pyinnovativetrend
1.0.0
Analisis tren adalah teknik statistik yang digunakan untuk memeriksa data dari waktu ke waktu untuk mengidentifikasi pola, tren, atau pergerakan ke arah tertentu. Ini banyak digunakan di berbagai bidang seperti keuangan, ekonomi, pemasaran, ilmu lingkungan, dan banyak lainnya. Metode yang sangat umum dan konvensional untuk mendeteksi tren adalah uji tren Mann-Kendall yang diusulkan oleh Mann dan Kendall. Namun, metode inovatif, yang diusulkan oleh Sen (2012), banyak digunakan sekarang-a-hari karena kesederhanaan dan fitur grafisnya. Metode analisis tren inovatif ini sangat sensitif dan dapat mendeteksi tren yang diabaikan oleh metode konvensional seperti uji MK.
Paket diinstal menggunakan PIP:
pip install pyinnovativetrend
pyinnovativetrend.ita_single (x, panjang, alpha = 0,05, grafik = {}, showgraph = true)
Fungsi ini menghitung tren dan parameter lain yang diperlukan untuk daftar tunggal atau array numpy dan mengembalikan tuple bernama. Secara default, grafik diilustrasikan dan disimpan di mesin lokal.
Contoh:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
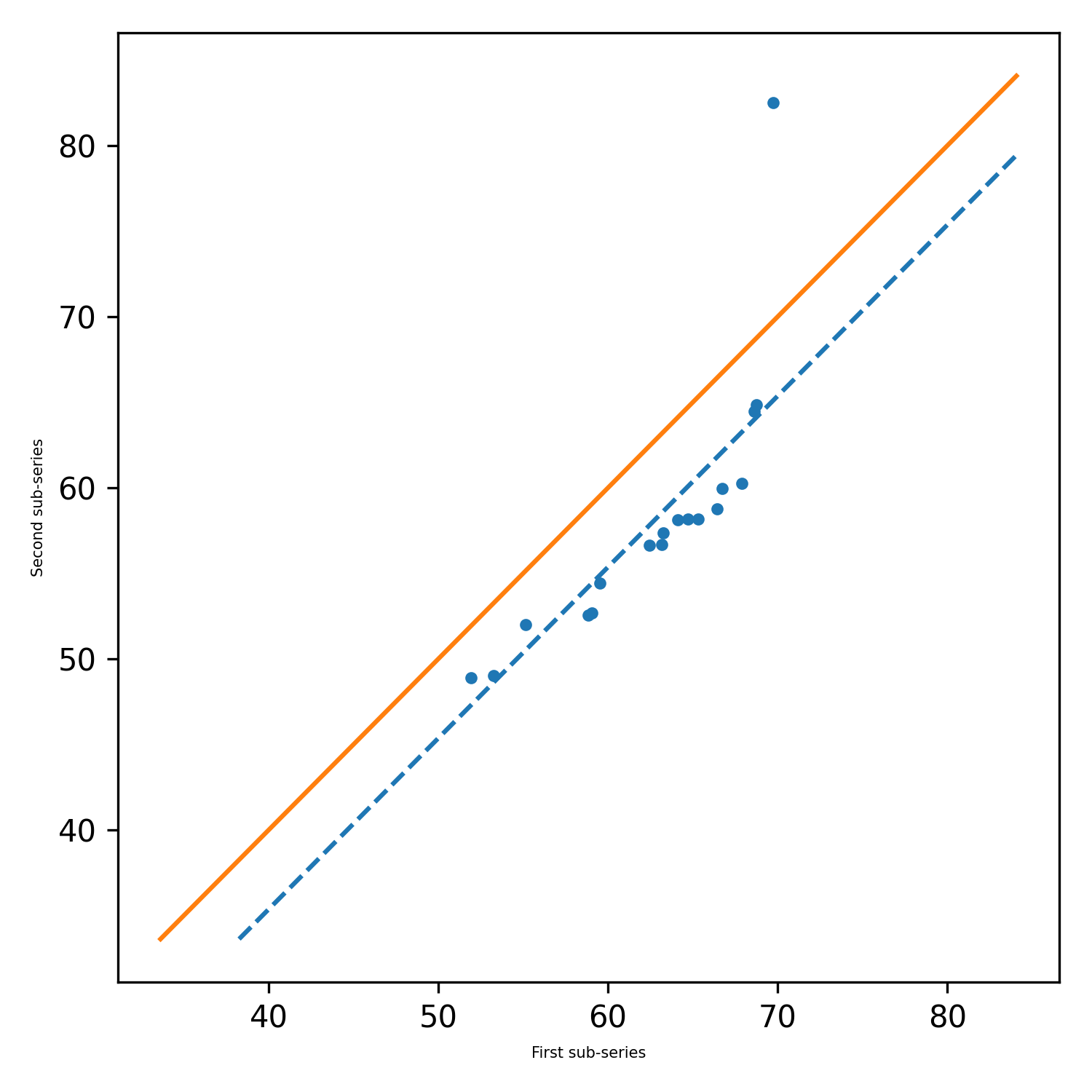
pit.ITA_single(x, 12, graph = graph)
Output: ITA (tren = 'tidak ada tren', h = false, p = 0,2049477839420626, z = -1.2675805428826508, slope = -0.0277777777777752, standar_deviasi = 1.25554434432777752, Standard_Deviation = 1.25554434344324432, Standard_Deviation = 1.2554443443432, Standard_Deviation = 1.255443333247777752, Standard_Deviation = 1.25544334432, Standard_Deviation = 1.25. slope_standard_deviation = 0.021914014011770254, korelasi = 0.9341987329938274, lower_critical_level = -0.042950678219758, ever_critical_level = 0,042997828), ever_critical_level = 0,042978828), ever_critical_level = 0,0429788
Ita_multiple_by_station (panjang, filename = [], column = [], kecualicolumn = [], grafik = {}, alpha = 0,05, rnd = 2, csv = false, directory_path = "./", output = [], out_direc = "./")
Fungsi ini menghitung tren dan parameter lain yang diperlukan untuk beberapa stasiun. Data diambil dari file Excel atau CSV dari direktori yang diinginkan atau root dan hasilnya disimpan sebagai format Excel