pyinnovativetrend
1.0.0
تحليل الاتجاه هو تقنية إحصائية تستخدم لفحص البيانات مع مرور الوقت لتحديد الأنماط أو الاتجاهات أو الحركات في اتجاه معين. يستخدم على نطاق واسع في مختلف المجالات مثل المالية والاقتصاد والتسويق والعلوم البيئية وغيرها الكثير. الطريقة الشائعة والتقليدية للغاية لاكتشاف الاتجاه هي اختبار اتجاه مان كيندال الذي اقترحه مان وكيندال. ومع ذلك ، يتم استخدام طريقة مبتكرة ، مقترحة SEN (2012) ، على نطاق واسع الآن في أيامها بسبب بساطتها وميزاتها الرسومية. طريقة تحليل الاتجاه المبتكرة هذه حساسة للغاية ويمكنها اكتشاف الاتجاهات التي يتم تجاهلها بالطرق التقليدية مثل اختبار MK.
تم تثبيت الحزمة باستخدام PIP:
pip install pyinnovativetrend
pyinnovativetrend.ita_single (x ، الطول ، ألفا = 0.05 ، الرسم البياني = {} ، showgraph = true)
تقوم هذه الوظيفة بحساب الاتجاه والمعلمات الضرورية الأخرى لقائمة واحدة أو صفيف numpy وتُرجع tuple المسماة. بشكل افتراضي ، يتم توضيح الرسم البياني وحفظه على الجهاز المحلي.
