pyinnovativetrend
1.0.0
Die Trendanalyse ist eine statistische Technik, mit der Daten über die Zeit untersucht wurden, um Muster, Trends oder Bewegungen in eine bestimmte Richtung zu identifizieren. Es wird in verschiedenen Bereichen wie Finanzen, Wirtschaft, Marketing, Umweltwissenschaften und vielen anderen häufig eingesetzt. Eine sehr häufige und konventionelle Methode zur Erkennung des Trends ist der von Mann und Kendall vorgeschlagene Mann-Kendall-Trend-Test. Eine von Sen (2012) vorgeschlagene innovative Methode wird jedoch aufgrund ihrer Einfachheit und grafischen Merkmale häufig verwendet. Diese innovative Trendanalysemethode ist sehr empfindlich und kann Trends erkennen, die durch herkömmliche Methoden wie MK -Test übersehen werden.
Das Paket wird mit PIP installiert:
pip install pyinnovativetrend
pyinnovativetrend.ita_single (x, Länge, Alpha = 0,05, Graph = {}, Showgraph = true)
Diese Funktion berechnet den Trend und andere erforderliche Parameter für Einzellisten oder Numpy Array und gibt ein benanntes Tupel zurück. Standardmäßig wird ein Diagramm veranschaulicht und auf der lokalen Maschine gespeichert.
