pyinnovativetrend
1.0.0
Анализ тенденций - это статистический метод, используемый для изучения данных с течением времени для определения закономерностей, тенденций или движений в определенном направлении. Он широко используется в различных областях, таких как финансы, экономика, маркетинг, наука о окружающей среде и многие другие. Очень распространенным и обычным методом обнаружения тренда является тест Тенденции Манн-Кендалла, предложенный Манном и Кендаллом. Тем не менее, инновационный метод, предложенный Sen (2012), широко используется в настоящее время из-за его простоты и графических особенностей. Этот инновационный метод анализа тенденций очень чувствителен и может обнаружить тенденции, которые упускаются из виду обычными методами, такими как тест MK.
Пакет установлен с использованием PIP:
pip install pyinnovativetrend
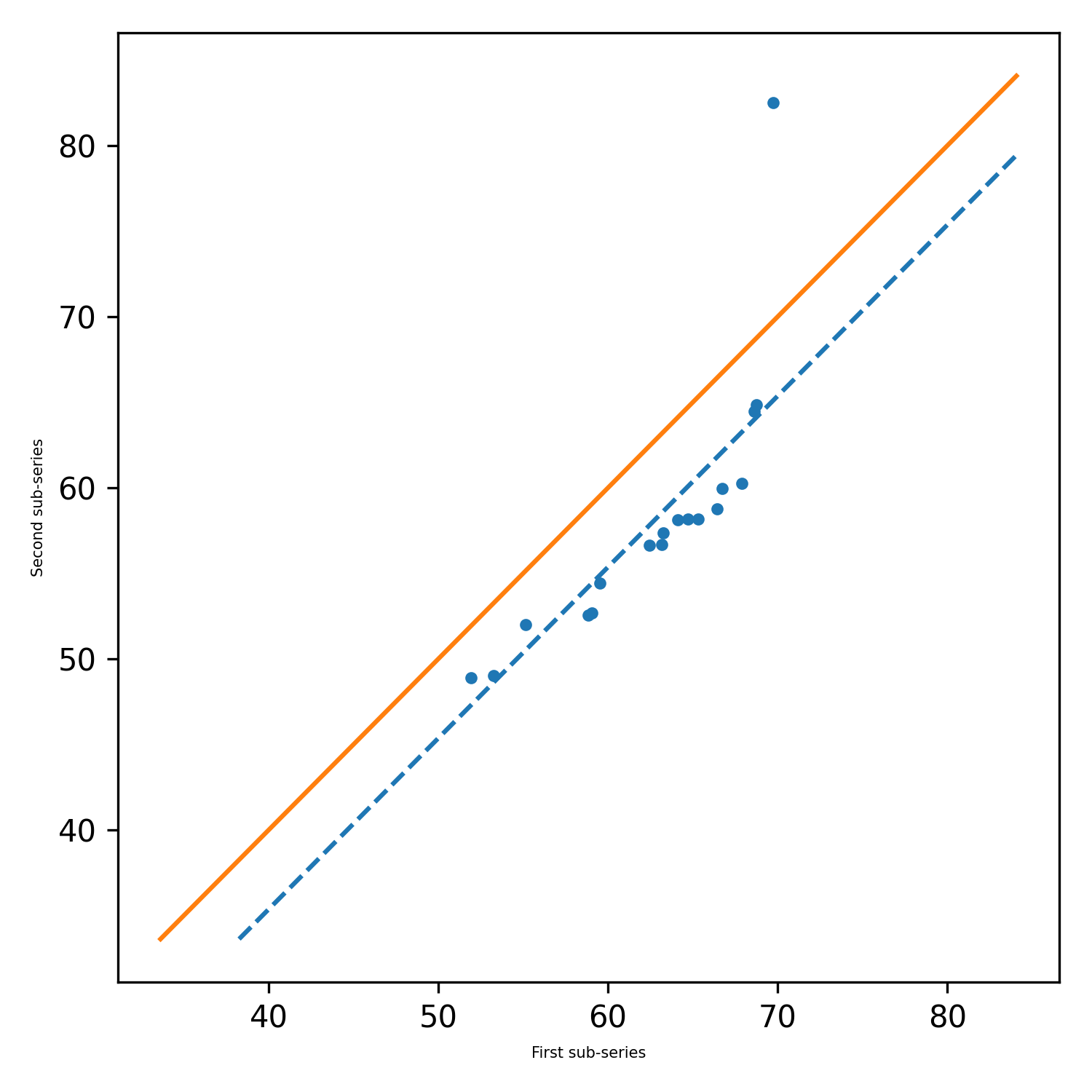
pyinnovativetrend.ita_single (x, длина, альфа = 0,05, graph = {}, showgraph = true)
Эта функция вычисляет тренд и другие необходимые параметры для отдельного списка или массива Numpy и возвращает названный кортеж. По умолчанию график иллюстрируется и сохраняется на локальной машине.
