pyinnovativetrend
1.0.0
趋势分析是一种统计技术,用于检查数据,以确定特定方向的模式,趋势或运动。它被广泛用于金融,经济学,营销,环境科学等各个领域。检测趋势的一种非常常见的传统方法是Mann-Kendall趋势测试由Mann和Kendall提出。但是,由于其简单性和图形特征,SEN(2012)提出的一种创新方法现在被广泛使用。这种创新的趋势分析方法非常敏感,可以检测到MK测试等常规方法忽略的趋势。
该软件包是使用PIP安装的:
pip install pyinnovativetrend
pyinnovativetrend.ita_single(x,长度,alpha = 0.05,graph = {},showgraph = true)
此功能计算单个列表或numpy数组的趋势和其他必要参数,并返回命名元组。默认情况下,图表将说明并保存在本地计算机上。
例子:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
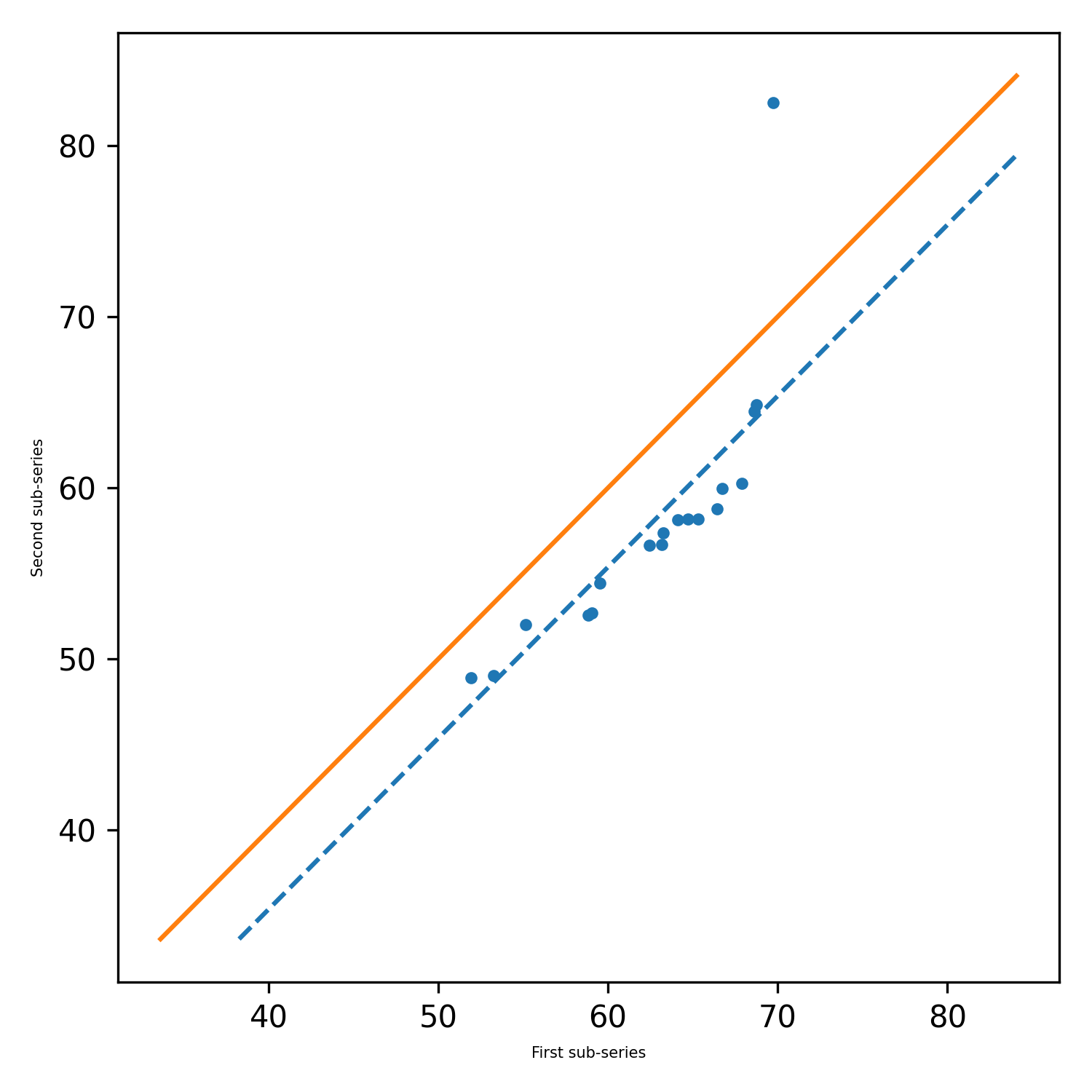
pit.ITA_single(x, 12, graph = graph)
输出:ITA(趋势='no趋势',h = false,p = 0.20494777839420626,z = -1.2675805428826508,SLOPE = -0.027777777777777777777752,standard_deviation = 1.25555555543262626262805, slope_standard_deviation = 0.021914014011770254,相关= 0.9341987329938274,lower_critation_level = -0.04295067821977758
