pyinnovativetrend
1.0.0
L'analyse des tendances est une technique statistique utilisée pour examiner les données au fil du temps pour identifier les modèles, les tendances ou les mouvements dans une direction particulière. Il est largement utilisé dans divers domaines tels que la finance, l'économie, le marketing, les sciences de l'environnement et bien d'autres. Une méthode très courante et conventionnelle pour détecter la tendance est le test de tendance de Mann-Kendall proposé par Mann et Kendall. Cependant, une méthode innovante, proposée par Sen (2012), est largement utilisée de nos jours en raison de sa simplicité et de ses caractéristiques graphiques. Cette méthode d'innovation d'analyse des tendances est très sensible et peut détecter les tendances qui sont négligées par des méthodes conventionnelles comme le test MK.
Le package est installé à l'aide de PIP:
pip install pyinnovativetrend
pyinnovativeTrend.ita_single (x, longueur, alpha = 0,05, graph = {}, showgraph = true)
Cette fonction calcule la tendance et les autres paramètres nécessaires pour la liste unique ou le tableau Numpy et renvoie un tuple nommé. Par défaut, un graphique est illustré et enregistré sur la machine locale.
Exemple:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
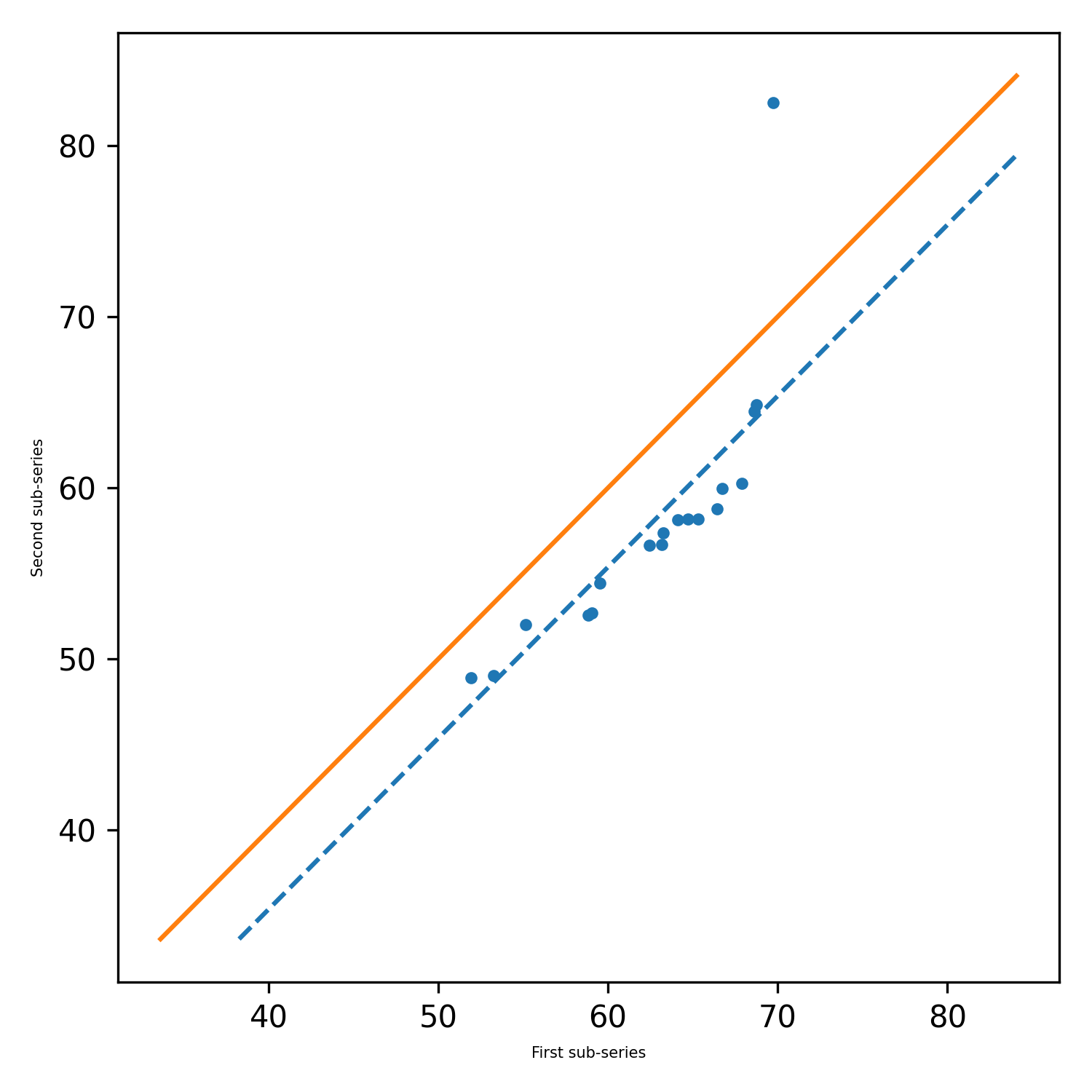
pit.ITA_single(x, 12, graph = graph)
Sortie: ITA (Trend = 'No Trend', H = False, P = 0,2049477839420626, Z = -1.2675805428826508, Slope = -0.0277777777777752, Standard_Devation = 1,2555432644432805, Standard_Devation = 1,2555432644432805, STANDG_DEVIATION = 1,2555432644432805 slope_standard_deviation = 0,021914014011770254, corrélation = 0,9341987329938274, bower_critical_level = -0.0429506782197758, uper_critical_level = 0,0429506782197758)
ITA_MULTIPLE_BY_STATION (LONGUEUR, FILENAME = [], Column = [], saufColumn = [], Graph = {}, alpha = 0.05, rnd = 2, csv = false, Directory_Path = "./", output = [], out_direc = "./")
Cette fonction calcule la tendance et d'autres paramètres nécessaires pour plusieurs stations. Les données sont récupérées à partir des fichiers Excel ou CSV à partir d'un répertoire souhaité ou racine et les résultats sont enregistrés sous forme de format Excel trié par