pyinnovativetrend
1.0.0
การวิเคราะห์แนวโน้มเป็นเทคนิคทางสถิติที่ใช้ในการตรวจสอบข้อมูลเมื่อเวลาผ่านไปเพื่อระบุรูปแบบแนวโน้มหรือการเคลื่อนไหวในทิศทางเฉพาะ มีการใช้กันอย่างแพร่หลายในสาขาต่าง ๆ เช่นการเงินเศรษฐศาสตร์การตลาดวิทยาศาสตร์สิ่งแวดล้อมและอื่น ๆ อีกมากมาย วิธีการที่พบบ่อยและธรรมดาในการตรวจจับแนวโน้มคือการทดสอบเทรนด์แมนน์เคนดัลล์ที่เสนอโดยแมนน์และเคนดัลล์ อย่างไรก็ตามวิธีการที่เป็นนวัตกรรมที่เสนอโดย Sen (2012) ถูกนำมาใช้กันอย่างแพร่หลายในขณะนี้เนื่องจากความเรียบง่ายและคุณสมบัติกราฟิก วิธีการวิเคราะห์แนวโน้มที่เป็นนวัตกรรมนี้มีความละเอียดอ่อนมากและสามารถตรวจจับแนวโน้มที่มองข้ามด้วยวิธีการทั่วไปเช่นการทดสอบ MK
แพ็คเกจถูกติดตั้งโดยใช้ PIP:
pip install pyinnovativetrend
pyinnovativetrend.ita_single (x, ความยาว, alpha = 0.05, graph = {}, showgraph = true)
ฟังก์ชั่นนี้คำนวณแนวโน้มและพารามิเตอร์ที่จำเป็นอื่น ๆ สำหรับรายการเดียวหรืออาร์เรย์ NumPy และส่งคืน tuple ที่มีชื่อ โดยค่าเริ่มต้นกราฟจะแสดงและบันทึกบนเครื่องท้องถิ่น
ตัวอย่าง:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
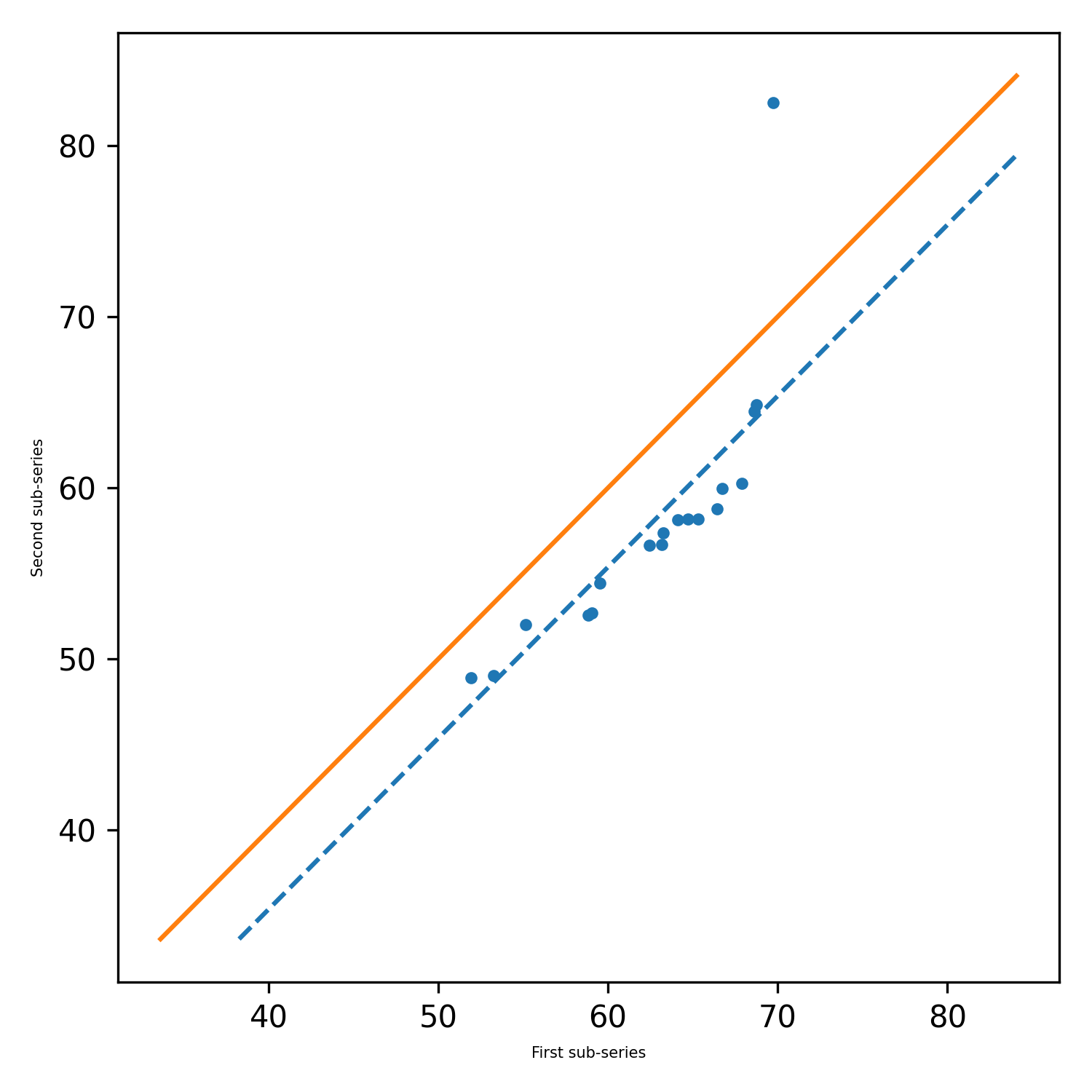
pit.ITA_single(x, 12, graph = graph)