Пример:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single(x, 12, graph = graph)
Вывод: ITA (тренд = 'без тренда', h = false, p = 0,2049477839420626, z = -1,2675805428826508, slope = -0,02777777777777752, standard_deviation = 1,2555432444432805, Standard_deviatia slope_standard_deviation = 0,021914014011770254, Correlation = 0,9341987329938274, Lower_critical_Level = -0,0429506782197758, uper_critical_level = 0,042950678217788), uper_critical_level = 0,042950678217788), uper_critical_level = 0,04295067821788), UPER_CRITICAL_LEVEL = 0,04295067821788), UPER_CRITICAL_LEVE
Ita_multiple_by_station (length, filename = [], column = [], lesscolumn = [], graph = {}, alpha = 0,05, rnd = 2, csv = false, directory_path = "./, output = [], out_direc =" ./)
Эта функция вычисляет тренд и другие необходимые параметры для нескольких станций. Данные извлекаются из файлов Excel или CSV из желаемого или корневого каталога, и результаты сохраняются в виде формата Excel, сортируемого по станциям на желаемом или корневом каталоге. По умолчанию несколько графиков, отсортированных по станциям, проиллюстрированы и сохраняются на локальной машине на желаемом каталоге или корневом каталоге.
Пример:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_station(38, exceptcolumn=['Year'], graph = graph)
Выход:
Excel файлов образец 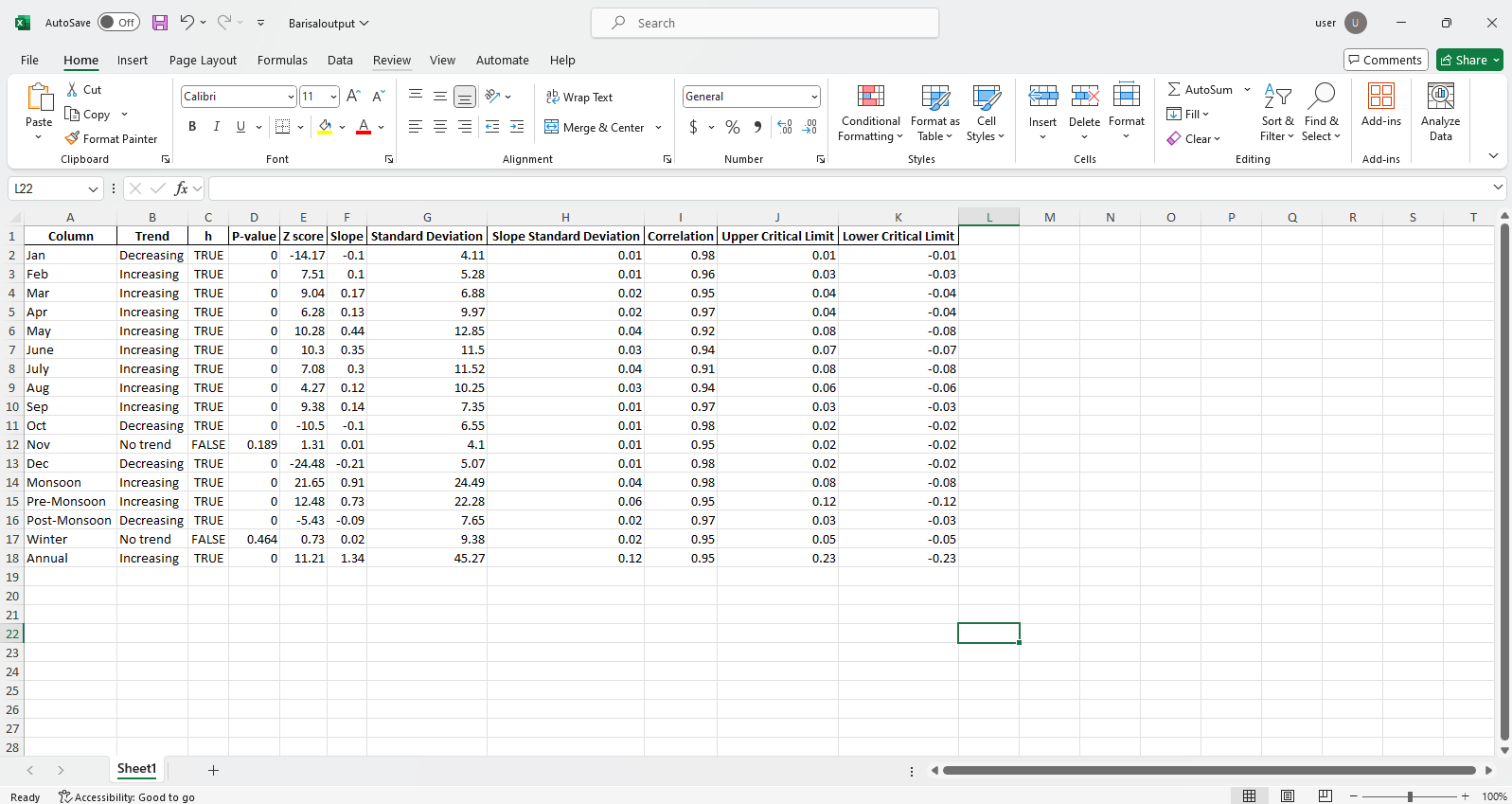 Рисунок образец
Рисунок образец 
pyinnovativetrend.ita_multiple_by_station (length, filename = [], column = [], lesscolumn = [], graph = {}, alpha = 0.05, rnd = 2, csv = false, directory_path = "./, output = [], out_direc =".