des stations sur le répertoire souhaité ou racine. Par défaut, plusieurs graphiques triés par les stations sont illustrés et enregistrés sur la machine locale sur le répertoire souhaité ou le répertoire racine.
Exemple:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_station(38, exceptcolumn=['Year'], graph = graph)
Sortir:
Exemple de fichiers Excel 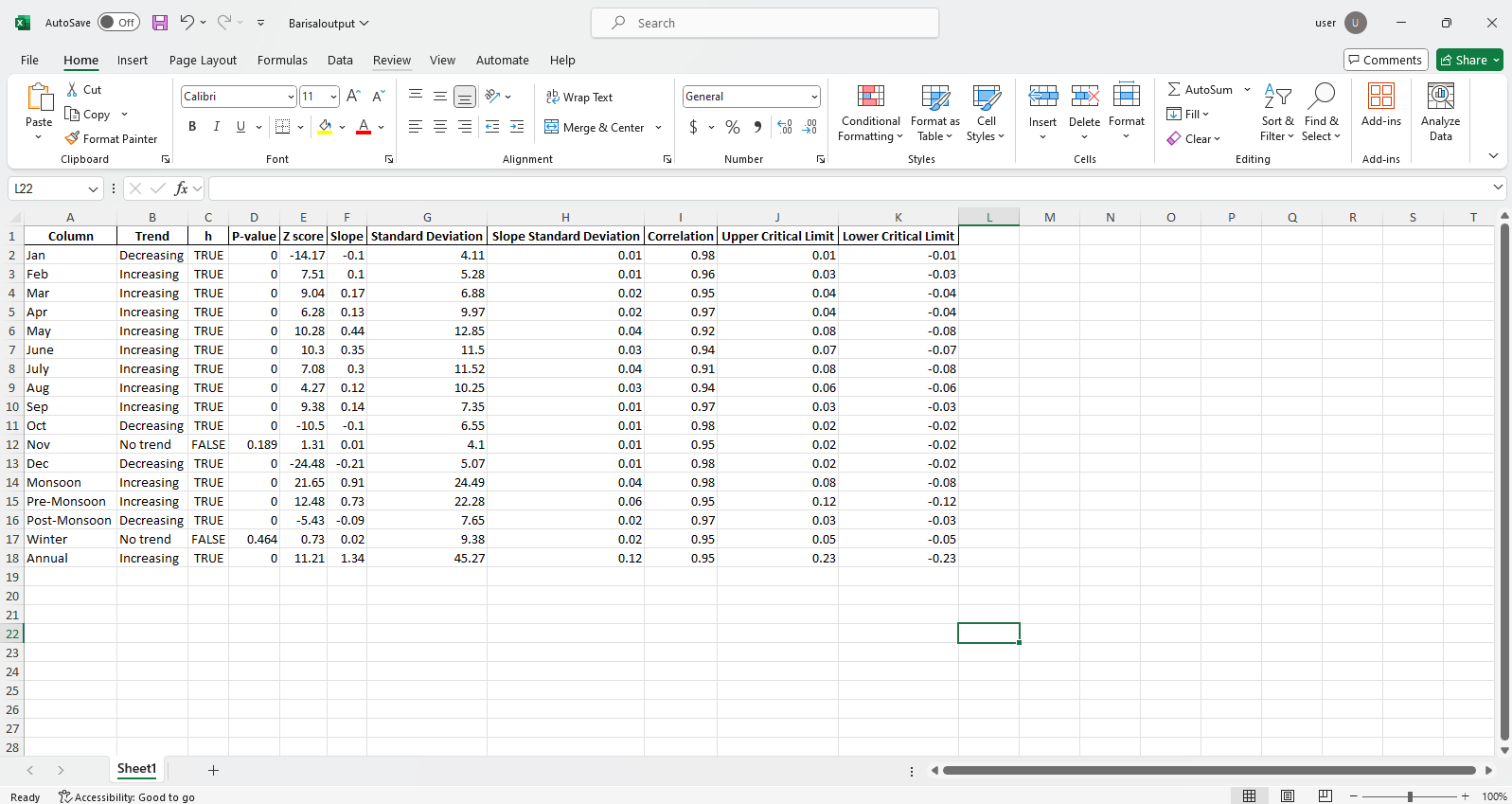 Échantillon
Échantillon 
pyinnovativeTrend.ita_multiple_by_station (longueur, filename = [], colonnel = [], saufColumn = [], graph = {}, alpha = 0.05, rnd = 2, csv = false, répertoire_path = "./", output = [], out_direc = "./")
Cette fonction calcule la tendance et d'autres paramètres nécessaires pour plusieurs stations. Les données sont récupérées à partir des fichiers Excel ou CSV à partir d'un répertoire souhaité ou racine et les résultats sont enregistrés sous forme de format Excel trié par des colonnes sur le répertoire souhaité ou racine. Par défaut, plusieurs graphiques triés par colonnes sont illustrés et enregistrés sur la machine locale sur le répertoire ou le répertoire racine souhaité.