diurutkan berdasarkan stasiun pada direktori yang diinginkan atau root. Secara default, beberapa grafik diurutkan berdasarkan stasiun diilustrasikan dan disimpan pada mesin lokal pada direktori atau direktori root yang diinginkan.
Contoh:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_station(38, exceptcolumn=['Year'], graph = graph)
Keluaran:
Sampel File Excel 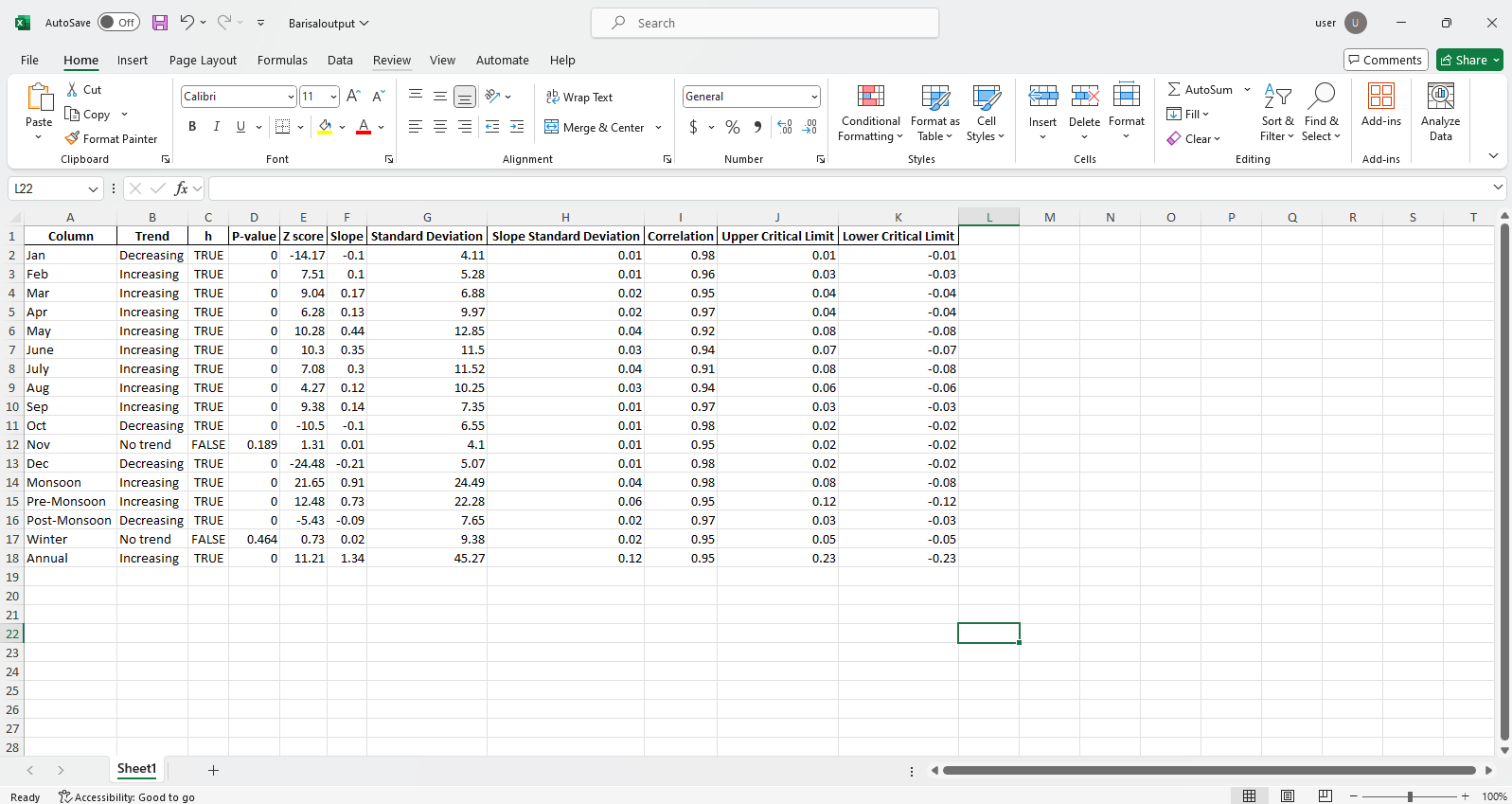 Sampel gambar
Sampel gambar 
pyinnovativetrend.ita_multiple_by_station (length, filename = [], column = [], kecuali Column = [], grafik = {}, alpha = 0,05, rnd = 2, csv = false, directory_path = "./", output = [], out_direc = ".
Fungsi ini menghitung tren dan parameter lain yang diperlukan untuk beberapa stasiun. Data diambil dari file Excel atau CSV dari direktori yang diinginkan atau root dan hasilnya disimpan sebagai format Excel diurutkan berdasarkan kolom pada direktori yang diinginkan atau root. Secara default, beberapa grafik diurutkan berdasarkan kolom diilustrasikan dan disimpan pada mesin lokal pada direktori atau direktori root yang diinginkan.