ita_multiple_by_station(长度,fileName = [],column = [],devefcolumn = [],graph = {},alpha = 0.05,rnd = 2,csv = false,directory_path =“ ./” ./“ ./”,output = []
此功能计算多个站点的趋势和其他必要参数。数据是从Excel或CSV文件中从所需或根目录中检索的,结果将保存为Excel格式,由所需或根目录上的电台排序。默认情况下,用电台排序的多个图表被说明并保存在所需目录或根目录的本地计算机上。
例子:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_station(38, exceptcolumn=['Year'], graph = graph)
输出:
Excel文件示例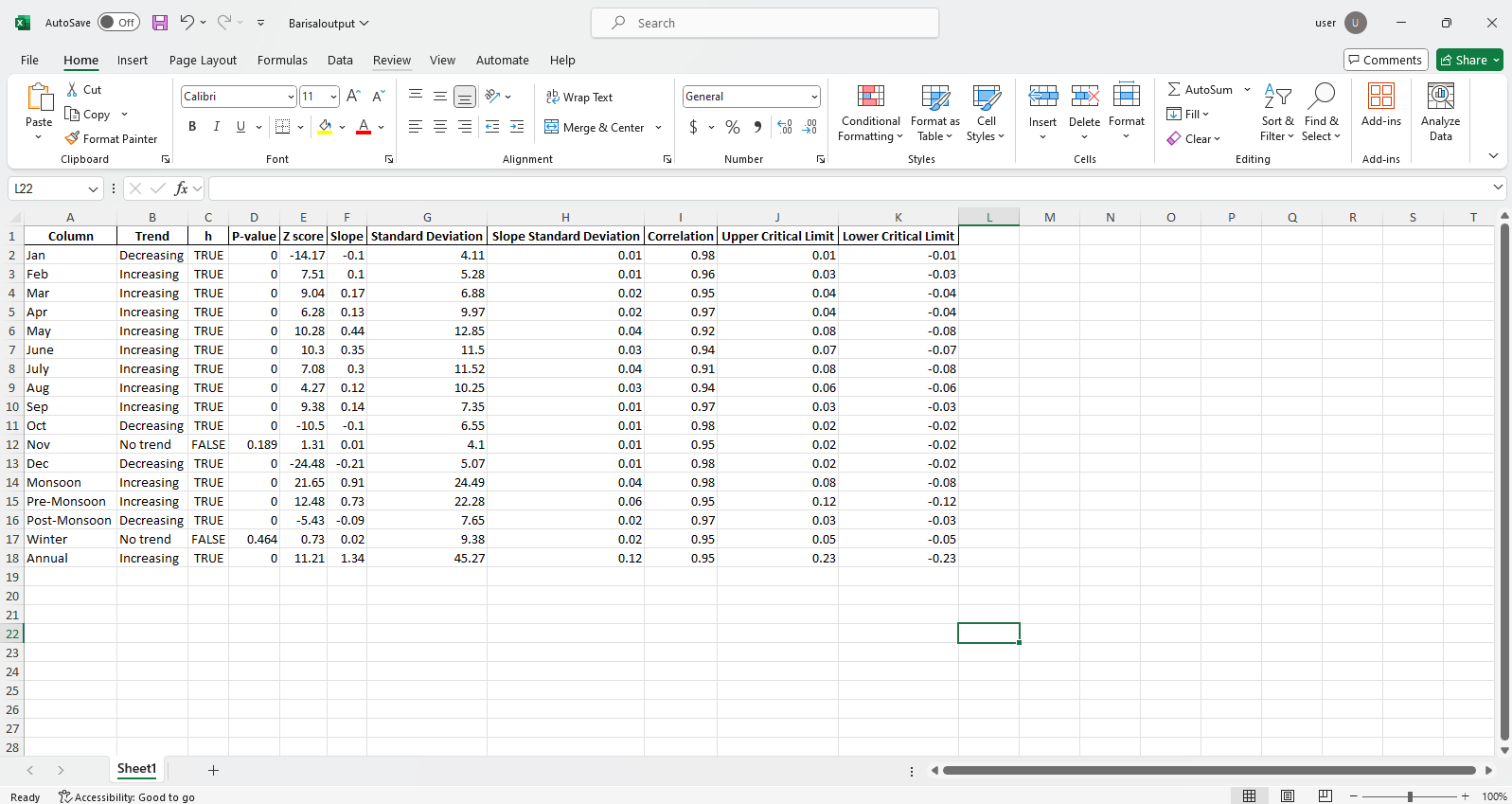 图样本
图样本
pyinnovativetrend.ita_multiple_by_station(长度,fileName = [],column = [],devefcolumn = [],graph = {},alpha = 0.05,rnd = 2,rnd = 2,csv = false,directory_path =“。
此功能计算多个站点的趋势和其他必要参数。数据是从Excel或CSV文件中从所需或根目录中检索的,结果保存为Excel格式,由所需或根目录上的列排序。默认情况下,用列排序的多个图表被说明并保存在所需目录或根目录的本地计算机上。
例子:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_column(38, exceptcolumn=['Year'], graph = graph)
输出:
Excel文件示例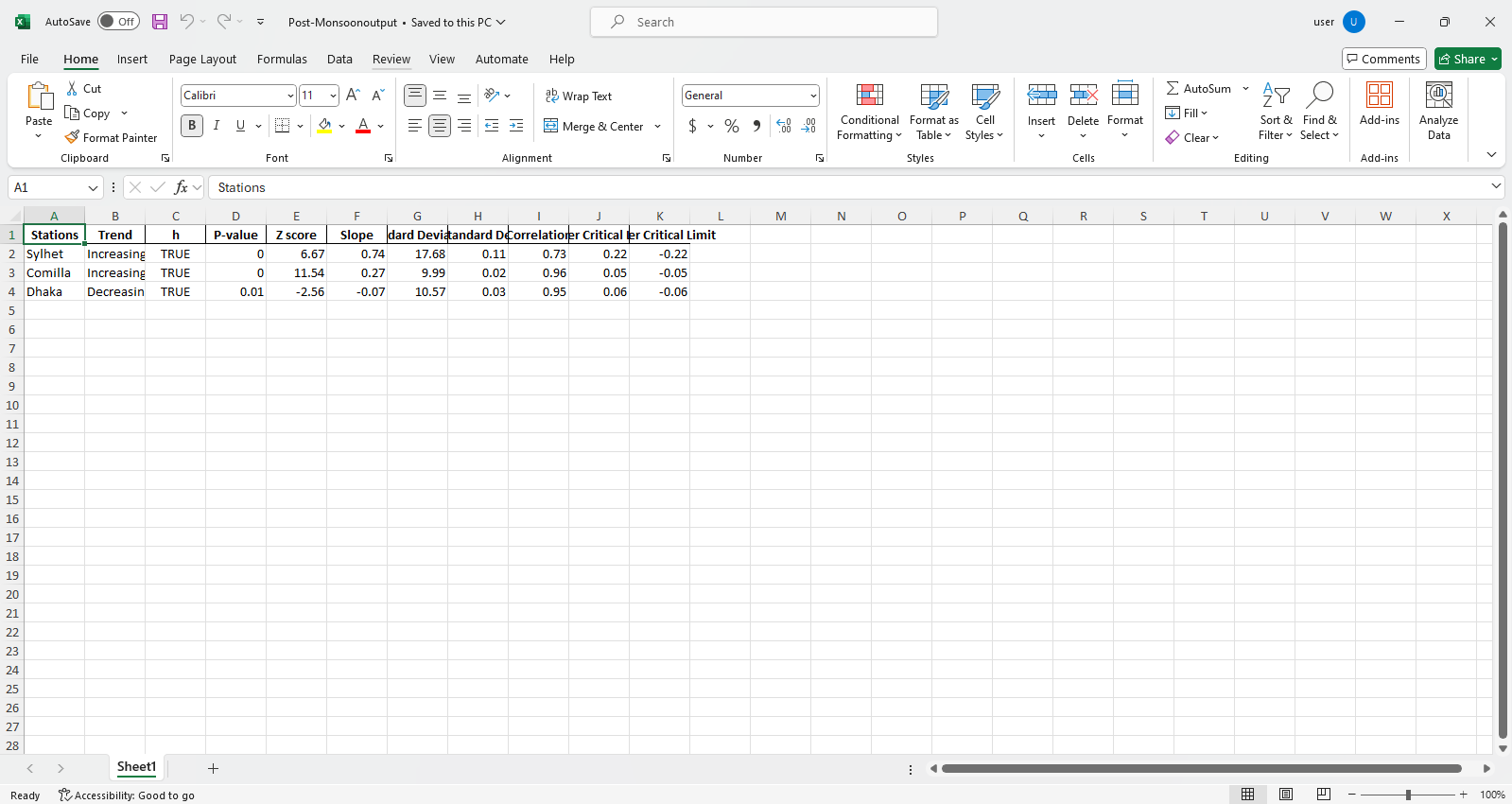 图样本
图样本
pyinnovativetrend.ita_single_vis(x,length,figsize =(10,10),graph = {})