مثال:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
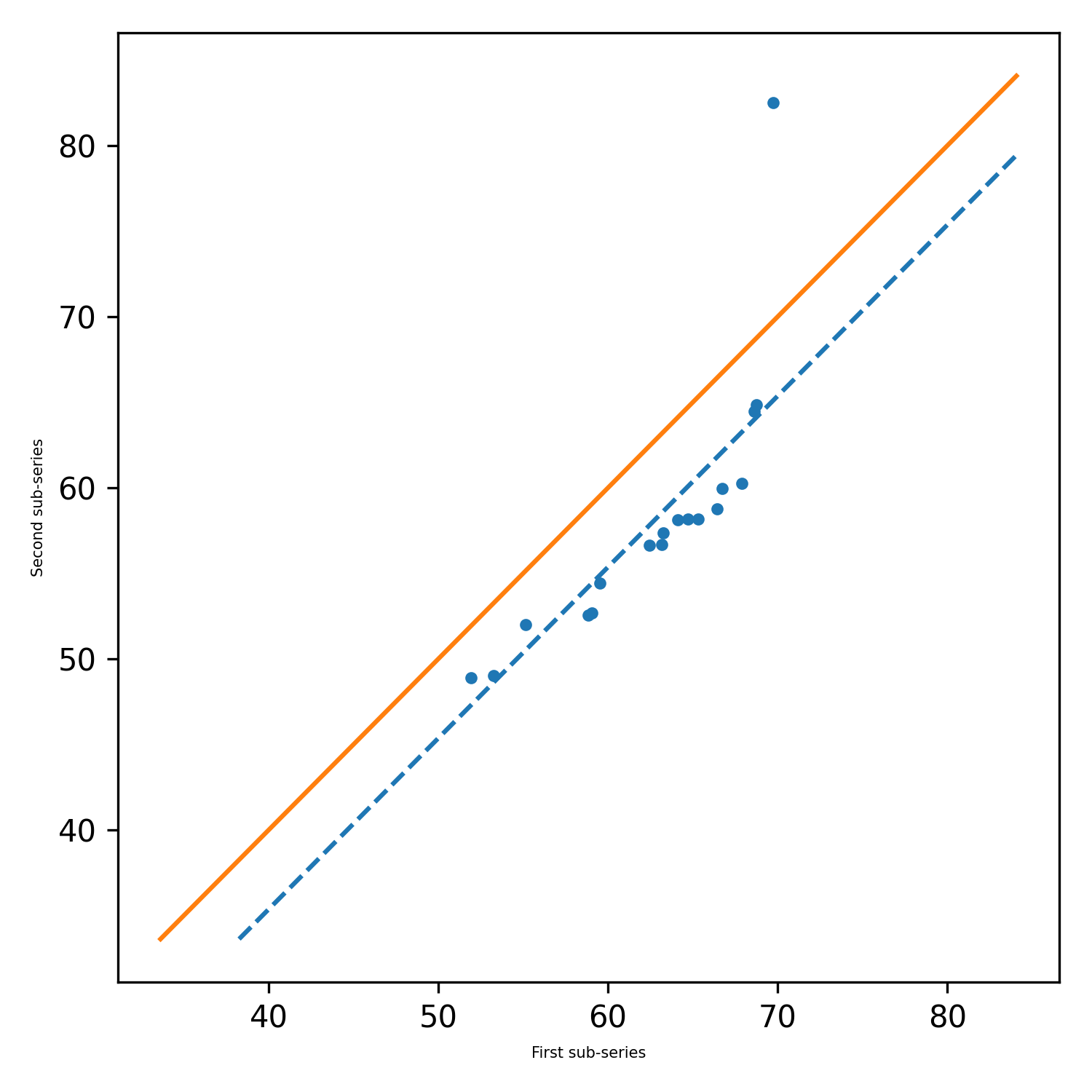
pit.ITA_single(x, 12, graph = graph)
الإخراج: ITA (Trend = 'no trend' ، h = false ، p = 0.2049477839420626 ، z = -1.2675805428826508 ، slope = -0.0277777777777752 ، standard_deviation = 1.2555432644305 ، slope_standard_deviation = 0.021914014011770254 ، الارتباط = 0.9341987329938274 ، lower_critical_level = -0.0429506782197758 ، uper_critic.
ita_multiple_by_station (الطول ، اسم الملف = [] ، العمود = [] ، باستثناء column = [] ، graph = {} ، alpha = 0.05 ، rnd = 2 ، csv = false ، directory_path = "./" ، output = [] ، out_direc = "./")
هذه الوظيفة تحسب الاتجاه والمعلمات الضرورية الأخرى لمحطات متعددة. يتم استرداد البيانات من ملفات Excel أو CSV من دليل مرغوب أو جذر ويتم حفظ النتائج كتنسيق Excel مرتبة بواسطة المحطات على الدليل المطلوب