pyinnovativetrend
1.0.0
A análise de tendências é uma técnica estatística usada para examinar dados ao longo do tempo para identificar padrões, tendências ou movimentos em uma direção específica. É amplamente utilizado em vários campos, como finanças, economia, marketing, ciência ambiental e muitos outros. Um método muito comum e convencional para detectar a tendência é o teste de tendência de Mann-Kendall proposto por Mann e Kendall. No entanto, um método inovador, proposto por Sen (2012), é amplamente utilizado hoje em dia devido à sua simplicidade e recursos gráficos. Esse método inovador de análise de tendências é muito sensível e pode detectar tendências negligenciadas por métodos convencionais como o teste MK.
O pacote é instalado usando PIP:
pip install pyinnovativetrend
pyinnovativerend.ita_single (x, comprimento, alfa = 0,05, gráfico = {}, showgraph = true)
Esta função calcula a tendência e outros parâmetros necessários para lista única ou matriz numpy e retorna uma tupla nomeada. Por padrão, um gráfico é ilustrado e salvo na máquina local.
Exemplo:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
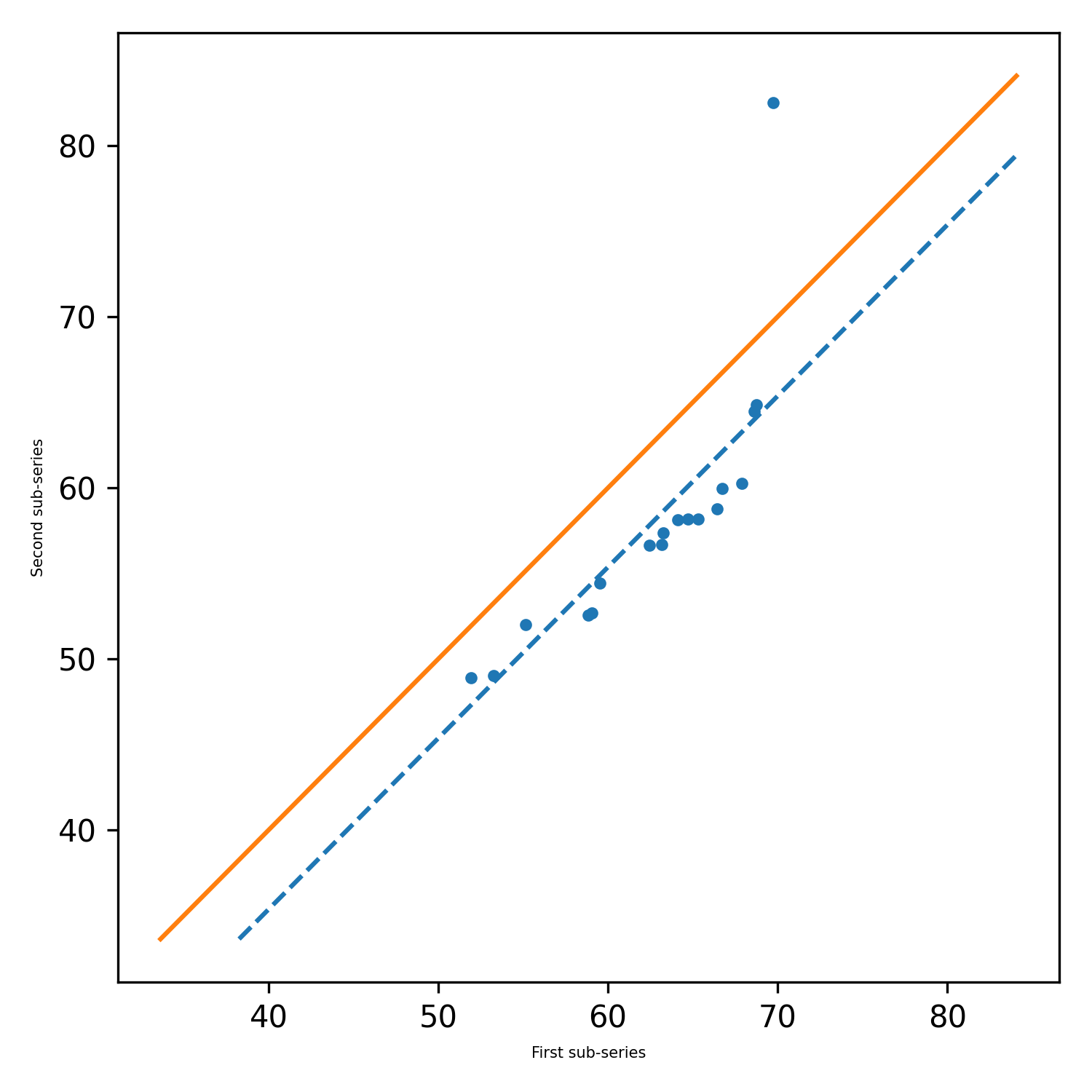
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single(x, 12, graph = graph)
Saída: ITA (Trend = 'sem tendência', h = false, p = 0,2049477839420626, z = -1.2675805428826508, Slope = -0.02777777777777752, Standard_Deviancia slope_standard_deviation=0.021914014011770254, correlation=0.9341987329938274, lower_critical_level=-0.0429506782197758, uper_critical_level=0.0429506782197758)
Ita_multiple_by_station (comprimento, nome do arquivo = [], colun = [], excetoColumn = [], graph = {}, alfa = 0,05, rnd = 2, csv = false, diretório_path = "./", output = [], out_direc = "./")
Esta função calcula a tendência e outros parâmetros necessários para várias estações. Os dados são recuperados dos arquivos Excel ou CSV de um diretório desejado ou raiz e os resultados são salvos como formato Excel classificado por estações no diretório desejado ou root. Por padrão, vários gráficos classificados pelas estações são ilustrados e salvos na máquina local no diretório ou no diretório raiz desejado.
