씬 작은 경우 새로 추가 된 저급 행렬 매개 변수의 수도 매우 작습니다. 다운 스트림 작업을 조정할 때는 작은 매개 변수 만 교육해야하지만 성능이 우수한 결과를 얻을 수 있습니다.
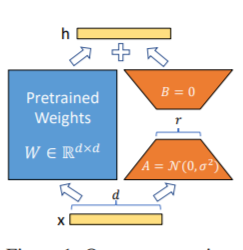
미세 조정 코드의 경우 Train.py를 참조하십시오. 핵심 부분은 다음과 같습니다.
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )
lora_module_name = args . lora_module_name . split ( "," )
config = LoraConfig ( r = args . lora_dim ,
lora_alpha = args . lora_alpha ,
target_modules = lora_module_name ,
lora_dropout = args . lora_dropout ,
bias = "none" ,
task_type = "CAUSAL_LM" ,
inference_mode = False ,
)
model = get_peft_model ( model , config )
model . config . torch_dtype = torch . float32추신 : LORA 교육 후에는 먼저 매개 변수를 병합하고 모델 예측을하십시오.
교육 코드는 DeepSpeed를 사용하여 교육됩니다. Train_Path, model_name_or_path, mode, train_type, lora_dim, lora_alpha, lora_dropout, lora_module_name, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation votputseps, and gradient_accumulation _stepssecsse, gradient_accumulation을 포함하여 매개 변수를 설정할 수 있습니다. 자신의 작업에 따라 구성되었습니다.
chatglm 단일 카드 교육
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Chatglm 4 카드 교육, cuda_visible_devices 컨트롤 어떤 카드가 훈련되는지 컨트롤. 이 매개 변수가 추가되지 않으면 러닝 머신의 모든 카드가 훈련되었음을 의미합니다.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
ChatGLM2 단일 카드 교육
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Chatglm2 4 카드 교육, Cuda_visible_devices를 통해 훈련되는 카드를 제어합니다. 이 매개 변수가 추가되지 않으면 러닝 머신의 모든 카드가 훈련되었음을 의미합니다.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type lora
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
ChatGLM3 단일 카드 교육
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
Chatglm3 4 카드 교육, Cuda_visible_devices를 통해 훈련되는 카드 컨트롤. 이 매개 변수가 추가되지 않으면 러닝 머신의 모든 카드가 훈련되었음을 의미합니다.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B/
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--lora_dim 16
--lora_alpha 64
--lora_dropout 0.1
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense"
--seed 1234
--ds_file ds_zero2_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
추신 : ChatGLM의 미세 조정에 사용되는 비디오 메모리는 ChatGLM2보다 많으며 자세한 비디오 메모리는 다음을 설명합니다.
| 모델 | 깊은 속도 단계 | 짐을 내리다 | 그라디언트 체크 패인팅 | 배치 크기 | 최대 길이 | GPU-A40 번호 | 소비 된 비디오 메모리 |
|---|---|---|---|---|---|---|---|
| chaglm | Zero2 | 아니요 | 예 | 1 | 1560 | 1 | 20g |
| chaglm | Zero2 | 아니요 | 아니요 | 1 | 1560 | 1 | 45g |
| chaglm | Zero2 | 아니요 | 예 | 1 | 1560 | 4 | 20g |
| chaglm | Zero2 | 아니요 | 아니요 | 1 | 1560 | 4 | 45g |
| chaglm2 | Zero2 | 아니요 | 예 | 1 | 1560 | 1 | 20g |
| chaglm2 | Zero2 | 아니요 | 아니요 | 1 | 1560 | 1 | 43g |
| chaglm2 | Zero2 | 아니요 | 예 | 1 | 1560 | 4 | 19g |
| chaglm2 | Zero2 | 아니요 | 아니요 | 1 | 1560 | 4 | 42G |
참고 : LORA 메소드는 모델을 저장할 때만 LORA 교육 매개 변수를 저장하므로 모델 매개 변수는 모델을 예측할 때 병합되어야합니다. 자세한 내용은 merge_lora.py를 참조하십시오.
전체 매개 변수 방법은 전체 매개 변수로 큰 모델을 훈련시키는 데 사용됩니다. 주로 DeepSpeed-Zero3 메소드를 사용하여 모델 매개 변수를 여러 카드로 나누고 오프로드 방법을 사용하여 Optimizer 매개 변수를 CPU에 언로드하여 그래픽 카드가 충분하지 않은 문제를 해결합니다.
미세 조정 코드의 경우 Train.py를 참조하십시오. 핵심 부분은 다음과 같습니다.
model = MODE [ args . mode ][ "model" ]. from_pretrained ( args . model_name_or_path )교육 코드는 DeepSpeed를 사용하여 교육됩니다. train_path, model_name_or_path, mode, train_type, ds_file, num_train_epochs, per_device_train_batch_size, gradient_accumulation_steps, output_dir 등을 포함하여 매개 변수를 설정할 수 있습니다.