Beispiel:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single(x, 12, graph = graph)
Ausgabe: ITA (Trend = 'Nein Trend', H = Falsch, p = 0,2049477839420626, Z = -1.267580542826508, Steigung = -0.0277777777777752, Standard_Deviation = 1.255554326444432805, Slope_Standard_Deviation = 0,021914014011770254, Korrelation = 0,9341987329938274, Lower_critical_Level = -0.0429506782197758, upper_critical_level = 0,042950678219758)
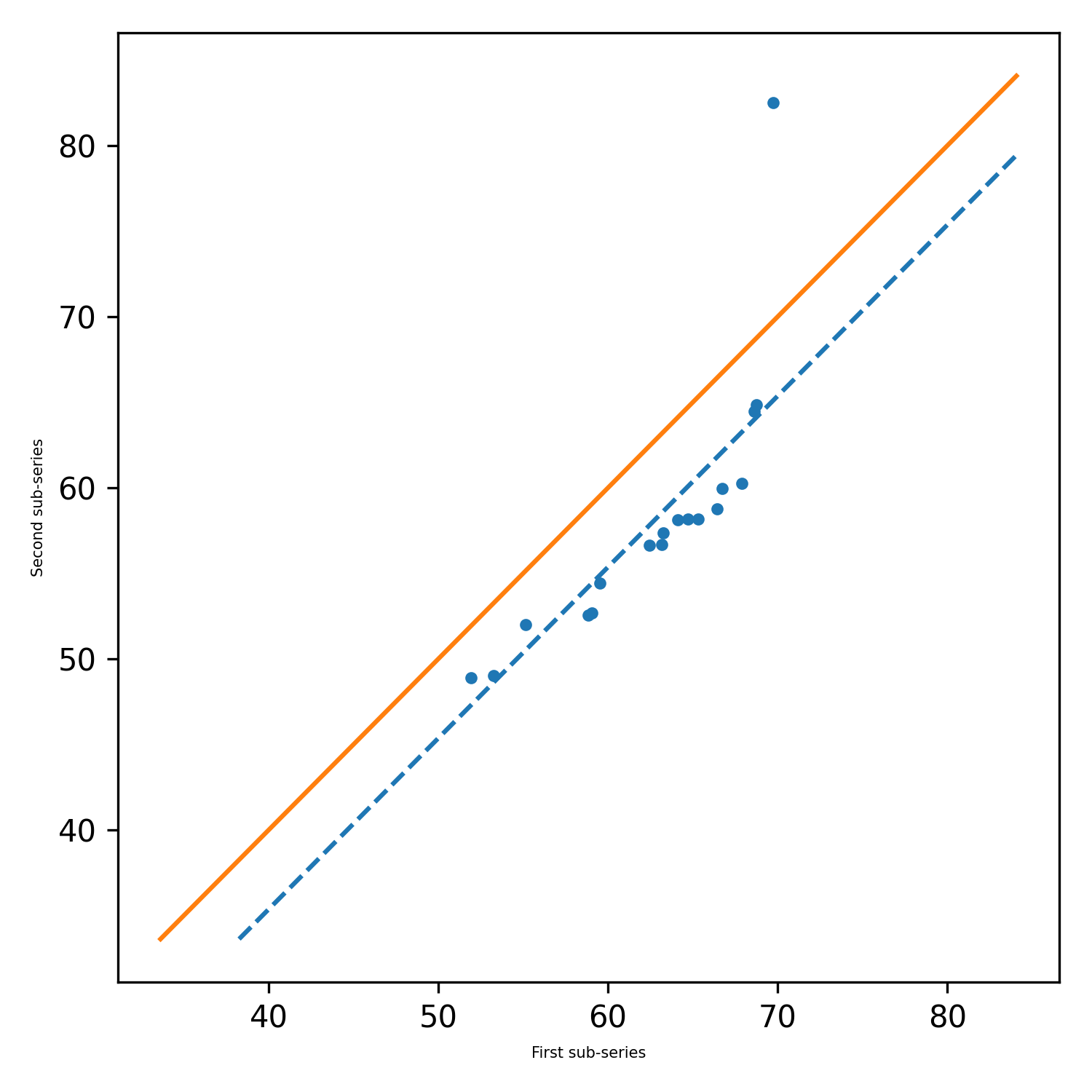
Ita_multiple_by_station (länge, fileName = [], column = [], fascolumn = [], graph = {}, alpha = 0,05, rnd = 2, csv = false, direcTory_path = "./", output = [], out_direc = "./").
Diese Funktion berechnet den Trend und andere erforderliche Parameter für mehrere Stationen. Die Daten werden aus Excel- oder CSV -Dateien aus einem gewünschten oder Root -Verzeichnis abgerufen und die Ergebnisse werden als Excel -Format gespeichert, das nach Stationen auf dem gewünschten oder rootes Verzeichnis sortiert ist. Standardmäßig werden mehrere nach Stationen sortierte Diagramme auf der lokalen Maschine im gewünschten Verzeichnis oder im Stammverzeichnis gespeichert.
