pyinnovativetrend
1.0.0
趨勢分析是一種統計技術,用於檢查數據,以確定特定方向的模式,趨勢或運動。它被廣泛用於金融,經濟學,營銷,環境科學等各個領域。檢測趨勢的一種非常常見的傳統方法是Mann-Kendall趨勢測試由Mann和Kendall提出。但是,由於其簡單性和圖形特徵,SEN(2012)提出的一種創新方法現在被廣泛使用。這種創新的趨勢分析方法非常敏感,可以檢測到MK測試等常規方法忽略的趨勢。
該軟件包是使用PIP安裝的:
pip install pyinnovativetrend
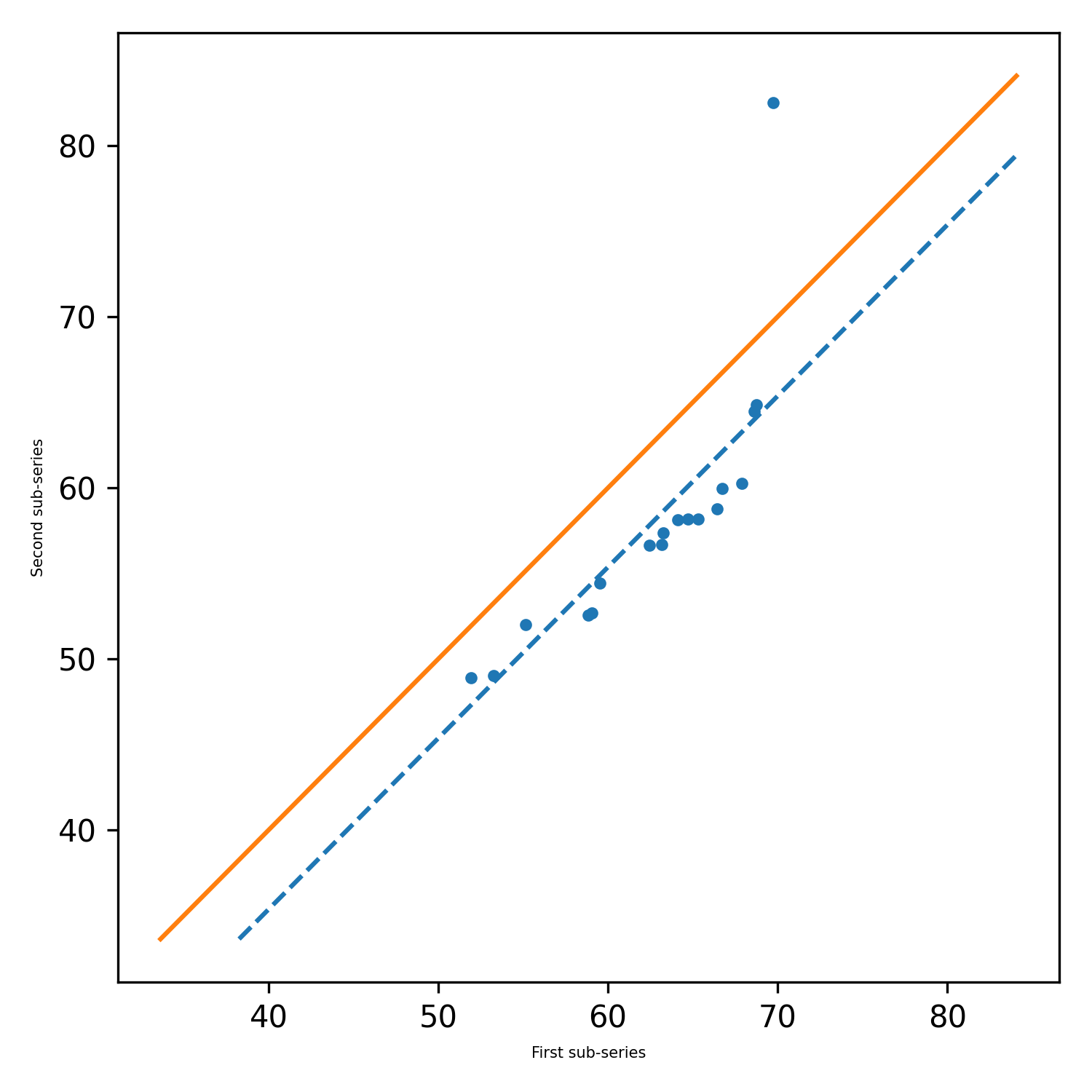
pyinnovativetrend.ita_single(x,長度,alpha = 0.05,graph = {},showgraph = true)
此功能計算單個列表或numpy數組的趨勢和其他必要參數,並返回命名元組。默認情況下,圖表將說明並保存在本地計算機上。
例子:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single(x, 12, graph = graph)
輸出:ITA(趨勢='no趨勢',h = false,p = 0.20494777839420626,z = -1.2675805428826508,SLOPE = -0.027777777777777777777752,standard_deviation = 1.25555555543262626262805, slope_standard_deviation = 0.021914014011770254,相關= 0.9341987329938274,lower_critation_level = -0.04295067821977758
ita_multiple_by_station(長度,fileName = [],column = [],devefcolumn = [],graph = {},alpha = 0.05,rnd = 2,csv = false,directory_path =“ ./” ./“ ./”,output = []