أو الجذر. بشكل افتراضي ، يتم توضيح الرسوم البيانية المتعددة التي تم فرزها بواسطة المحطات وحفظها على الجهاز المحلي على الدليل المطلوب أو الدليل الجذري.
مثال:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_station(38, exceptcolumn=['Year'], graph = graph)
الإخراج:
عينة ملفات Excel 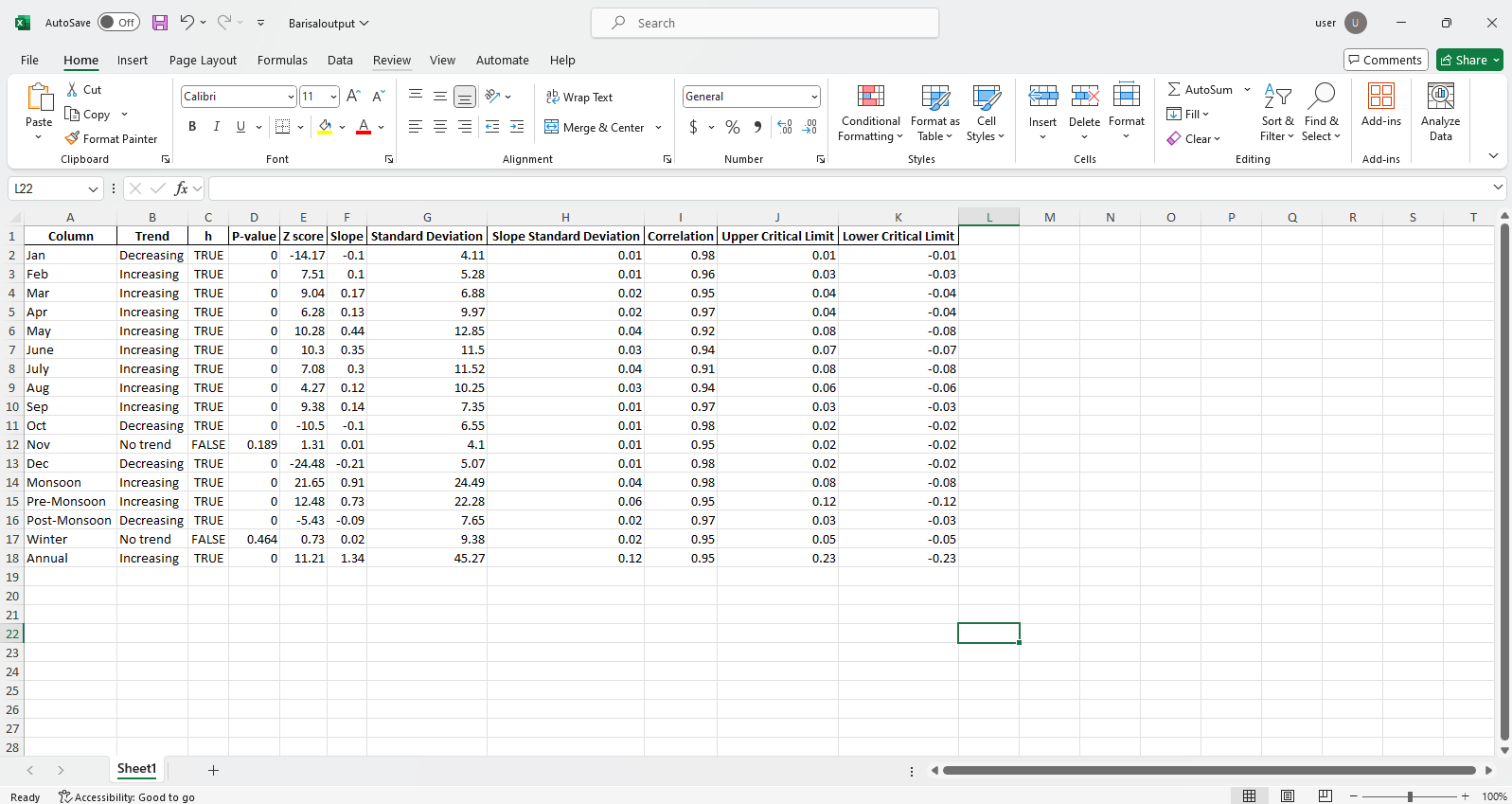 عينة الشكل
عينة الشكل 
pyinnovativetrend.ita_multiple_by_station (الطول ، اسم الملف = [] ، العمود = [] ، باستثناء [[] ، graph = {} ، alpha = 0.05 ، rnd = 2 ، csv = false ، directory_path = ".
هذه الوظيفة تحسب الاتجاه والمعلمات الضرورية الأخرى لمحطات متعددة. يتم استرداد البيانات من ملفات Excel أو CSV من دليل مرغوب أو جذر ويتم حفظ النتائج كتنسيق Excel مرتبة بواسطة الأعمدة على الدليل المطلوب أو الجذر. بشكل افتراضي ، يتم توضيح الرسوم البيانية المتعددة التي يتم فرزها بواسطة الأعمدة وحفظها على الجهاز المحلي على الدليل المطلوب أو الدليل الجذري.