Beispiel:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_station(38, exceptcolumn=['Year'], graph = graph)
Ausgabe:
Excel -Dateien Beispiel 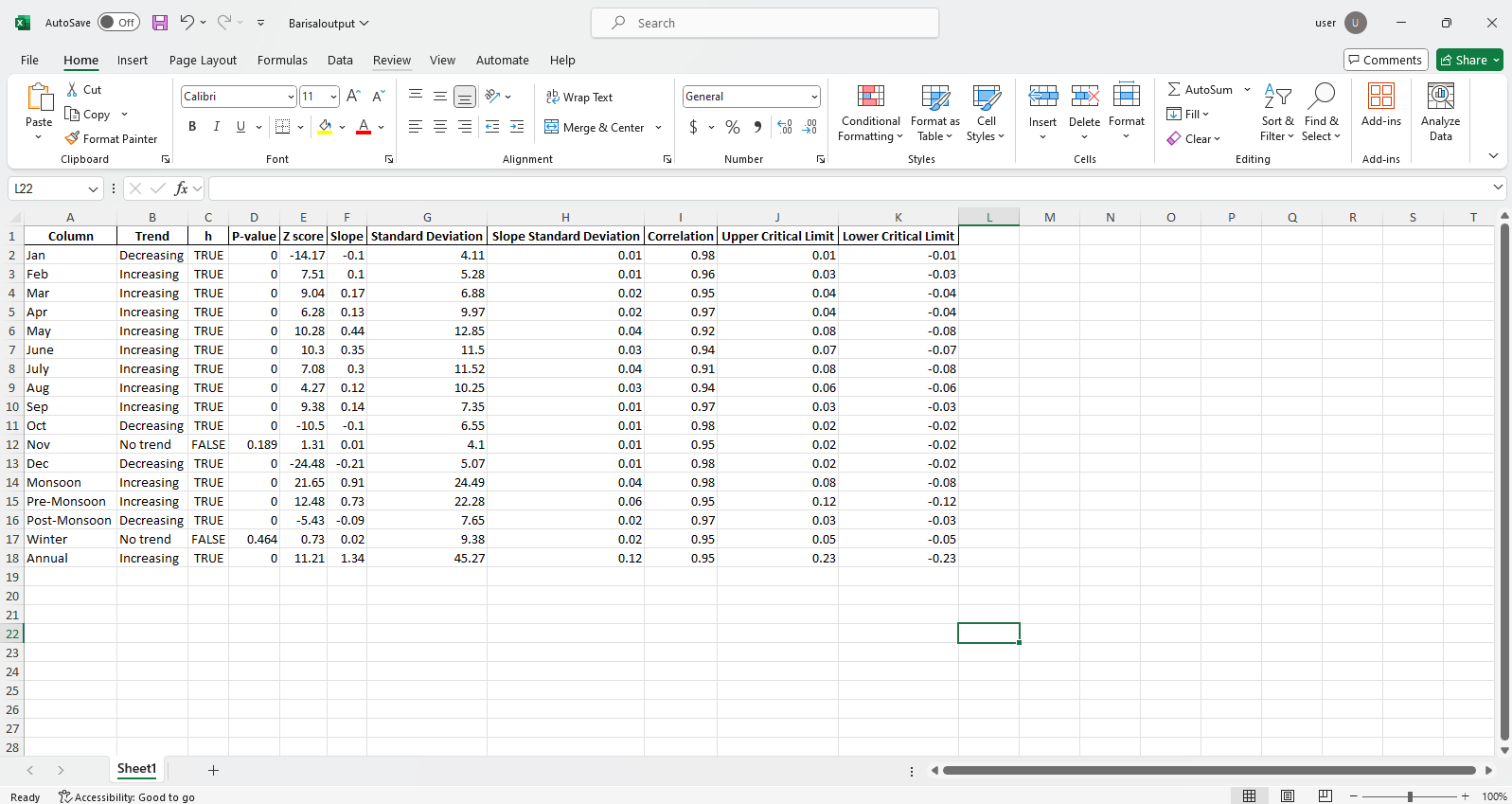 Abbildung Probe
Abbildung Probe 
pyinnovativetrend.ita_multiple_by_station (länge, fileName = [], column = [], fascolumn = [], graph = {}, alpha = 0.05, rnd = 2, csv = false, Directory_path = "./", Output = [], Out_Direc = "./").
Diese Funktion berechnet den Trend und andere erforderliche Parameter für mehrere Stationen. Die Daten werden aus Excel- oder CSV -Dateien aus einem gewünschten oder Root -Verzeichnis abgerufen und die Ergebnisse werden als Excel -Format gespeichert, das nach Spalten auf dem gewünschten oder Root -Verzeichnis sortiert ist. Standardmäßig werden mehrere Diagramme, die nach Spalten sortiert werden, veranschaulicht und auf der lokalen Maschine im gewünschten Verzeichnis oder im Stammverzeichnis gespeichert.