此功能計算多個站點的趨勢和其他必要參數。數據是從Excel或CSV文件中從所需或根目錄中檢索的,結果將保存為Excel格式,由所需或根目錄上的電台排序。默認情況下,用電台排序的多個圖表被說明並保存在所需目錄或根目錄的本地計算機上。
例子:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_station(38, exceptcolumn=['Year'], graph = graph)
輸出:
Excel文件示例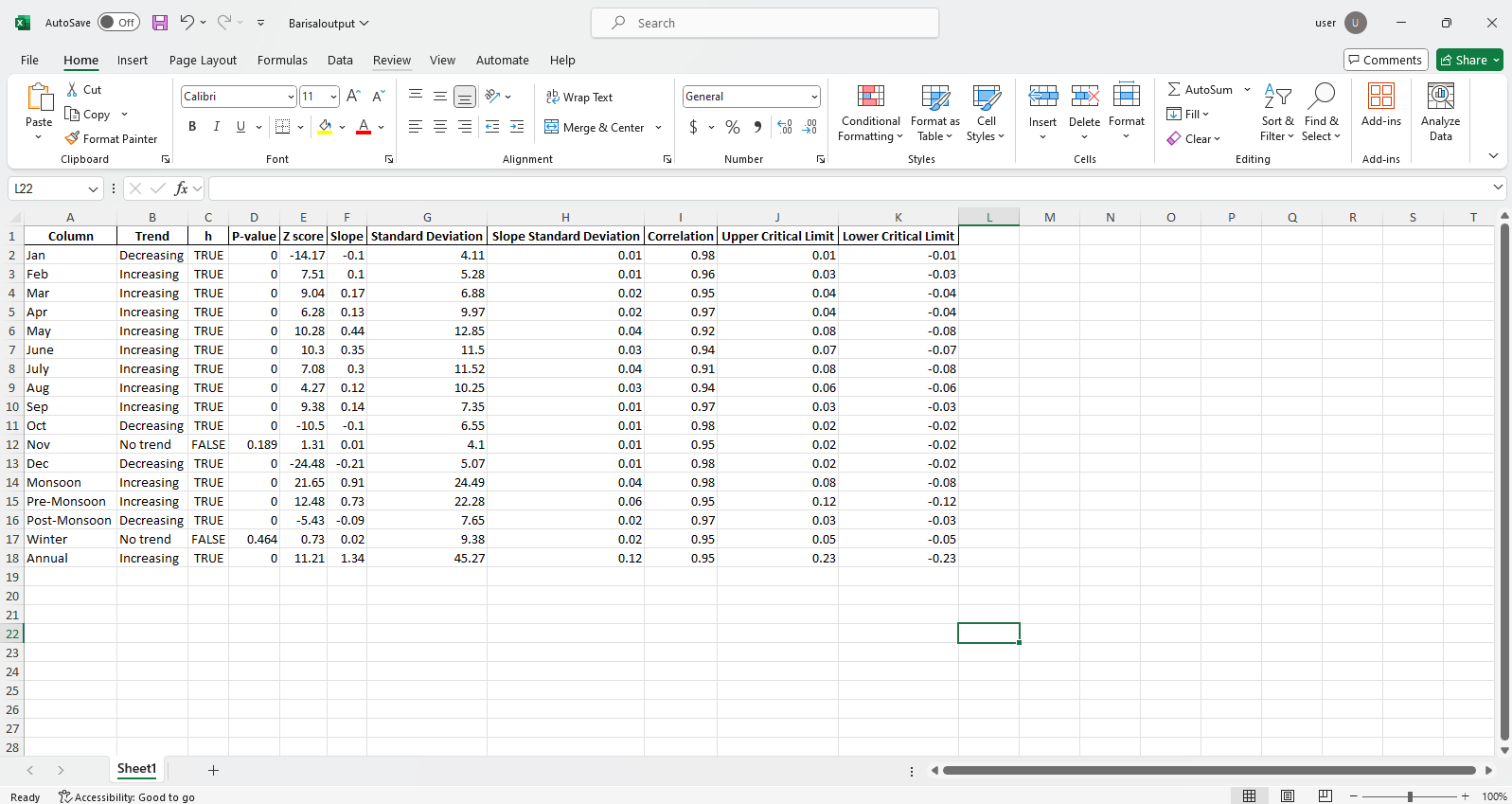 圖樣本
圖樣本
pyinnovativetrend.ita_multiple_by_station(長度,fileName = [],column = [],devefcolumn = [],graph = {},alpha = 0.05,rnd = 2,rnd = 2,csv = false,directory_path =“。
此功能計算多個站點的趨勢和其他必要參數。數據是從Excel或CSV文件中從所需或根目錄中檢索的,結果保存為Excel格式,由所需或根目錄上的列排序。默認情況下,用列排序的多個圖表被說明並保存在所需目錄或根目錄的本地計算機上。
例子:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_column(38, exceptcolumn=['Year'], graph = graph)
輸出:
Excel文件示例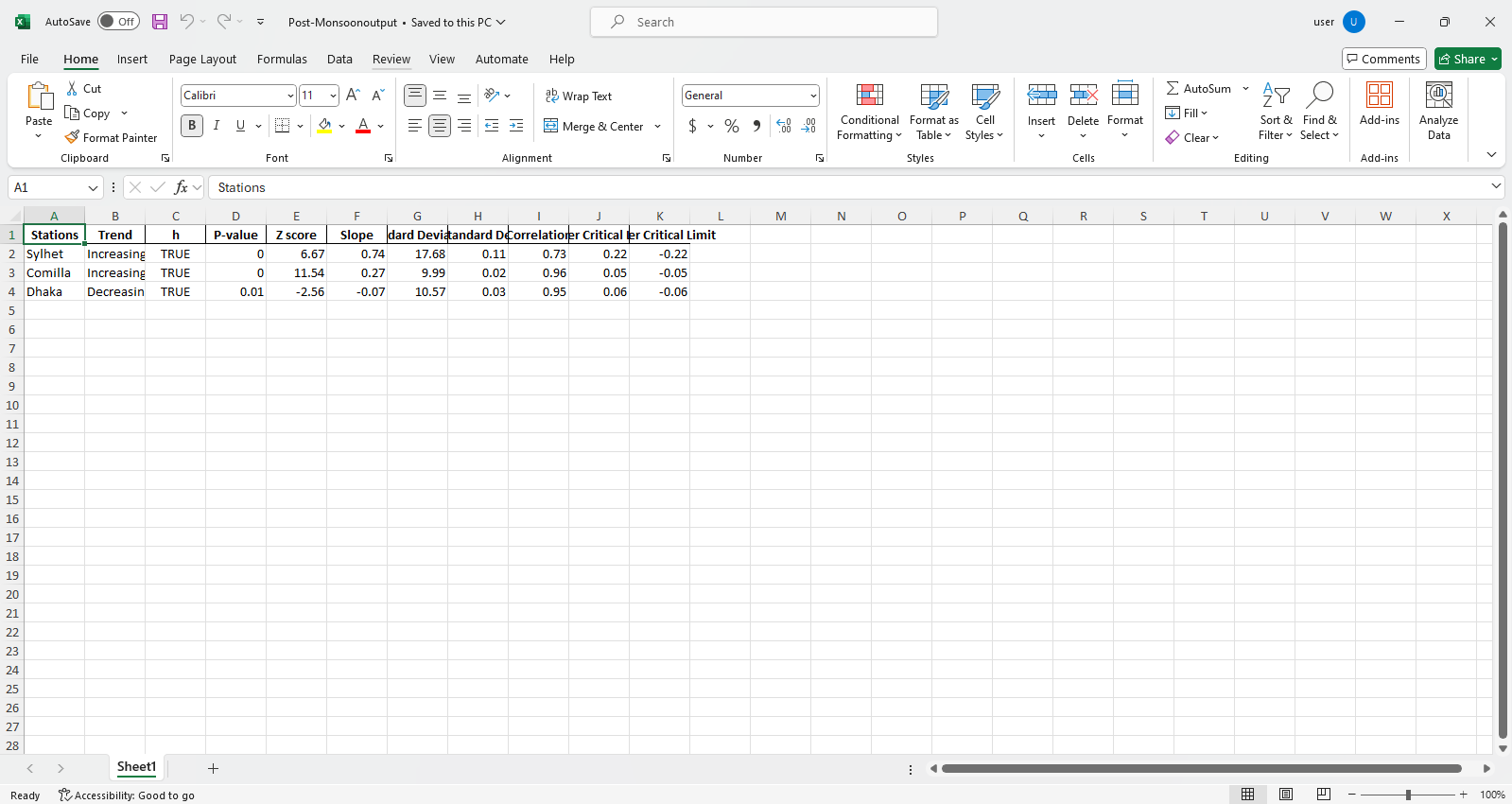 圖樣本
圖樣本
pyinnovativetrend.ita_single_vis(x,length,figsize =(10,10),graph = {})