此功能说明了图并保存在本地计算机上。
例子:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single_vis(x, 12, graph = graph)
输出:
pyinnovativetrend.ita_multiple_vis_by_station(长度,gruph = {},filename = [],column = [],decteclumn = [],csv = false,directory_path =“ ./”)
此功能说明了由电台排序的多个图形,并保存在所需目录或根目录上的本地计算机上。数据是从Excel或CSV文件中从所需或根目录中检索的,结果将保存为Excel格式,由所需或根目录上的电台排序。例子:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
输出:
pyinnovativetrend.ita_multiple_vis_by_column(长度,gruph = {},filename = [],column = [],excestcolumn = [],csv = false,directory_path =“ ./” ./”)
此功能说明了由电台排序的多个图形,并保存在所需目录或根目录上的本地计算机上。数据是从Excel或CSV文件中从所需或根目录中检索的,结果保存为Excel格式,由所需或根目录上的列排序。例子:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
输出:
X:列表或numpy数组
时间序列或数据系列的趋势要确定
长度:整数
时间序列的长度。如果给定时间序列的长度很奇怪,则最早/第一个条目将被授予。
文件名:列表默认所有Excel/CSV文件
包含按月/年/季节排序数据的文件或电台列表。
列:列表默认所有列
包含数据的列或数据序列列表。
除外:列表默认空名单
不需要分析的列列表(例如,年度列)。