Beispiel:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_column(38, exceptcolumn=['Year'], graph = graph)
Ausgabe:
Excel -Dateien Beispiel 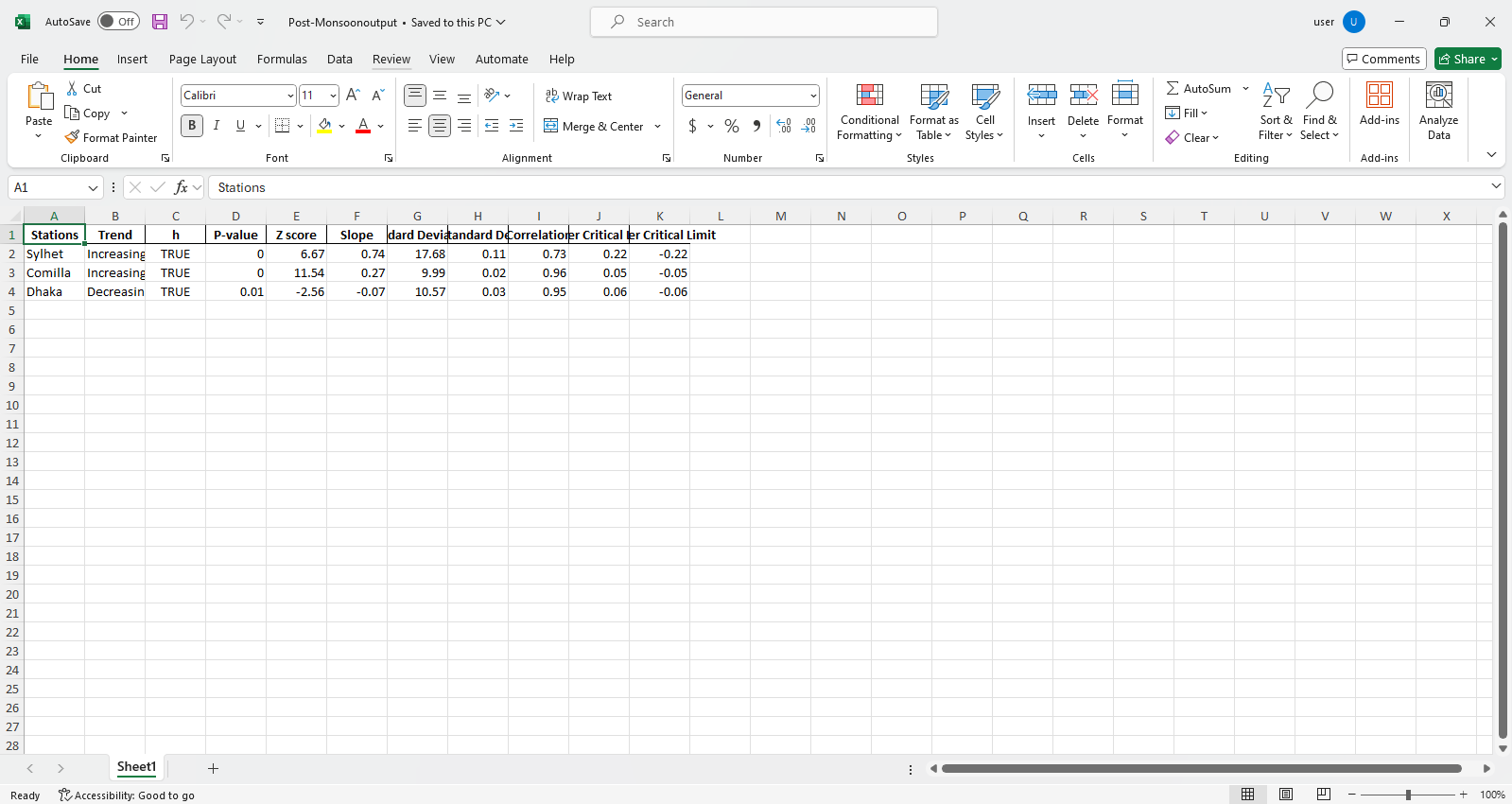 Abbildung Probe
Abbildung Probe 
pyinnovativetrend.ita_single_vis (x, länge, figsize = (10,10), graph = {})
Diese Funktion zeigt eine Grafik und speichert die lokale Maschine.
Beispiel:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single_vis(x, 12, graph = graph)
Ausgabe:
pyinnovativetrend.ita_multiple_vis_by_station (Länge, Graph = {}, fileName = [], column = [], außer column = [], csv = false, Directory_Path = "./")
Diese Funktion veranschaulicht mehrere Diagramme, die nach Stationen sortiert und auf der lokalen Maschine im gewünschten Verzeichnis oder im Root -Verzeichnis gespeichert werden. Die Daten werden aus Excel- oder CSV -Dateien aus einem gewünschten oder Root -Verzeichnis abgerufen und die Ergebnisse werden als Excel -Format gespeichert, das nach Stationen auf dem gewünschten oder rootes Verzeichnis sortiert ist. Beispiel:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
Ausgabe:
pyinnovativetrend.ita_multiple_vis_by_column (Länge, graph = {}, fileName = [], column = [], außerColumn = [], csv = false, direcTory_path = "./").