مثال:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_column(38, exceptcolumn=['Year'], graph = graph)
الإخراج:
عينة ملفات Excel 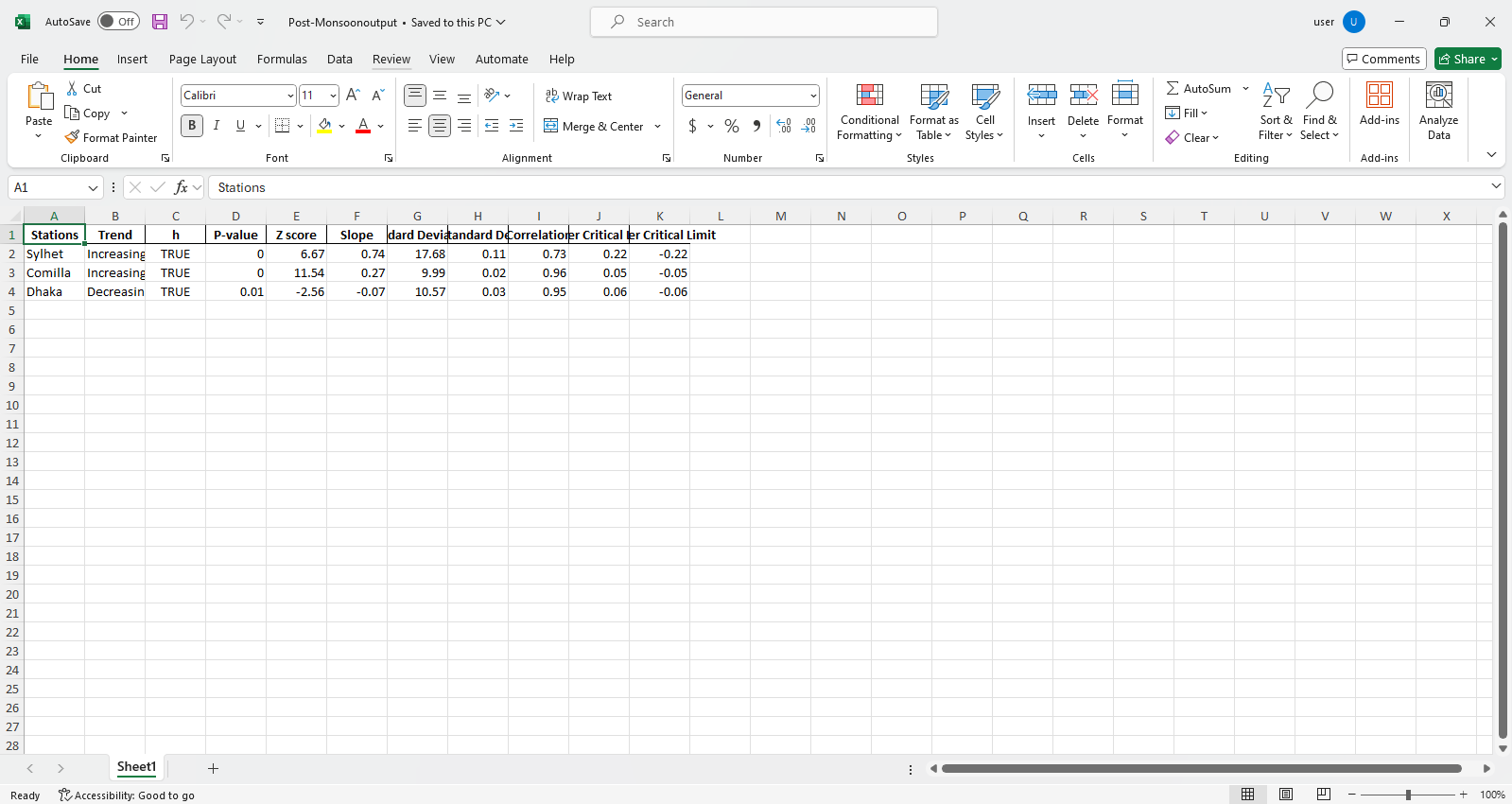 عينة الشكل
عينة الشكل 
pyinnovativetrend.ita_single_vis (x ، الطول ، التين = (10،10) ، الرسم البياني = {})
توضح هذه الوظيفة رسم بياني وتحفظه على الجهاز المحلي.
مثال:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single_vis(x, 12, graph = graph)
الإخراج:
pyinnovativetrend.ita_multiple_vis_by_station (الطول ، الرسم البياني = {} ، filename = [] ، column = [] ، insevencolumn = [] ، csv = false ، directory_path = "./")
توضح هذه الوظيفة الرسوم البيانية المتعددة المرتبة حسب المحطات وحفظها على الجهاز المحلي على الدليل المطلوب أو الدليل الجذري. يتم استرداد البيانات من ملفات Excel أو CSV من دليل مرغوب أو جذر ويتم حفظ النتائج كتنسيق Excel مرتبة بواسطة المحطات على الدليل المطلوب أو الجذر. مثال:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
الإخراج:
pyinnovativetrend.ita_multiple_vis_by_column (الطول ، الرسم البياني = {} ، filename = [] ، column = [] ، ensoColumn = [] ، csv = false ، directory_path = "./")
توضح هذه الوظيفة الرسوم البيانية المتعددة المرتبة حسب المحطات وحفظها على الجهاز المحلي على الدليل المطلوب أو الدليل الجذري. يتم استرداد البيانات من ملفات Excel أو CSV من دليل مرغوب أو جذر ويتم حفظ النتائج كتنسيق Excel مرتبة بواسطة الأعمدة على الدليل المطلوب أو الجذر. مثال:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
الإخراج:
X: قائمة أو صفيف numpy
السلسلة الزمنية أو سلسلة البيانات التي يتم تحديد اتجاهها
الطول: عدد صحيح
طول السلسلة الزمنية. إذا كان طول السلسلة الزمنية أمرًا غريبًا ، فسيتم إدخال الأقدم/الأول.