此功能說明了圖並保存在本地計算機上。
例子:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single_vis(x, 12, graph = graph)
輸出:
pyinnovativetrend.ita_multiple_vis_by_station(長度,gruph = {},filename = [],column = [],decteclumn = [],csv = false,directory_path =“ ./”)
此功能說明了由電台排序的多個圖形,並保存在所需目錄或根目錄上的本地計算機上。數據是從Excel或CSV文件中從所需或根目錄中檢索的,結果將保存為Excel格式,由所需或根目錄上的電台排序。例子:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
輸出:
pyinnovativetrend.ita_multiple_vis_by_column(長度,gruph = {},filename = [],column = [],excestcolumn = [],csv = false,directory_path =“ ./” ./”)
此功能說明了由電台排序的多個圖形,並保存在所需目錄或根目錄上的本地計算機上。數據是從Excel或CSV文件中從所需或根目錄中檢索的,結果保存為Excel格式,由所需或根目錄上的列排序。例子:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
輸出:
X:列表或numpy數組
時間序列或數據系列的趨勢要確定
長度:整數
時間序列的長度。如果給定時間序列的長度很奇怪,則最早/第一個條目將被授予。
文件名:列表默認所有Excel/CSV文件
包含按月/年/季節排序數據的文件或電台列表。
列:列表默認所有列
包含數據的列或數據序列列表。
除外:列表默認空名單
不需要分析的列列表(例如,年度列)。