Exemplo:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_station(38, exceptcolumn=['Year'], graph = graph)
Saída:
Amostra de arquivos do Excel 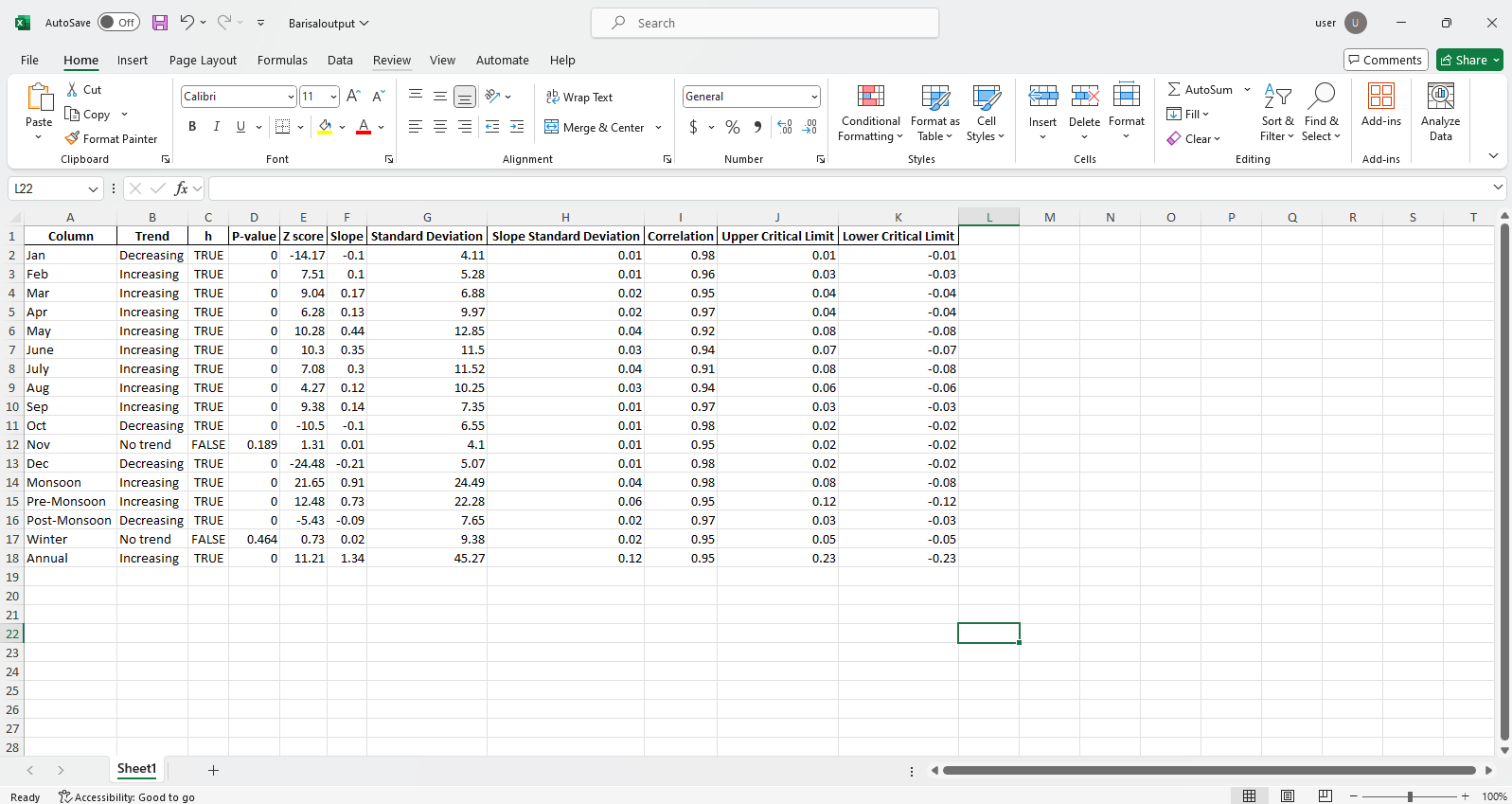 Amostra de figura
Amostra de figura 
pyinnovativerend.ita_multiple_by_station (comprimento, nome do arquivo = [], column = [], excetoColumn = [], gráfico = {}, alfa = 0,05, rnd = 2, csv = false, diretório_path = ".
