pyinnovativetrend
1.0.0
추세 분석은 시간이 지남에 따라 데이터를 검사하여 특정 방향으로 패턴, 추세 또는 움직임을 식별하는 데 사용되는 통계 기술입니다. 금융, 경제, 마케팅, 환경 과학 및 기타 여러 분야에서 널리 사용됩니다. 추세를 감지하는 매우 일반적이고 일반적인 방법은 Mann과 Kendall이 제안한 Mann-Kendall 트렌드 테스트입니다. 그러나 Sen (2012)이 제안한 혁신적인 방법은 단순성과 그래픽 기능으로 인해 오늘날에 널리 사용됩니다. 이 혁신적인 추세 분석 방법은 매우 민감하며 MK 테스트와 같은 기존의 방법으로 간과되는 추세를 감지 할 수 있습니다.
패키지는 PIP를 사용하여 설치됩니다.
pip install pyinnovativetrend
pyinnovativetrend.ita_single (x, 길이, alpha = 0.05, 그래프 = {}, showgraph = true)
이 기능은 단일 목록 또는 Numpy 배열에 대한 추세 및 기타 필요한 매개 변수를 계산하고 명명 된 튜플을 반환합니다. 기본적으로 로컬 컴퓨터에 그래프가 표시되고 저장됩니다.
예:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
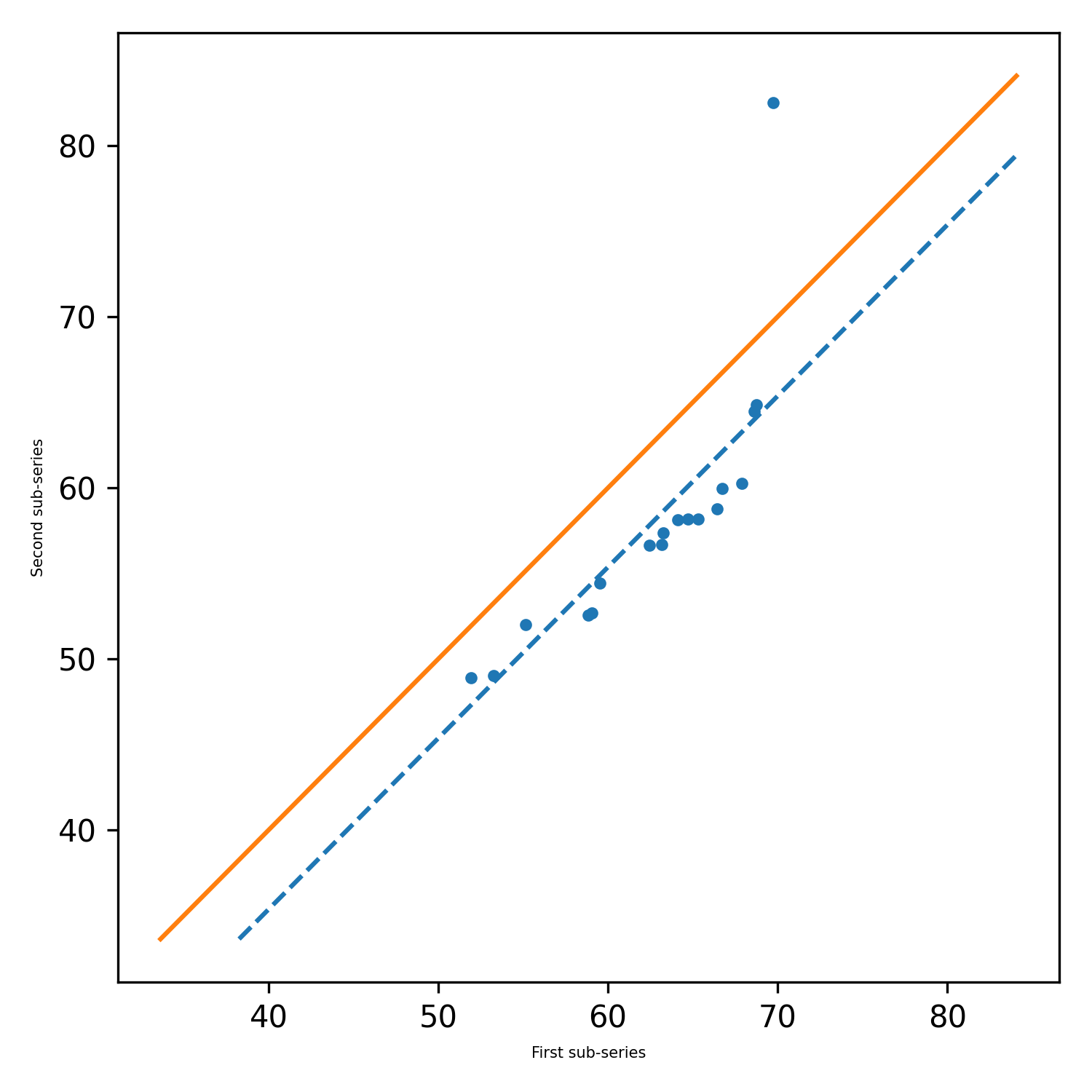