เอาท์พุท: ITA (แนวโน้ม = 'ไม่มีแนวโน้ม', H = FALSE, P = 0.2049477839420626, Z = -1.2675805428826508, Slope = -0.027777777777777752, Standard_Deviation slope_standard_deviation = 0.021914014011770254, สหสัมพันธ์ = 0.9341987329938274, lower_critical_level = -0.0429506782197758
ita_multiple_by_station (ความยาว, filename = [], คอลัมน์ = [], ยกเว้นคอลัมน์ = [], กราฟ = {}, alpha = 0.05, rnd = 2, csv = false, directory_path = "./", output = [], out_direc = "./")
ฟังก์ชั่นนี้คำนวณแนวโน้มและพารามิเตอร์ที่จำเป็นอื่น ๆ สำหรับหลายสถานี ข้อมูลถูกดึงมาจากไฟล์ Excel หรือ CSV จากไดเรกทอรีที่ต้องการหรือรูทไดเรกทอรีและผลลัพธ์จะถูกบันทึกเป็นรูปแบบ Excel ที่เรียงลำดับตามสถานีบนไดเรกทอรีที่ต้องการหรือรูทไดเรกทอรี โดยค่าเริ่มต้นกราฟหลายรายการที่เรียงลำดับโดยสถานีจะถูกแสดงและบันทึกไว้ในเครื่องท้องถิ่นบนไดเรกทอรีที่ต้องการหรือไดเรกทอรีราก
ตัวอย่าง:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_station(38, exceptcolumn=['Year'], graph = graph)
เอาท์พุท:
ตัวอย่างไฟล์ Excel 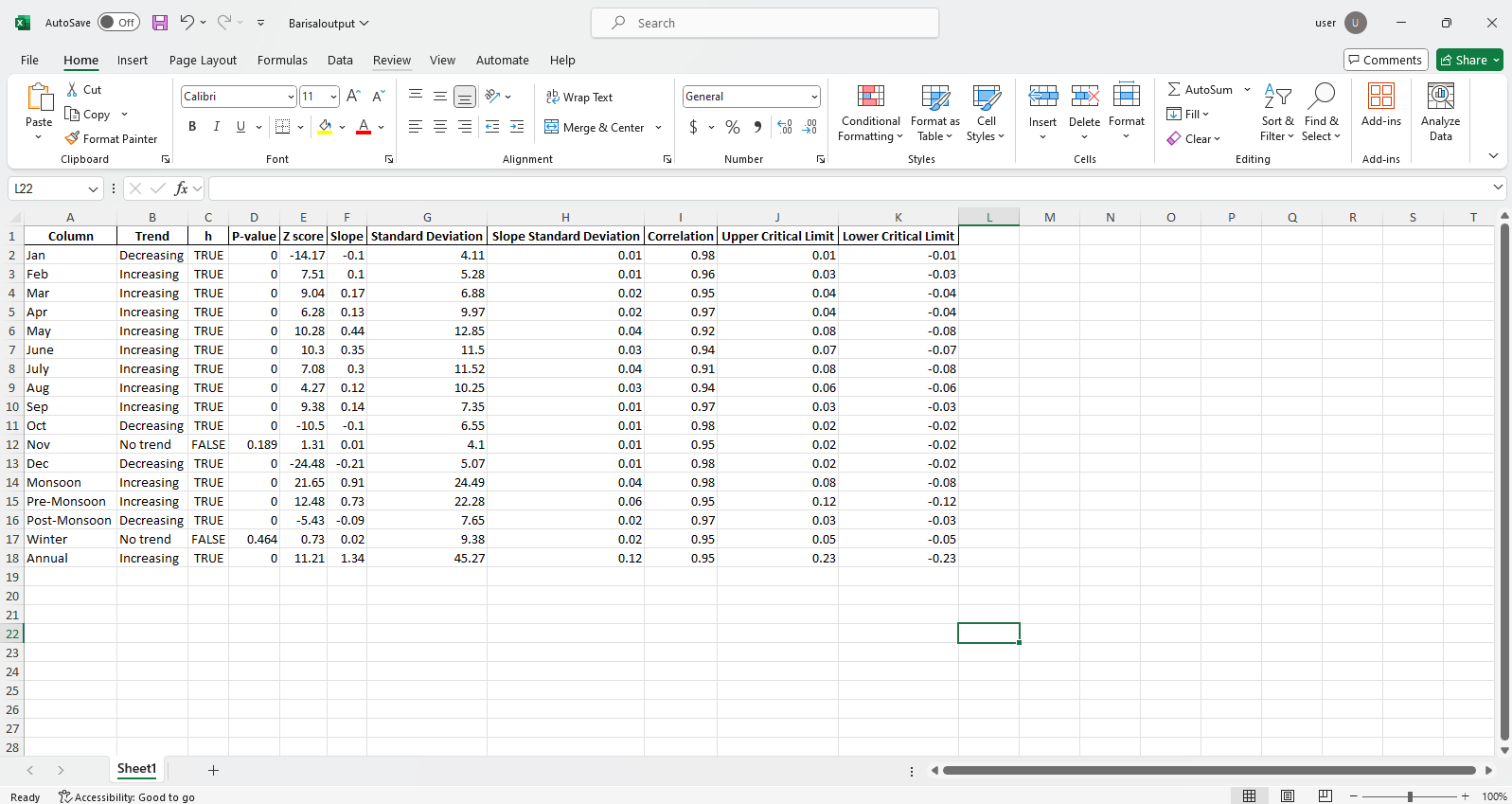 ตัวอย่างรูป
ตัวอย่างรูป 