Esta função calcula a tendência e outros parâmetros necessários para várias estações. Os dados são recuperados dos arquivos Excel ou CSV de um diretório desejado ou raiz e os resultados são salvos como formato Excel classificado por colunas no diretório desejado ou root. Por padrão, vários gráficos classificados por colunas são ilustrados e salvos na máquina local no diretório ou diretório raiz desejado.
Exemplo:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_column(38, exceptcolumn=['Year'], graph = graph)
Saída:
Amostra de arquivos do Excel 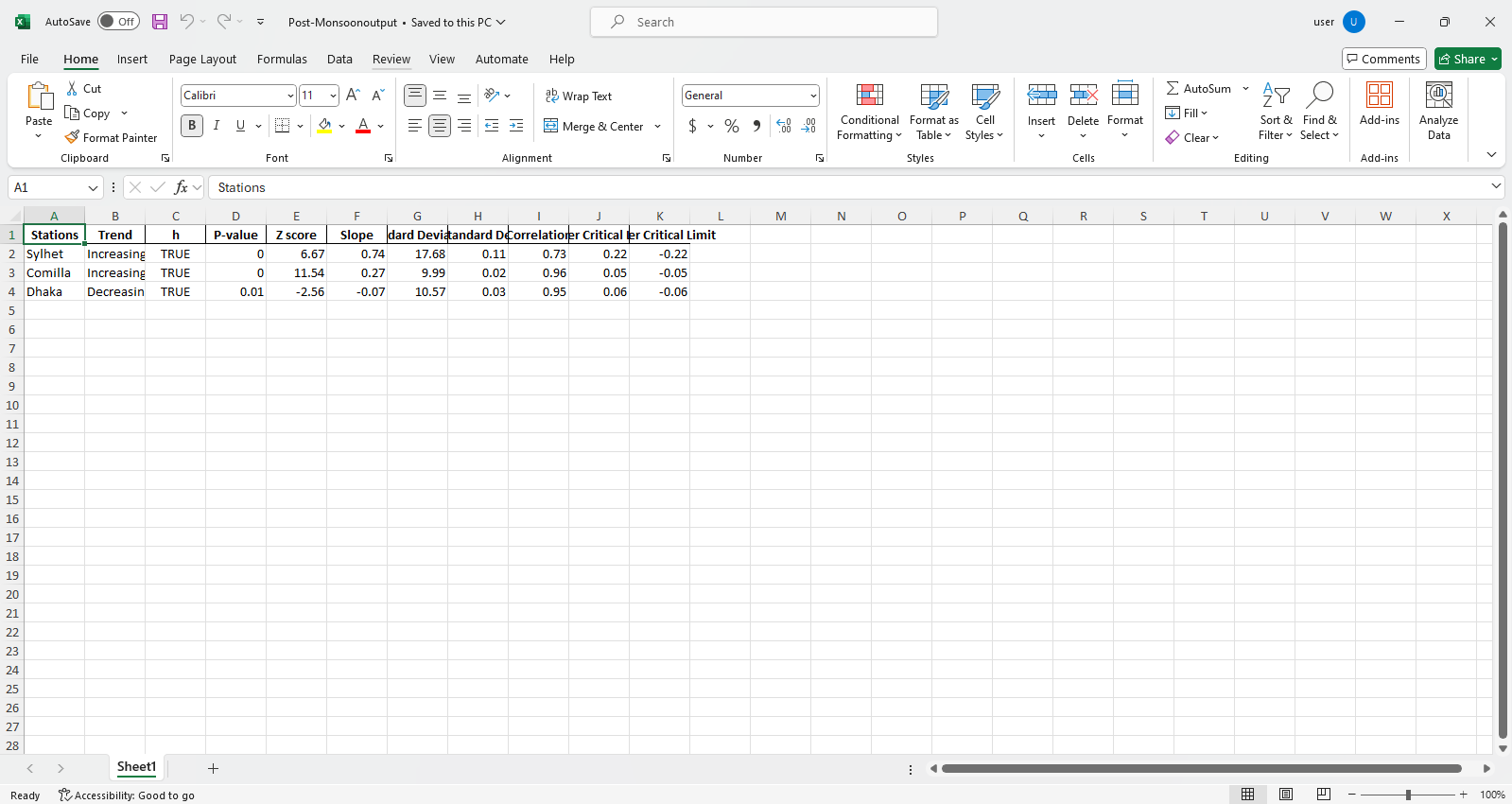 Amostra de figura
Amostra de figura 
pyinnovativerend.ita_single_vis (x, comprimento, figSize = (10,10), gráfico = {})
Esta função ilustra um gráfico e salva na máquina local.