CSV:BOOL默认错误文件类型。默认情况下,文件类型为Excel。但是,如果文件为CSV格式,则应将CSV分配给TRUE。
Directory_path:字符串默认根
存储文件的文件的目录路径。
输出:列表默认站名称或列名称
将保存结果的文件的名称。
out_direc:字符串默认根
将保存结果的文件的目录路径。
alpha:float默认值0.05
两尾测试的显着性水平。
showgraph:bool默认为true
选择是否要在单个分析中与计算进行说明。
图:Python字典(可选)默认值'Trendlinestyle':“虚线”#趋势线风格,有关Matplotlib的更多线样式访问访问文档
“ Scattermarker”:'。' #标记类型的分散数据点,有关Matplotlib的更多标记访问文档
“标题':'#图形或插图的标题
'xlabel':'第一个子系列'#x轴标签
'ylabel':'第二个子系列'#y轴标签
'notrendlinestyle':“固体”#无趋势线的线样式或1:1行,有关更多行样式类型访问matplotlib的文档
'output_dir':'./'#要保存图形的输出文件目录
'output_name':'outputfig.png'#图形或插图的名称
'dpi':图或插图的300#点每英寸(DPI)
“行”: - #子图的行号。如果不提供,将自动计算。 (仅用于多次分析)
'Colm': - #子图的列号。如果不提供,将自动计算。 (仅用于多次分析)
趋势:
告诉趋势是否存在和趋势类型
H:
真实(如果存在趋势)和错误(如果不存在趋势)
P:
重大测试的P值(2尾测试)
Z:
归一化测试统计(2尾测试)
坡:
趋势
standard_deviation:
数据系列的标准偏差
slope_standard_deviation:
坡度相关的标准偏差:
分类子系列之间的相关性
lower_critical_level:
降低2尾测试的临界价值
upper_critical_level:
2尾测试的高临界价值