pyinnovativetrend.ita_multiple_by_station (ความยาว, filename = [], คอลัมน์ = [], ยกเว้นคอลัมน์ = [], กราฟ = {}, alpha = 0.05, rnd = 2, csv = false, directory_path = "./", output = []
ฟังก์ชั่นนี้คำนวณแนวโน้มและพารามิเตอร์ที่จำเป็นอื่น ๆ สำหรับหลายสถานี ข้อมูลถูกดึงมาจากไฟล์ Excel หรือ CSV จากไดเรกทอรีที่ต้องการหรือรูทไดเรกทอรีและผลลัพธ์จะถูกบันทึกเป็นรูปแบบ Excel ที่เรียงลำดับตามคอลัมน์บนไดเรกทอรีที่ต้องการหรือรูทไดเรกทอรี โดยค่าเริ่มต้นกราฟหลายตัวเรียงลำดับตามคอลัมน์จะแสดงและบันทึกไว้ในเครื่องท้องถิ่นบนไดเรกทอรีที่ต้องการหรือไดเรกทอรีราก
ตัวอย่าง:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_column(38, exceptcolumn=['Year'], graph = graph)
เอาท์พุท:
ตัวอย่างไฟล์ Excel 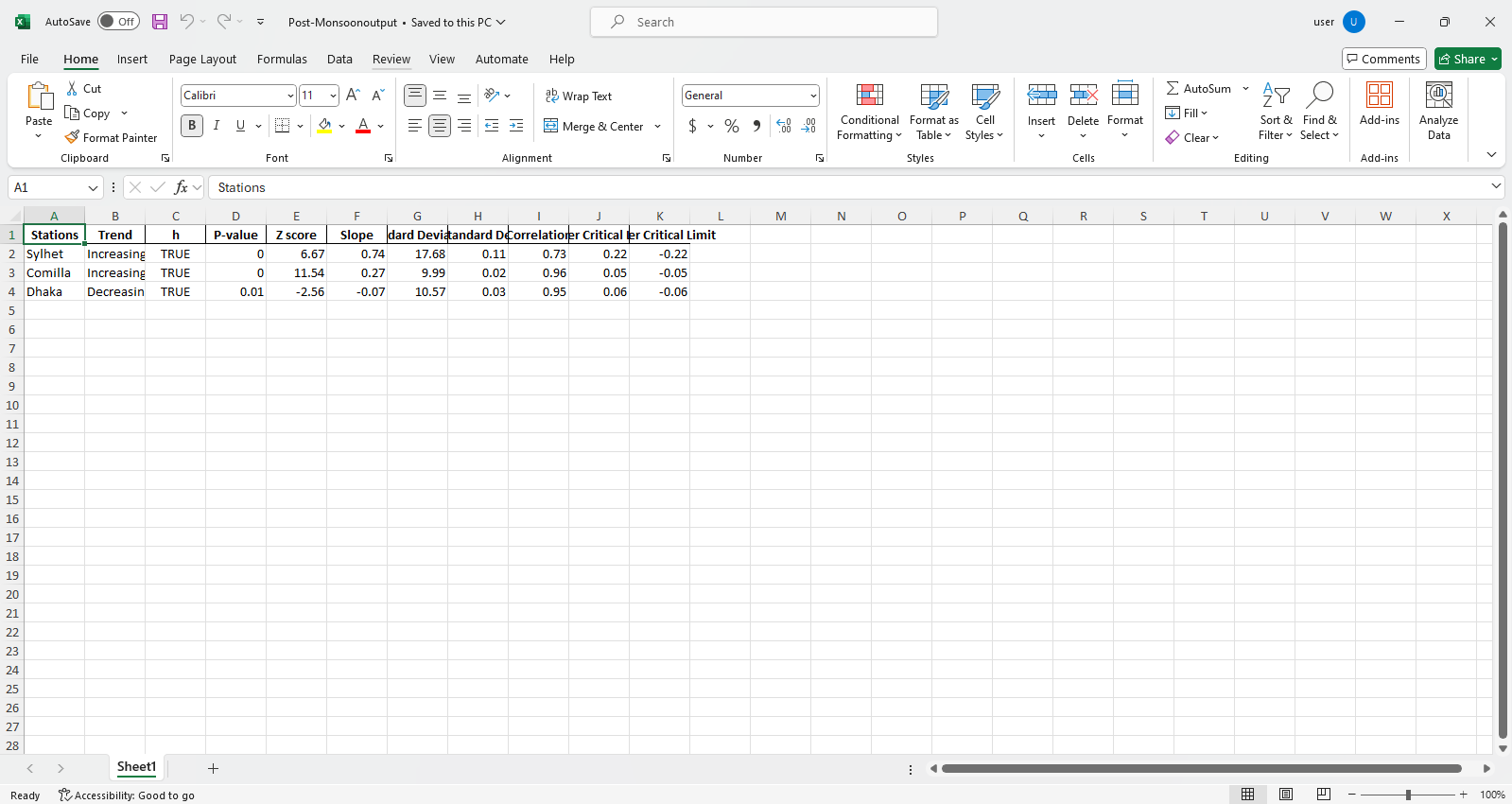 ตัวอย่างรูป
ตัวอย่างรูป 
pyinnovativetrend.ita_single_vis (x, ความยาว, figsize = (10,10), กราฟ = {})
ฟังก์ชั่นนี้แสดงกราฟและบันทึกบนเครื่องท้องถิ่น
ตัวอย่าง:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single_vis(x, 12, graph = graph)
เอาท์พุท:
pyinnovativetrend.ita_multiple_vis_by_station (ความยาว, กราฟ = {}, filename = [], คอลัมน์ = [], ยกเว้น column = [], csv = false, directory_path = "./")