Exemplo:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single_vis(x, 12, graph = graph)
Saída:
pyinnovativerend.ita_multiple_vis_by_station (comprimento, gráfico = {}, filename = [], colun = [], excetoColumn = [], csv = false, diretório_path = "./")
Esta função ilustra vários gráficos classificados por estações e salva na máquina local no diretório desejado ou no diretório raiz. Os dados são recuperados dos arquivos Excel ou CSV de um diretório desejado ou raiz e os resultados são salvos como formato Excel classificado por estações no diretório desejado ou root. Exemplo:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
Saída:
pyinnovativerend.ita_multiple_vis_by_column (comprimento, gráfico = {}, filename = [], colun = [], excetoColumn = [], csv = false, diretório_path = "./")
Esta função ilustra vários gráficos classificados por estações e salva na máquina local no diretório desejado ou no diretório raiz. Os dados são recuperados dos arquivos Excel ou CSV de um diretório desejado ou raiz e os resultados são salvos como formato Excel classificado por colunas no diretório desejado ou root. Exemplo:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
Saída:
X: Lista ou Array Numpy
A série temporal ou série de dados cuja tendência deve ser determinada
Comprimento: Inteiro
Duração da série temporal. Se a duração da série temporal for estranha, a primeira/primeira entrada será omitida.
nome do arquivo: listar padrão todos os arquivos Excel/CSV
Lista de arquivos ou estações que contêm os dados classificados por mês/ano/temporada.
coluna: listar padrão todas as colunas
Lista de colunas ou séries de dados que contêm os dados.
ExceltColumn: List Lista vazia padrão
Lista de colunas para as quais a análise não é necessária (por exemplo, coluna do ano).
CSV: BOOL Padrão Falso O tipo de arquivos. Por padrão, o tipo de arquivo é excel. No entanto, se os arquivos estiverem no formato CSV, o CSV deverá ser atribuído ao TRUE.
diretório_path: string padrão root
Caminho do diretório dos arquivos onde os arquivos são armazenados.
Saída: listar nomes de estação padrão ou nomes de colunas
Nome dos arquivos pelos quais os resultados serão salvos.
out_direc: String padrão root
Caminho do diretório dos arquivos onde os resultados serão salvos.
Alfa: Float Padrão 0,05
Nível de significância em um teste bicaudal.
ShowGraph: BOOL Padrão true
Escolha se o gráfico deve ser ilustrado junto com o cálculo em análise única.
Gráfico: Python Dictionary (Opcional) Valores padrão 'TrendLinestyle': 'Dashed' # estilo de linha de linha, para mais estilo de linha Visite documentação de matplotlib
'Scattermarker': '.' # Tipo de marcador de pontos de dados dispersos, para mais marcador Visite documentação do matplotlib
'Title': '' # título do gráfico ou ilustração
'xlabel': 'Primeira sub-série' # rótulo de eixo x
'ylabel': 'Segunda sub-série' # rótulo de eixo y
'NOTRENDLINESTILYLE': 'Solid' # estilo de linha de nenhuma linha de tendência ou linha 1: 1, para mais tipo de estilo de linha Visite documentação de matplotlib
'Output_dir': './' # Diretório do arquivo de saída onde o gráfico deve ser salvo
'output_name': 'outputfig.png' # nome do gráfico ou ilustração
'dpi': 300 # ponto por polegada (dpi) do gráfico ou ilustração
'Linha': - # Número da linha das subparcelas. Se não for fornecido, será calculado automaticamente. (Disponível apenas para análise múltipla)
'Colm': - # Número da coluna das subparcelas. Se não for fornecido, será calculado automaticamente. (Disponível apenas para análise múltipla)
tendência:
Diz se a tendência existe e o tipo de tendência
H:
Verdadeiro (se a tendência estiver presente) e falsa (se a tendência estiver ausente)
P:
Valor-P para o teste significativo (teste biudal)
z:
Estatística de teste normalizada (teste bicaudal)
declive:
Inclinação da tendência
Standard_Devionce:
Desvio padrão da série de dados
Slope_Standard_Devionce:
Desvio padrão da correlação da inclinação:
Correlação entre as sub-séries classificadas
inferior_critical_level:
Valor crítico mais baixo para teste bicaudal
Upper_critical_level:
Valor crítico superior para teste bicaudal