اسم الملف: قائمة الافتراضيات جميع ملفات Excel/CSV
قائمة الملفات أو المحطات التي تحتوي على البيانات المرتبة حسب الشهر/السنة/الموسم.
العمود: قائمة الافتراضي جميع الأعمدة
قائمة الأعمدة أو سلسلة البيانات التي تحتوي على البيانات.
باستثناء Column: قائمة قائمة فارغة افتراضية
قائمة الأعمدة التي لا يلزم التحليل (على سبيل المثال ، عمود السنة).
CSV: Bool افتراضي خطأ نوع الملفات. بشكل افتراضي ، يكون نوع الملف Excel. ومع ذلك ، إذا كانت الملفات بتنسيق CSV ، فيجب تعيين CSV إلى True.
DIRECTORY_PATH: الجذر الافتراضي للسلسلة
مسار الدليل للملفات حيث يتم تخزين الملفات.
الإخراج: قائمة أسماء المحطة الافتراضية أو أسماء الأعمدة
اسم الملفات التي سيتم من خلالها حفظ النتائج.
out_direc: الجذر الافتراضي للسلسلة
مسار الدليل للملفات حيث سيتم حفظ النتائج.
ألفا: تعويم افتراضي 0.05
مستوى الأهمية في اختبار ثنائي الذيل.
Showgraph: Bool Default True
اختر ما إذا كان يتم توضيح الرسم البياني جنبا إلى جنب مع الحساب في تحليل واحد.
الرسم البياني: Python Dictionary (اختياري) القيم الافتراضية "Trendlinestyle": "متقطع" # خط خط الاتجاه ، لمزيد
"Scattermarker": "." # نوع علامة نقاط البيانات المبعثرة ، لمزيد من العلامات ، قم بزيارة وثائق Matplotlib
"العنوان": " # عنوان الرسم البياني أو التوضيح
'xlabel': 'First Sub-Series' # Label of X-axis
'Ylabel': 'Second Sub-Series' # label of y-axis
"Notrendlinestyle": "Solid" # Line Style of No Trend Line أو 1: 1 ، لمزيد
'Output_dir': './' # دليل ملف الإخراج حيث يتم حفظ الرسم البياني
'Output_Name': 'OutputFig.png' # اسم الرسم البياني أو التوضيح
'DPI': 300 # نقطة لكل بوصة (DPI) من الرسم البياني أو الرسم التوضيحي
"الصف": - # رقم الصف من المخططات الفرعية. إذا لم يتم توفيرها ، سيتم حسابها تلقائيًا. (متاح فقط للتحليل المتعدد)
'colm': - # رقم العمود من المخططات الفرعية. إذا لم يتم توفيرها ، سيتم حسابها تلقائيًا. (متاح فقط للتحليل المتعدد)
اتجاه:
يروي ما إذا كان الاتجاه موجود ونوع الاتجاه
H:
صحيح (إذا كان الاتجاه موجودًا) وخطأ (إذا كان الاتجاه غائبًا)
P:
قيمة p للاختبار الهام (اختبار ثنائي الذيل)
Z:
إحصائيات الاختبار الطبيعية (اختبار ثنائي الذيل)
المنحدر:
منحدر الاتجاه
standard_deviation:
الانحراف المعياري لسلسلة البيانات
slope_standard_deviation:
الانحراف المعياري لارتباط الميل:
العلاقة بين السلسلة الفرعية المرتبة
lower_critical_level:
انخفاض القيمة الحرجة للاختبار ثنائي الذيل
UPPER_CRITICAL_LEVEL:
القيمة الحرجة العلوية للاختبار ثنائي الذيل