ฟังก์ชั่นนี้แสดงกราฟหลายรายการที่เรียงลำดับโดยสถานีและบันทึกบนเครื่องท้องถิ่นบนไดเรกทอรีที่ต้องการหรือไดเรกทอรีราก ข้อมูลถูกดึงมาจากไฟล์ Excel หรือ CSV จากไดเรกทอรีที่ต้องการหรือรูทไดเรกทอรีและผลลัพธ์จะถูกบันทึกเป็นรูปแบบ Excel ที่เรียงลำดับตามสถานีบนไดเรกทอรีที่ต้องการหรือรูทไดเรกทอรี ตัวอย่าง:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
เอาท์พุท:
pyinnovativetrend.ita_multiple_vis_by_column (ความยาว, กราฟ = {}, filename = [], คอลัมน์ = [], ยกเว้น column = [], csv = false, directory_path = "./")
ฟังก์ชั่นนี้แสดงกราฟหลายรายการที่เรียงลำดับโดยสถานีและบันทึกบนเครื่องท้องถิ่นบนไดเรกทอรีที่ต้องการหรือไดเรกทอรีราก ข้อมูลถูกดึงมาจากไฟล์ Excel หรือ CSV จากไดเรกทอรีที่ต้องการหรือรูทไดเรกทอรีและผลลัพธ์จะถูกบันทึกเป็นรูปแบบ Excel ที่เรียงลำดับตามคอลัมน์บนไดเรกทอรีที่ต้องการหรือรูทไดเรกทอรี ตัวอย่าง:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
เอาท์พุท:
x: รายการหรืออาร์เรย์ numpy
อนุกรมเวลาหรือชุดข้อมูลที่มีแนวโน้มจะถูกกำหนด
ความยาว: จำนวนเต็ม
ความยาวของอนุกรมเวลา หากความยาวของอนุกรมเวลานั้นแปลกรายการแรกสุด/ครั้งแรกจะถูก ommitted
ชื่อไฟล์: รายการค่าเริ่มต้นไฟล์ Excel/CSV ทั้งหมด