Эта функция вычисляет тренд и другие необходимые параметры для нескольких станций. Данные извлекаются из файлов Excel или CSV из желаемого или корневого каталога, и результаты сохраняются в виде формата Excel, сортированного по столбцам в желаемом или корневом каталоге. По умолчанию несколько графиков, отсортированных по столбцам, проиллюстрированы и сохраняются на локальной машине на желаемом каталоге или корневом каталоге.
Пример:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_column(38, exceptcolumn=['Year'], graph = graph)
Выход:
Excel файлов образец 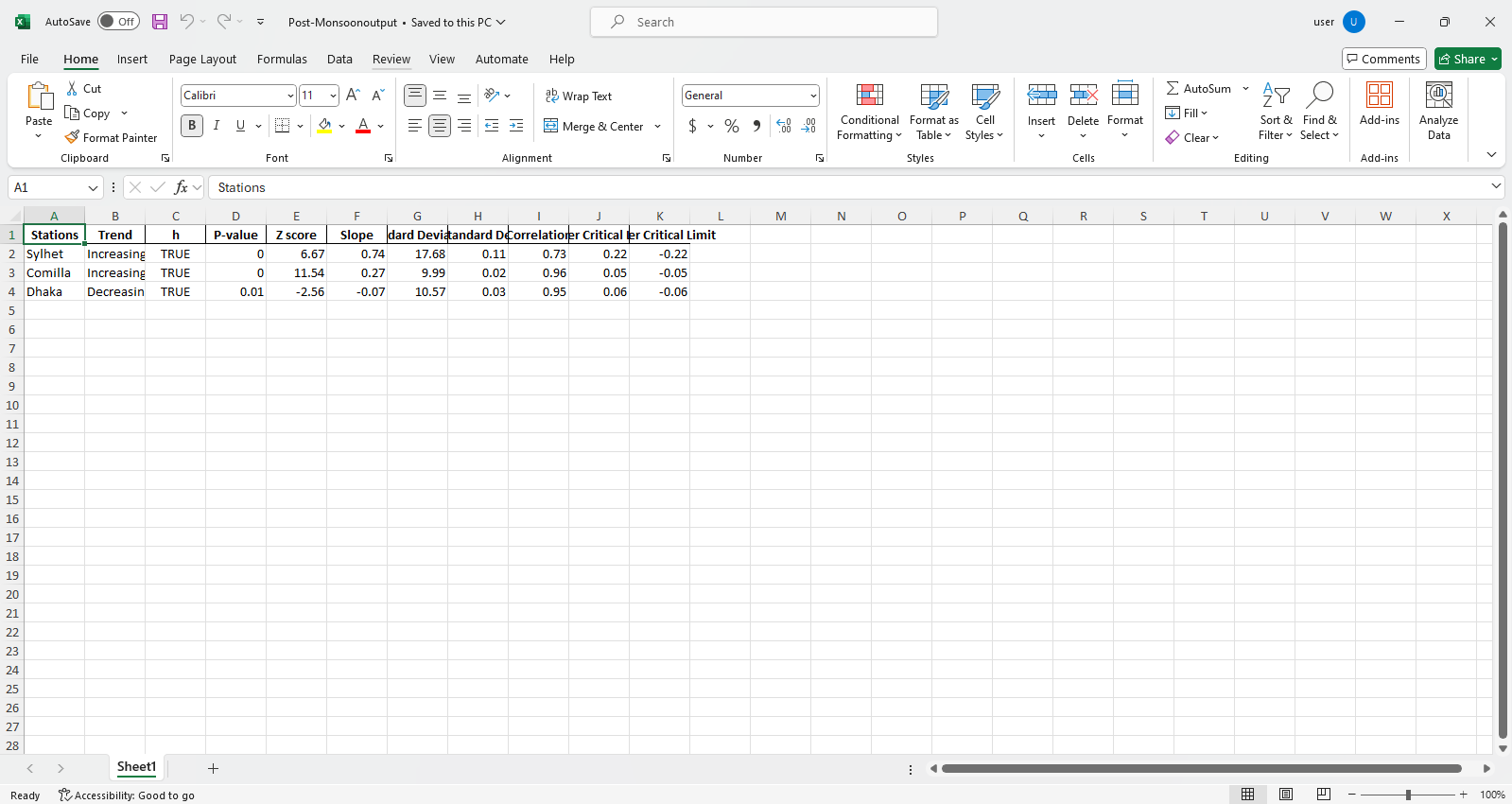 Рисунок образец
Рисунок образец 
pyinnovativetrend.ita_single_vis (x, длина, рис.