Exemple:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_column(38, exceptcolumn=['Year'], graph = graph)
Sortir:
Exemple de fichiers Excel 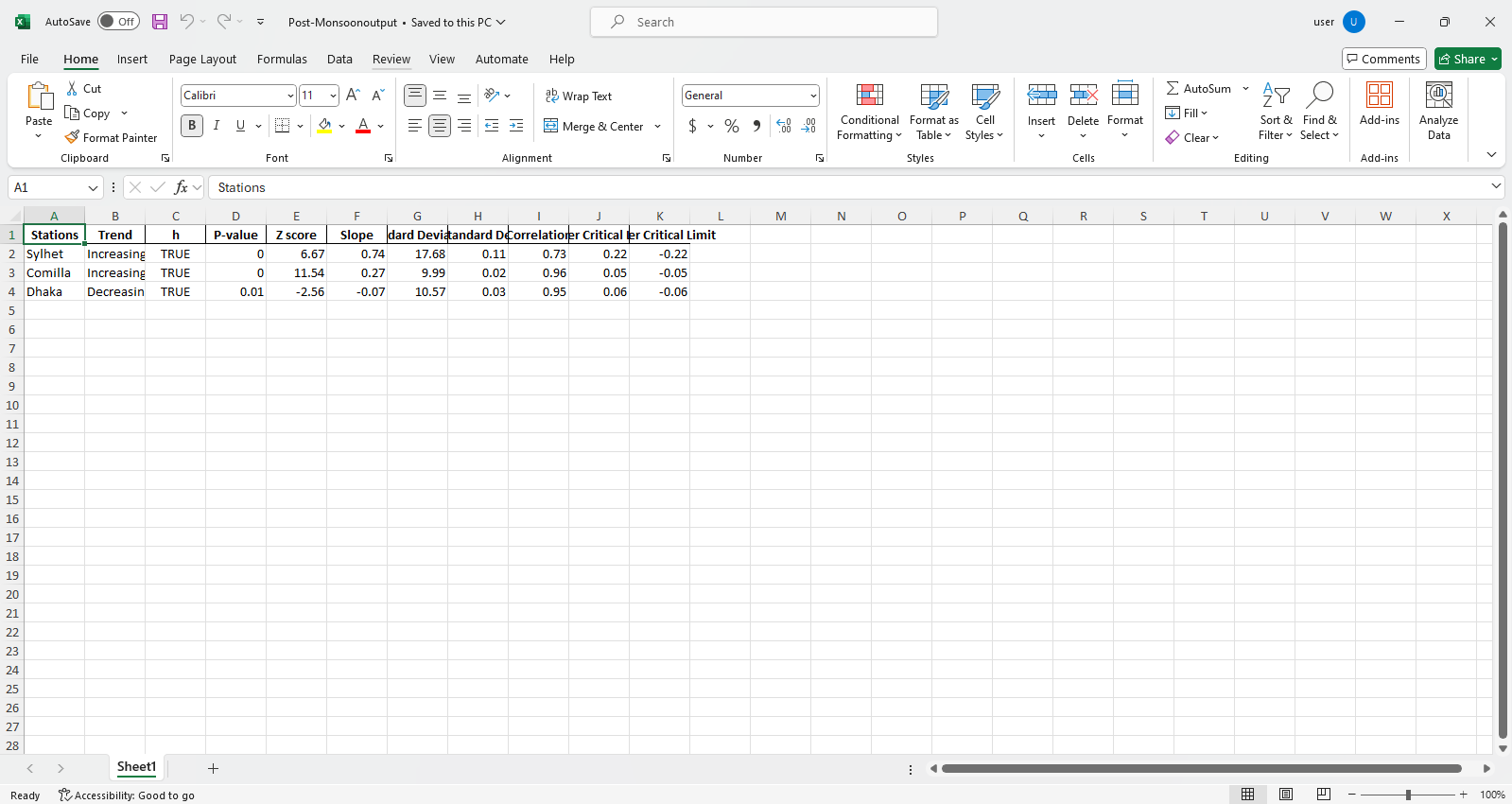 Échantillon
Échantillon 
pyinnovativeTrend.ita_single_vis (x, longueur, figsize = (10,10), graph = {})
Cette fonction illustre un graphique et enregistre sur la machine locale.