รายการไฟล์หรือสถานีที่มีข้อมูลเรียงลำดับตามเดือน/ปี/ฤดูกาล
คอลัมน์: รายการเริ่มต้นคอลัมน์ทั้งหมด
รายการคอลัมน์หรือชุดข้อมูลที่มีข้อมูล
ยกเว้นคอลัมน์: รายการรายชื่อว่างเปล่าเริ่มต้น
รายการคอลัมน์ที่ไม่จำเป็นต้องมีการวิเคราะห์ (ตัวอย่างเช่นคอลัมน์ของปี)
CSV: BOOL Default FALSE ประเภทของไฟล์ โดยค่าเริ่มต้นประเภทไฟล์คือ Excel อย่างไรก็ตามหากไฟล์อยู่ในรูปแบบ CSV ควรกำหนด CSV ให้เป็นจริง
directory_path: สตริงเริ่มต้นรูท
เส้นทางไดเรกทอรีของไฟล์ที่เก็บไฟล์ไว้
เอาต์พุต: รายการชื่อสถานีเริ่มต้นหรือชื่อคอลัมน์
ชื่อของไฟล์ที่จะบันทึกผลลัพธ์
out_direc: สตริงเริ่มต้นรูท
เส้นทางไดเรกทอรีของไฟล์ที่จะบันทึกผลลัพธ์
อัลฟ่า: ลอยเริ่มต้น 0.05
ระดับความสำคัญในการทดสอบสองด้าน
showgraph: bool เริ่มต้นจริง
เลือกว่ากราฟจะแสดงพร้อมกับการคำนวณในการวิเคราะห์เดียว
กราฟ: พจนานุกรม Python (เป็นทางเลือก) ค่าเริ่มต้น 'Trendlinestyle': 'Dashed' # รูปแบบบรรทัดของเส้นแนวโน้มสำหรับประเภทบรรทัดเพิ่มเติมการเยี่ยมชมเอกสารของ Matplotlib
'scattermarker': '.' # marker ประเภทของจุดข้อมูลที่กระจัดกระจายสำหรับเอกสารเพิ่มเติมเยี่ยมชมเอกสารของ matplotlib
'ชื่อ': '' # ชื่อเรื่องของกราฟหรือภาพประกอบ
'xlabel': 'ซีรีส์ย่อยแรก' # ฉลากของแกน x