CSV:BOOL默認錯誤文件類型。默認情況下,文件類型為Excel。但是,如果文件為CSV格式,則應將CSV分配給TRUE。
Directory_path:字符串默認根
存儲文件的文件的目錄路徑。
輸出:列表默認站名稱或列名稱
將保存結果的文件的名稱。
out_direc:字符串默認根
將保存結果的文件的目錄路徑。
alpha:float默認值0.05
兩尾測試的顯著性水平。
showgraph:bool默認為true
選擇是否要在單個分析中與計算進行說明。
圖:Python字典(可選)默認值'Trendlinestyle':“虛線”#趨勢線風格,有關Matplotlib的更多線樣式訪問訪問文檔
“ Scattermarker”:'。 ' #標記類型的分散數據點,有關Matplotlib的更多標記訪問文檔
“標題':'#圖形或插圖的標題
'xlabel':'第一個子系列'#x軸標籤
'ylabel':'第二個子系列'#y軸標籤
'notrendlinestyle':“固體”#無趨勢線的線樣式或1:1行,有關更多行樣式類型訪問matplotlib的文檔
'output_dir':'./'#要保存圖形的輸出文件目錄
'output_name':'outputfig.png'#圖形或插圖的名稱
'dpi':圖或插圖的300#點每英寸(DPI)
“行”: - #子圖的行號。如果不提供,將自動計算。 (僅用於多次分析)
'Colm': - #子圖的列號。如果不提供,將自動計算。 (僅用於多次分析)
趨勢:
告訴趨勢是否存在和趨勢類型
H:
真實(如果存在趨勢)和錯誤(如果不存在趨勢)
P:
重大測試的P值(2尾測試)
Z:
歸一化測試統計(2尾測試)
坡:
趨勢
standard_deviation:
數據系列的標準偏差
slope_standard_deviation:
坡度相關的標準偏差:
分類子系列之間的相關性
lower_critical_level:
降低2尾測試的臨界價值
upper_critical_level:
2尾測試的高臨界價值