Diese Funktion veranschaulicht mehrere Diagramme, die nach Stationen sortiert und auf der lokalen Maschine im gewünschten Verzeichnis oder im Root -Verzeichnis gespeichert werden. Die Daten werden aus Excel- oder CSV -Dateien aus einem gewünschten oder Root -Verzeichnis abgerufen und die Ergebnisse werden als Excel -Format gespeichert, das nach Spalten auf dem gewünschten oder Root -Verzeichnis sortiert ist. Beispiel:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
Ausgabe:
X: Liste oder Numpy Array
Die Zeitreihen- oder Datenreihen, deren Trend bestimmt werden soll
Länge: Ganzzahl
Länge der Zeitreihe. Wenn die Zeitreihe der Zeit seltsam ist, wird der früheste/erster Eintrag beauftragt.
Dateiname: Listen Sie Standard für alle Excel/CSV -Dateien auf
Liste der Dateien oder Stationen, die die Daten enthalten, die nach Monat/Jahr/Jahreszeit sortiert sind.
Spalte: Listen Sie Standard alle Spalten auf
Liste der Spalten oder Datenserien, die die Daten enthalten.
Ausnahme von Column: Listen Sie die Standardliste für leere Listen auf
Liste der Spalten, für die keine Analyse erforderlich ist (z. B. Spalte des Jahres).
CSV: BOOL Standard FALSE Die Art der Dateien. Standardmäßig ist der Dateityp Excel. Wenn sich die Dateien jedoch im CSV -Format befinden, sollte CSV True zugewiesen werden.
Verzeichnis_Path: String -Standard -Root
Verzeichnispfad der Dateien, in denen die Dateien gespeichert werden.
Ausgabe: Listen Sie Standardstationsnamen oder Spaltennamen auf
Name der Dateien, durch die die Ergebnisse gespeichert werden.
OUT_DIREC: String Standard Root
Verzeichnispfad der Dateien, in denen die Ergebnisse gespeichert werden.
Alpha: Float Standard 0,05
Signifikanzniveau in einem zweiseitigen Test.
Showgraph: bool Standard true
Wählen Sie, ob das Diagramm zusammen mit der Berechnung in der einzelnen Analyse veranschaulicht werden soll.
Graph: Python Dictionary (optional) Standardwerte 'Trendlinestyle': 'gestrichelte' # Zeilenstil der Trendlinie, für mehr Linienstil -Typ -Dokumentation von Matplotlib.
'Scattermarker': '.' # Marker -Art von gestreuten Datenpunkten, um weitere Marker -Dokumentation von Matplotlib zu besuchen
'Titel': '' # Titel des Diagramms oder der Illustration
"XLabel": "Erste Sub-Serie" # Label der X-Achse
"Ylabel": "Zweite Sub-Serie" # Label der y-Achse
'Notrendlinestyle': 'Solid' # Zeilenstil ohne Trendlinie oder 1: 1 -Zeile, für mehr Linienstil -Typ -Dokumentation von Matplotlib
'output_dir': './' # Verzeichnis der Ausgabedatei, in der Grafik gespeichert werden soll
'output_name': 'outputFig.png' # Name des Diagramms oder der Abbildung
'DPI': 300 # Punkt pro Zoll (DPI) des Diagramms oder der Illustration
'Zeile': - # Zeilennummer der Nebenhandlungen. Wenn nicht angegeben, wird automatisch berechnet. (Nur für mehrere Analysen verfügbar)
'colm': - # Spaltennummer der Nebenhandlungen. Wenn nicht angegeben, wird automatisch berechnet. (Nur für mehrere Analysen verfügbar)
Trend:
Sagt, ob Trend existiert und eine Art Trend
H:
Wahr (wenn der Trend vorhanden ist) und falsch (wenn der Trend fehlt)
P:
P-Wert für den signifikanten Test (2-tailed-Test)
z:
Normalisierte Teststatistiken (2 -schwanzer-Test)
Neigung:
Hang des Trends
Standard_Deviation:
Standardabweichung der Datenreihen
Slope_Standard_Deviation:
Standardabweichung der Hangkorrelation:
Korrelation zwischen der sortierten Sub-Serie
Lower_critical_level:
Niedrigerer kritischer Wert für 2-tailed-Test
Upper_critical_level:
Oberer kritischer Wert für 2-tailed-Test