'ylabel': 'ชุดย่อยที่สอง' # ฉลากของแกน y
'NotrendlineStyle': 'Solid' # Line Style of No Trend Line หรือ 1: 1 บรรทัดสำหรับประเภทบรรทัดเพิ่มเติมการเยี่ยมชมเอกสารของ Matplotlib
'output_dir': './' # ไดเรกทอรีของไฟล์เอาต์พุตที่จะบันทึกกราฟ
'output_name': 'outputfig.png' # ชื่อของกราฟหรือภาพประกอบ
'dpi': 300 # dot ต่อนิ้ว (dpi) ของกราฟหรือภาพประกอบ
'แถว': - # หมายเลขแถวของแผนการย่อย หากไม่ได้ให้ไว้จะถูกคำนวณโดยอัตโนมัติ (มีให้สำหรับการวิเคราะห์หลายครั้งเท่านั้น)
'Colm': - # หมายเลขคอลัมน์ของแผนการย่อย หากไม่ได้ให้ไว้จะถูกคำนวณโดยอัตโนมัติ (มีเฉพาะสำหรับการวิเคราะห์หลายครั้ง)
แนวโน้ม:
บอกว่ามีแนวโน้มและประเภทของแนวโน้มหรือไม่
ชม:
จริง (ถ้ามีแนวโน้มมีอยู่) และเท็จ (ถ้ามีแนวโน้มขาด)
P:
p-value สำหรับการทดสอบที่สำคัญ (การทดสอบ 2 ด้าน)
Z:
สถิติการทดสอบปกติ (การทดสอบ 2 ด้าน)
ความลาดชัน:
ความลาดชันของแนวโน้ม
Standard_deviation:
ค่าเบี่ยงเบนมาตรฐานของชุดข้อมูล
slope_standard_deviation:
ค่าเบี่ยงเบนมาตรฐานของ ความสัมพันธ์ความลาดชัน:
ความสัมพันธ์ระหว่างซีรีส์ย่อยที่จัดเรียง
lower_critical_level:
ค่าวิกฤตลดลงสำหรับการทดสอบ 2 ด้าน
Upper_critical_level:
ค่าวิกฤตด้านบนสำหรับการทดสอบแบบ 2 ด้าน