Contoh:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_column(38, exceptcolumn=['Year'], graph = graph)
Keluaran:
Sampel File Excel 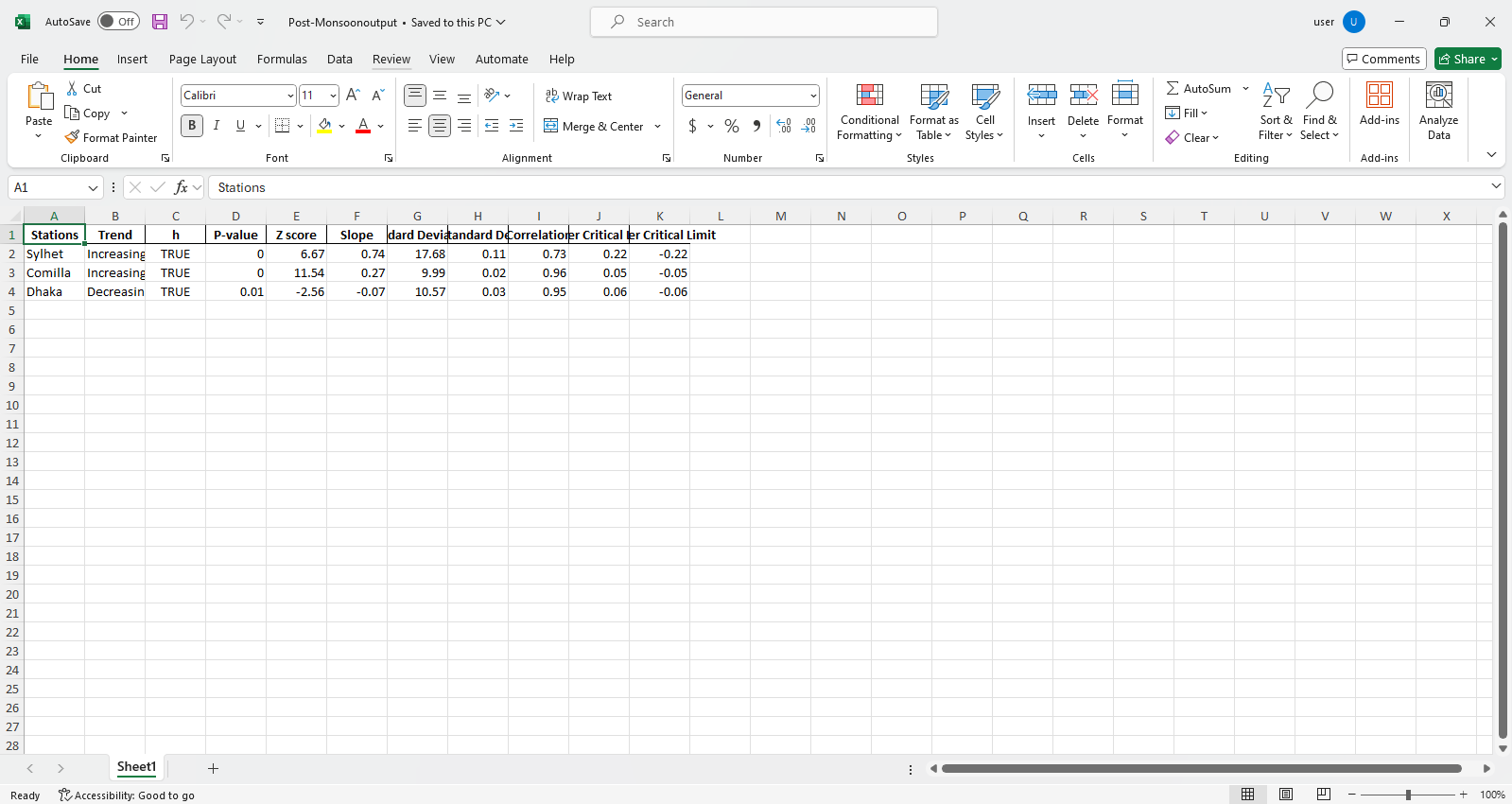 Sampel gambar
Sampel gambar 
pyinnovativetrend.ita_single_vis (x, panjang, figsize = (10,10), grafik = {})
Fungsi ini menggambarkan grafik dan menyimpan pada mesin lokal.