Exemple:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single_vis(x, 12, graph = graph)
Sortir:
pyinnovativeTrend.ita_multiple_vis_by_station (longueur, graph = {}, filename = [], colonnes = [], saufColumn = [], csv = false, répertoire_path = "./")
Cette fonction illustre plusieurs graphiques triés par des stations et enregistre sur la machine locale sur le répertoire souhaité ou le répertoire racine. Les données sont récupérées à partir des fichiers Excel ou CSV à partir d'un répertoire souhaité ou racine et les résultats sont enregistrés sous forme de format Excel trié par des stations sur le répertoire souhaité ou racine. Exemple:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
Sortir:
pyinnovativeTrend.ita_multiple_vis_by_column (longueur, graph = {}, filename = [], colonnes = [], saufColumn = [], csv = false, répertoire_path = "./")
Cette fonction illustre plusieurs graphiques triés par des stations et enregistre sur la machine locale sur le répertoire souhaité ou le répertoire racine. Les données sont récupérées à partir des fichiers Excel ou CSV à partir d'un répertoire souhaité ou racine et les résultats sont enregistrés sous forme de format Excel trié par des colonnes sur le répertoire souhaité ou racine. Exemple:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
Sortir:
X: liste de liste ou numpy
La série chronologique ou les séries de données dont la tendance doit être déterminée
Longueur: entier
Longueur de la série chronologique. Si la durée de la série chronologique est donnée, la première / première entrée sera ouverte.
Nom de fichier: répertoriez-vous par défaut tous les fichiers Excel / CSV
Liste des fichiers ou stations contenant les données triées par mois / an / saison.
Colonne: répertoriez par défaut toutes les colonnes
Liste des colonnes ou séries de données qui contiennent les données.
SaufColumn: Liste de la liste vide par défaut
Liste des colonnes pour lesquelles une analyse n'est pas requise (par exemple, la colonne de l'année).
CSV: bool par défaut faux le type de fichiers. Par défaut, le type de fichier est Excel. Cependant, si les fichiers sont au format CSV, CSV doit être affecté à TRUE.
Directory_Path: Root par défaut de chaîne
Chemin de répertoire des fichiers où les fichiers sont stockés.
Sortie: liste des noms de station par défaut ou des noms de colonne
Nom des fichiers par lesquels les résultats seront enregistrés.
Out_Direc: Racine par défaut de chaîne
Chemin de répertoire des fichiers où les résultats seront enregistrés.
alpha: flotteur par défaut 0,05
Niveau de signification dans un test bilatéral.
showgraph: bool par défaut true
Choisissez si le graphique doit être illustré avec le calcul en analyse unique.
Graphique: Python Dictionary (Facultatif) Valeurs par défaut «Trendnenestyle»: «pointillé» # Ligne Style de ligne de tendance, pour plus
«ScatterMarker»: ». # Type de marque de données dispersés, pour plus de marqueur, visitez la documentation de Matplotlib
'Titre': '' # Titre du graphique ou de l'illustration
'XLabel': # First-Series '# Étiquette de l'axe X
`` Ylabel '': «deuxième sous-série» # étiquette de l'axe y
`` Notrendnenestyle '': «solide» # Style de ligne sans ligne de tendance ou ligne 1: 1, pour plus
'output_dir': './' # répertoire du fichier de sortie où le graphique doit être enregistré
'output_name': 'outputfig.png' # Nom du graphique ou de l'illustration
'dpi': 300 # point par pouce (dpi) du graphique ou de l'illustration
'Row': - # Numéro de ligne des sous-intrigues. Si ce n'est pas fourni, sera calculé automatiquement. (Disponible uniquement pour l'analyse multiple)
'Colm': - # Numéro de colonne des sous-intrigues. Si ce n'est pas fourni, sera calculé automatiquement. (Disponible uniquement pour l'analyse multiple)
s'orienter:
Indique si la tendance existe et le type de tendance
H:
Vrai (si la tendance est présente) et fausse (si la tendance est absente)
P:
valeur p pour le test significatif (test à 2 queues)
Z:
Statistiques de test normalisées (test à 2 queues)
pente:
Pente de la tendance
Standard_deviation:
Écart type de la série de données
slope_standard_deviation:
Écart-type de la corrélation de la pente:
Corrélation entre la sous-série triée
inférieur_critical_level:
Valeur critique plus faible pour le test à 2 queues
Upper_Critical_level:
Valeur critique supérieure pour le test à 2 queues