Эта функция иллюстрирует график и сохраняет локальную машину.
Пример:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single_vis(x, 12, graph = graph)
Выход:
pyinnovativetrend.ita_multiple_vis_by_station (length, graph = {}, filename = [], column = [], lesscolumn = [], csv = false, directory_path = "./")
Эта функция иллюстрирует несколько графиков, отсортированных по станциям и сохраняет локальную машину на желаемом каталоге или корневом каталоге. Данные извлекаются из файлов Excel или CSV из желаемого или корневого каталога, и результаты сохраняются в виде формата Excel, сортируемого по станциям на желаемом или корневом каталоге. Пример:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
Выход:
pyinnovativetrend.ita_multiple_vis_by_column (length, graph = {}, filename = [], column = [], кроме Column = [], csv = false, directory_path = "./")
Эта функция иллюстрирует несколько графиков, отсортированных по станциям и сохраняет локальную машину на желаемом каталоге или корневом каталоге. Данные извлекаются из файлов Excel или CSV из желаемого или корневого каталога, и результаты сохраняются в виде формата Excel, сортированного по столбцам в желаемом или корневом каталоге. Пример:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
Выход:
X: список или массив Numpy
Временные ряды или серии данных, чья тенденция должна быть определена
Длина: целое число
Длина временных рядов. Если длина времени временного ряда нечетная, самая ранняя/первая запись будет представлена.
Имя файла: список по умолчанию все файлы Excel/CSV
Список файлов или станций, которые содержат данные, сортируемые по месяцу/год/сезон.
Столбец: список по умолчанию все столбцы
Список столбцов или серии данных, которые содержат данные.
Кроме того
Список столбцов, для которых анализ не требуется (например, столбец года).
CSV: bool по умолчанию false the type of files. По умолчанию тип файла - Excel. Однако, если файлы находятся в формате CSV, CSV должен быть назначен true.
Directory_path: root root строки по умолчанию
Путь каталога файлов, где хранятся файлы.
Вывод: Перепис имена станций по умолчанию или имена столбцов
Имя файлов, с помощью которых результаты будут сохранены.
out_direc: root root строки по умолчанию
Путь каталога файлов, где будут сохранены результаты.
Альфа: по умолчанию по умолчанию 0,05
Уровень значимости в двухстороннем тесте.
ShowGraph: bool по умолчанию True
Выберите, если график должен быть проиллюстрирован вместе с расчетом в едином анализе.
График: Dictionary Python (необязательно) Значения по умолчанию «TrendlineStyle»: «Депутанный» # Стиль линии линии тренда, для большего количества линии типа стиля Посетите документацию Matplotlib
'Scattermarker': '.' # Маркер тип разбросанных точек данных, для большей маркера, посетите документацию Matplotlib
«Название»: '' # Название графика или иллюстрации
'xlabel': 'First Sub-Series' # Метка о оси X
«ylabel»: «Второй подсерии» # метка оси Y
'notrendlinestyle': 'Solid' # Line Style of No Trend Line или Line 1: 1, для большего количества стиля линии. Посетите документацию Matplotlib
'output_dir': './' # каталог выходного файла, где должен быть сохранен график
'output_name': 'outputfig.png' # имя графика или иллюстрации
'DPI': 300 # точка на дюйм (DPI) графика или иллюстрации
'row': - # Номер строки подзасконств. Если не предоставлено, будет рассчитываться автоматически. (Доступно только для множественного анализа)
'colm': - # Номер столбца подприводов. Если не предоставлено, будет рассчитываться автоматически. (Доступно только для множественного анализа)
тенденция:
Сообщает, существует ли тенденция и тип тенденции
час:
Верно (если присутствует тенденция) и ложь (если тренд отсутствует)
П:
P-значение для значительного теста (2-х хрустальный тест)
Z:
Нормализованная статистика тестирования (2-х хвостого теста)
склон:
Склон тренда
standard_deviation:
стандартное отклонение серии данных
slope_standard_deviation:
Стандартное отклонение корреляции склона:
Корреляция между отсортированными подсериями
lower_critical_level:
Более низкое критическое значение для 2-х хвостого теста
overs_critical_level:
Верхнее критическое значение для 2-х хвостого теста