Contoh:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single_vis(x, 12, graph = graph)
Keluaran:
pyinnovativetrend.ita_multiple_vis_by_station (panjang, grafik = {}, filename = [], kolom = [], kecualicolumn = [], csv = false, directory_path = "./")
Fungsi ini menggambarkan beberapa grafik yang diurutkan berdasarkan stasiun dan menghemat pada mesin lokal pada direktori atau direktori root yang diinginkan. Data diambil dari file Excel atau CSV dari direktori yang diinginkan atau root dan hasilnya disimpan sebagai format Excel diurutkan berdasarkan stasiun pada direktori yang diinginkan atau root. Contoh:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
Keluaran:
pyinnovativetrend.ita_multiple_vis_by_column (panjang, grafik = {}, filename = [], kolom = [], kecualiColumn = [], csv = false, directory_path = "./")
Fungsi ini menggambarkan beberapa grafik yang diurutkan berdasarkan stasiun dan menghemat pada mesin lokal pada direktori atau direktori root yang diinginkan. Data diambil dari file Excel atau CSV dari direktori yang diinginkan atau root dan hasilnya disimpan sebagai format Excel diurutkan berdasarkan kolom pada direktori yang diinginkan atau root. Contoh:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
Keluaran:
X: Daftar atau Array Numpy
Seri waktu atau seri data yang trennya harus ditentukan
Panjang: Integer
Panjang seri waktu. Jika diberikan panjang deret waktu itu aneh, entri paling awal/pertama akan dikomit.
Nama file: Daftar default semua file Excel/CSV
Daftar file atau stasiun yang berisi data diurutkan berdasarkan bulan/tahun/musim.
Kolom: Daftar Default Semua Kolom
Daftar kolom atau seri data yang berisi data.
kecuali Column: Daftar Daftar Kosong Default
Daftar kolom yang analisisnya tidak diperlukan (misalnya, kolom tahun).
CSV: BOOL Default Salah Jenis file. Secara default jenis file adalah Excel. Namun, jika file dalam format CSV, CSV harus ditugaskan ke True.
directory_path: root default string
Jalur direktori file tempat file disimpan.
Output: Daftar nama stasiun default atau nama kolom
Nama file yang dengannya hasilnya akan disimpan.
out_direc: root default string
Jalur direktori file di mana hasilnya akan disimpan.
Alpha: float default 0.05
Tingkat signifikansi dalam tes dua sisi.
Showgraph: bool default true
Pilih jika grafik harus diilustrasikan bersama dengan perhitungan dalam analisis tunggal.
Grafik: Python Dictionary (Opsional) Nilai Default 'TrendLinestyle': 'Deleber' # Line Style of Trend Line, untuk lebih banyak jenis gaya garis kunjungan dokumentasi matplotlib
'Scattermarker': '.' # Marker Jenis titik data yang tersebar, untuk dokumentasi kunjungan marker lebih banyak dari matplotlib
'Judul': '' # judul grafik atau ilustrasi
'Xlabel': 'Sub-Seri Pertama' # Label X-Axis
'Ylabel': 'Sub-Series Kedua' # Label dari Y-Axis
'NotRendLinestyle': 'Solid' # Line Style of No Trend Line atau 1: 1 Line, untuk lebih banyak jenis gaya garis kunjungan dokumentasi matplotlib
'output_dir': './' # direktori file output di mana grafik akan disimpan
'output_name': 'outputfig.png' # Nama grafik atau ilustrasi
'DPI': 300 # dot per inci (DPI) dari grafik atau ilustrasi
'Row': - # Baris nomor subplot. Jika tidak disediakan, akan dihitung secara otomatis. (Tersedia hanya untuk analisis ganda)
'colm': - # nomor kolom subplot. Jika tidak disediakan, akan dihitung secara otomatis. (Hanya tersedia untuk beberapa analisis)
kecenderungan:
Memberitahu apakah tren ada dan jenis tren
H:
Benar (jika tren hadir) dan salah (jika tren tidak ada)
P:
Nilai P untuk tes signifikan (tes 2-tail)
Z:
Statistik uji dinormalisasi (tes 2-tailed)
lereng:
Kemiringan tren
Standard_deviation:
standar deviasi dari seri data
slope_standard_deviation:
Deviasi standar korelasi lereng:
Korelasi antara sub-seri yang diurutkan
lower_critical_level:
Nilai kritis yang lebih rendah untuk tes 2-ekor
Upper_critical_level:
Nilai kritis atas untuk tes 2-ekor