Chatglm 4 카드 교육, cuda_visible_devices 컨트롤 어떤 카드가 훈련되는지 컨트롤. 이 매개 변수가 추가되지 않으면 러닝 머신의 모든 카드가 훈련되었음을 의미합니다.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm
--train_type all
--seed 1234
--ds_file ds_zero3_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm
Chatglm2 4 카드 교육, Cuda_visible_devices를 통해 훈련되는 카드를 제어합니다. 이 매개 변수가 추가되지 않으면 러닝 머신의 모든 카드가 훈련되었음을 의미합니다.
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM2-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm2
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm2
Chatglm3 4 카드 교육, Cuda_visible_devices를 통해 훈련되는 카드 컨트롤. 이 매개 변수가 추가되지 않으면 러닝 머신의 모든 카드가 훈련되었음을 의미합니다.
CCUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py
--train_path data/spo_0.json
--model_name_or_path ChatGLM3-6B
--per_device_train_batch_size 1
--max_len 1560
--max_src_len 1024
--learning_rate 1e-4
--weight_decay 0.1
--num_train_epochs 2
--gradient_accumulation_steps 4
--warmup_ratio 0.1
--mode glm3
--train_type all
--seed 1234
--ds_file ds_zero3_no_offload.json
--gradient_checkpointing
--show_loss_step 10
--output_dir ./output-glm3
추신 : ChatGLM의 미세 조정에 사용되는 비디오 메모리는 ChatGLM2보다 많으며 자세한 비디오 메모리는 다음을 설명합니다.
| 모델 | 깊은 속도 단계 | 짐을 내리다 | 그라디언트 체크 패인팅 | 배치 크기 | 최대 길이 | GPU-A40 번호 | 소비 된 비디오 메모리 |
|---|---|---|---|---|---|---|---|
| chaglm | Zero3 | 예 | 예 | 1 | 1560 | 4 | 33g |
| chaglm2 | Zero3 | 아니요 | 예 | 1 | 1560 | 4 | 44g |
| chaglm2 | Zero3 | 예 | 예 | 1 | 1560 | 4 | 26G |
다음은 DeepSpeed의 제로 단계의 관련 내용에 대한 설명입니다.
요구 사항을 봅니다 .txt 파일
{
"instruction": "你现在是一个信息抽取模型,请你帮我抽取出关系内容为"性能故障", "部件故障", "组成"和 "检测工具"的相关三元组,三元组内部用"_"连接,三元组之间用\n分割。文本:",
"input": "故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。",
"output": "发动机_部件故障_水温高n风扇_部件故障_低速转动"
}
| 미세 조정 방법 | PT 전용 엠 베딩 | Pt | 꼭 매달리게 하다 | 로라 |
|---|---|---|---|---|
| 테스트 결과 F1 | 0.0 | 0.6283 | 0.5675 | 0.5359 |
구조 분석 :
많은 학생들이 미세 조정 후 치명적인 잊어 버렸지만이 프로젝트의 훈련 코드는 나타나지 않았습니다. 그들은 "번역 작업", "코드 작업"및 "질문 및 답변 작업"을 테스트했습니다. 특정 테스트 결과는 다음과 같습니다.


{
"instruction": "你现在是一个问题生成模型,请根据下面文档生成一个问题,文档:",
"input": "清热解毒口服液由生石膏、知母、紫花地丁、金银花、麦门冬、黄芩、玄参、连翘、龙胆草、生地黄、栀子、板蓝根组成。具有疏风解表、清热解毒利咽、生津止渴的功效,适用于治疗外感时邪、内有蕴热所致的身热汗出、头痛身痛、心烦口渴、微恶寒或反恶热、舌红、苔黄、脉数等症。现代临床主要用于治疗流行性感冒、流行性脑脊髓膜炎、肺炎等各种发热性疾病。口服液:每支10毫升,每次10~20毫升,每日3次。〔注意事项〕阳虚便澹者不宜使用。",
"output": "清热解毒口服的功效有哪些?"
}
생성 모델의 내용은 정보 추출 작업과 같이 평가 될 수 없으므로 기존 블루 또는 루즈를 사용하여 평가하는 것이 적절하지 않으므로 점수 규칙이 공식화되었습니다. D2Q 모델은 다양성과 정확도의 두 가지 관점을 통해 판단됩니다. 각 샘플에는 총 5 개의 포인트가 있으며 총 20 개의 샘플이 있습니다.
| 미세 조정 방법 | 원본 모델 | PT 전용 엠 베딩 | Pt | 꼭 매달리게 하다 | 로라 |
|---|---|---|---|---|---|
| 분수 | 51.75 | 73.75 | 87.75 | 79.25 | 86.75 |
코드 설명 : 파이프 라인 병렬 처리 (파이프 라인) 실습을 참조하십시오
V0.1 태그를 참조하십시오