pit.ITA_single(x, 12, graph = graph)
출력 : ITA (Trend = 'No Trend', H = False, P = 0.2049477839420626, Z = -1.2675805428826508, 슬로프 = -0.0.0277777777777777752, Standard_Deviation = 1.2555532644432805, slope_standard_deviation = 0.0219140140140114011770254, 상관 관계 = 0.9341987329938274, lower_critical_level = -0.042950678219758, UPER_CRITICAL_LEVEL = 0.042950678219758888882197758).
ita_multiple_by_station (길이, filename = [], column = [], colum = [], collumn = [], graph = {}, alpha = 0.05, rnd = 2, csv = false, directory_path = "./", output = [], out_direc = "./")
이 기능은 여러 스테이션에 대한 추세 및 기타 필요한 매개 변수를 계산합니다. 데이터는 원하는 또는 루트 디렉토리의 Excel 또는 CSV 파일에서 검색되며 결과는 원하는 또는 루트 디렉토리의 스테이션별로 정렬 된 Excel 형식으로 저장됩니다. 기본적으로 스테이션별로 정렬 된 여러 그래프가 원하는 디렉토리 또는 루트 디렉토리의 로컬 컴퓨터에 표시되고 저장됩니다.
예:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_station(38, exceptcolumn=['Year'], graph = graph)
산출:
Excel 파일 샘플 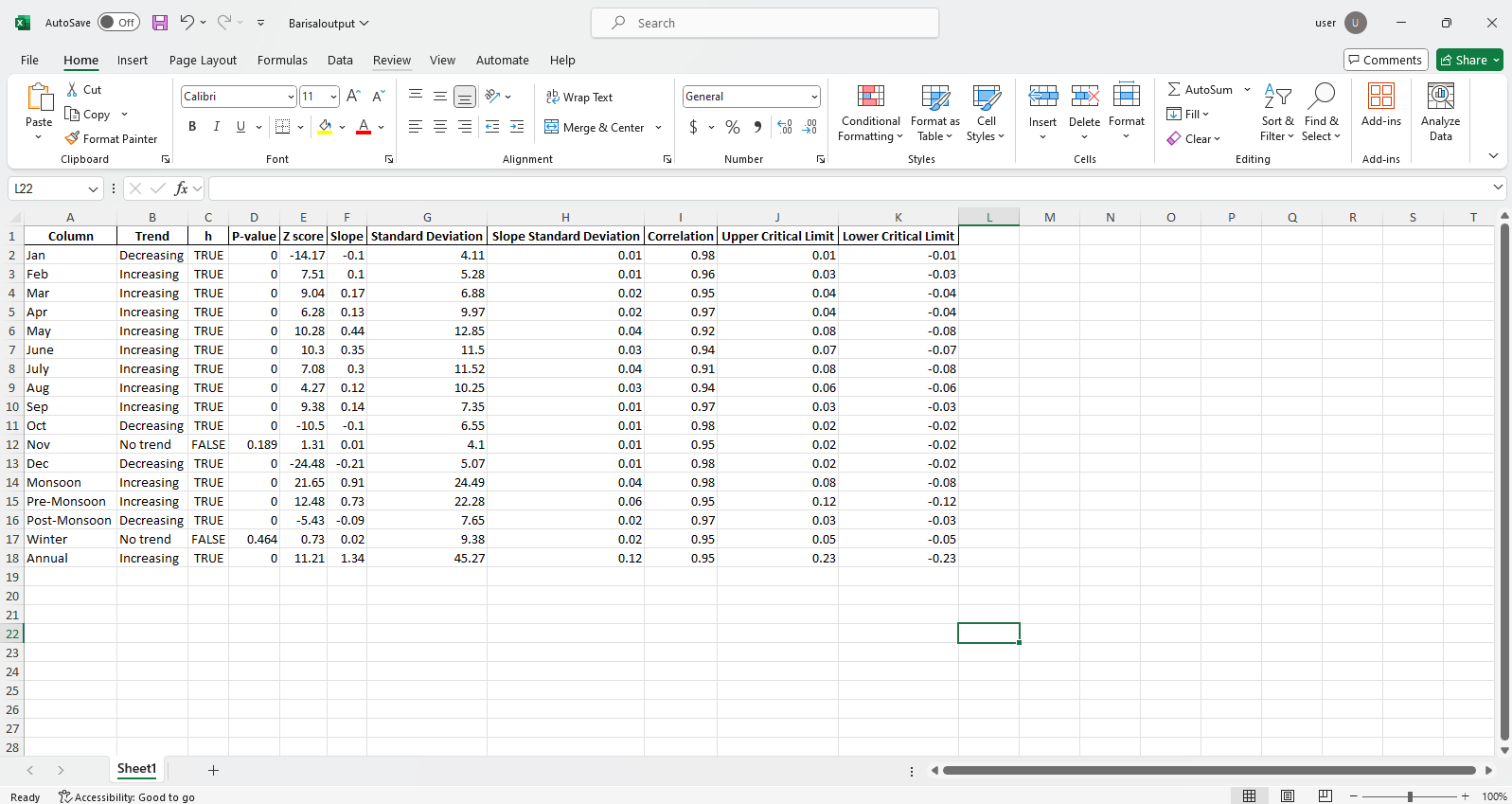 그림 샘플
그림 샘플 
pyinnovativetrend.ita_multiple_by_station (길이, filename = [], column = [], column = [], graph = {}, alpha = 0.05, rnd = 2, csv = false, directory_path = "./", output = [], out_direc = ")).
이 기능은 여러 스테이션에 대한 추세 및 기타 필요한 매개 변수를 계산합니다. 데이터는 원하는 또는 루트 디렉토리의 Excel 또는 CSV 파일에서 검색되며 결과는 원하는 또는 루트 디렉토리의 열별로 정렬 된 Excel 형식으로 저장됩니다. 기본적으로 열로 정렬 된 여러 그래프가 원하는 디렉토리 또는 루트 디렉토리의 로컬 컴퓨터에 표시되고 저장됩니다.
예:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_column(38, exceptcolumn=['Year'], graph = graph)
산출:
Excel 파일 샘플 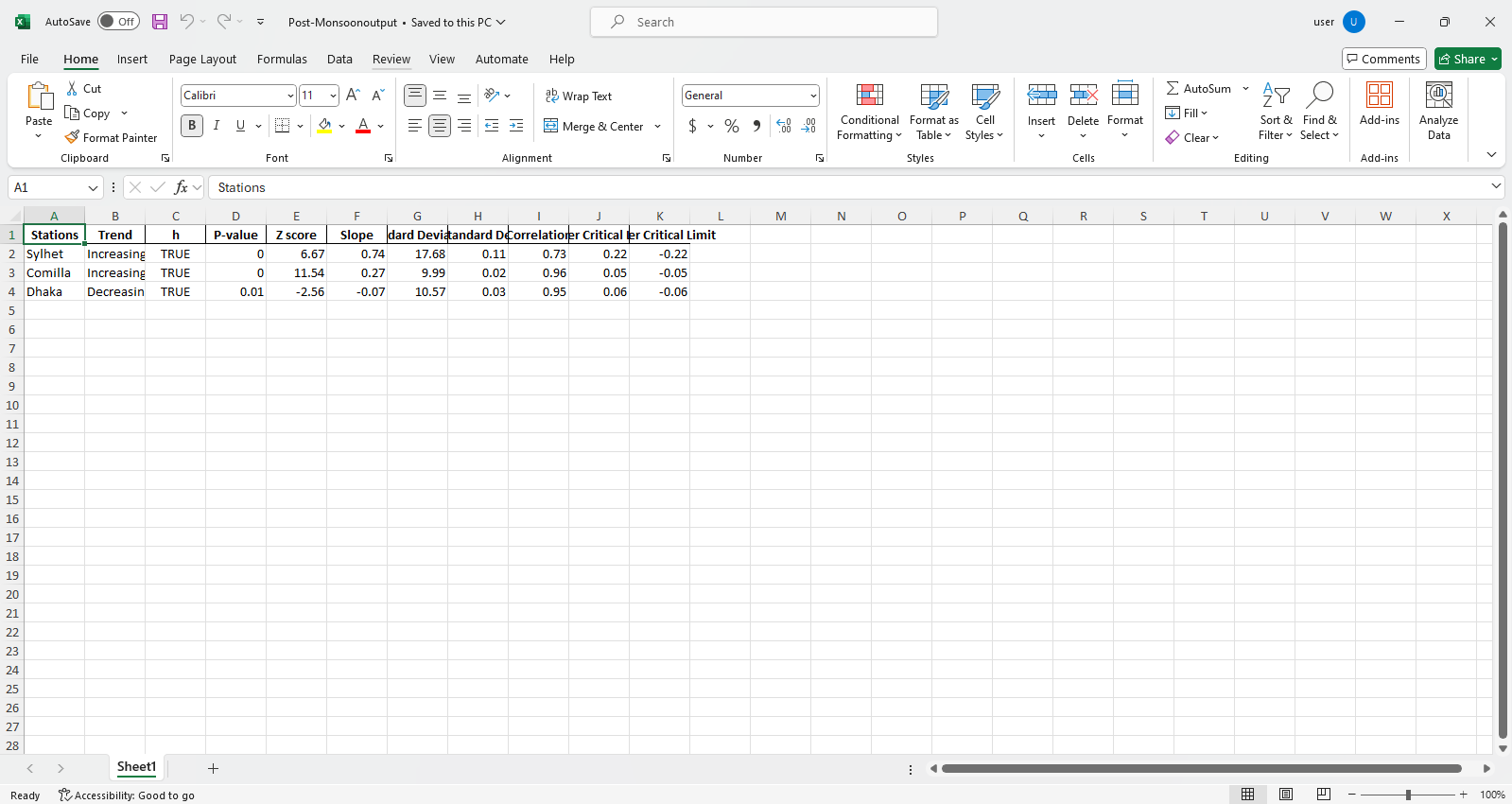 그림 샘플
그림 샘플 
pyinnovativetrend.ita_single_vis (x, 길이, figsize = (10,10), 그래프 = {})
이 기능은 그래프를 보여주고 로컬 컴퓨터를 저장합니다.
예:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single_vis(x, 12, graph = graph)
산출:
pyinnovativetrend.ita_multiple_vis_by_station (길
이 기능은 스테이션별로 정렬 된 여러 그래프를 보여주고 원하는 디렉토리 또는 루트 디렉토리의 로컬 컴퓨터에서 저장합니다. 데이터는 원하는 또는 루트 디렉토리의 Excel 또는 CSV 파일에서 검색되며 결과는 원하는 또는 루트 디렉토리의 스테이션별로 정렬 된 Excel 형식으로 저장됩니다. 예:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
산출:
pyinnovativetrend.ita_multiple_vis_by_column (길
이 기능은 스테이션별로 정렬 된 여러 그래프를 보여주고 원하는 디렉토리 또는 루트 디렉토리의 로컬 컴퓨터에서 저장합니다. 데이터는 원하는 또는 루트 디렉토리의 Excel 또는 CSV 파일에서 검색되며 결과는 원하는 또는 루트 디렉토리의 열별로 정렬 된 Excel 형식으로 저장됩니다. 예:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
산출:
X : 목록 또는 Numpy 배열
트렌드를 결정하는 시계열 또는 데이터 시리즈
길이 : 정수
시계열의 길이. 주어진 시계열의 길이가 홀수 인 경우, 가장 빠른/첫 번째 항목이 헌신됩니다.
Filename : List Default All Excel/CSV 파일
월/년/계절별로 정렬 된 데이터를 포함하는 파일 또는 스테이션 목록.
열 : 기본값 모든 열을 나열하십시오
데이터가 포함 된 열 또는 데이터 시리즈 목록.
Column을 제외하고 : 기본 빈 목록을 나열하십시오
분석이 필요하지 않은 열 목록 (예 : 연도 열).
CSV : BOOL DEFAULT FALSE 파일 유형입니다. 기본적으로 파일 유형은 Excel입니다. 그러나 파일이 CSV 형식 인 경우 CSV를 true에 할당해야합니다.
directory_path : 문자열 기본 루트입니다
파일이 저장된 파일의 디렉토리 경로.
출력 : 기본 스테이션 이름 또는 열 이름을 나열하십시오
결과가 저장 될 파일의 이름.
out_direc : 문자열 기본 루트
결과가 저장 될 파일의 디렉토리 경로.
알파 : 플로트 기본 0.05
양측 테스트에서 중요 수준.
Showgraph : Bool Default True
단일 분석에서 계산과 함께 그래프를 설명할지 선택하십시오.
그래프 : Python Dictionary (선택 사항) 기본값 'TrendlineStyle': 'Dashed' # 라인 스타일의 추세 라인, Matplotlib의 더 많은 라인 스타일 유형 방문 문서 방문 문서화
'산점도': '.' # 마커 유형 흩어져있는 데이터 포인트 유형, 더 많은 마커는 matplotlib의 문서를 방문하십시오.
'제목': '' # 그래프 또는 일러스트레이션 제목
'xlabel': x 축의 '첫 번째 하위 시리즈' # 레이블
'ylabel': '두 번째 하위 시리즈' # y 축 라벨
'NOTRENDLINESTYLE': 'SOLID' # LINE 스타일의 트렌드 라인 또는 1 : 1 라인, 더 많은 라인 스타일 유형 방문 matplotlib 방문 문서화
'output_dir': './' # 그래프를 저장할 출력 파일의 디렉토리
'output_name': 'outputfig.png' # 그래프 또는 그림의 이름
'dpi': 300 # 그래프 또는 그림의 인치당 (dpi)
'행': - # 서브 플로트의 행 번호. 제공되지 않으면 자동으로 계산됩니다. (여러 분석에만 사용할 수 있음)
'colm': - # 서브 플로트의 열 번호. 제공되지 않으면 자동으로 계산됩니다. (여러 분석에만 사용할 수 있음)
경향:
추세가 존재하고 추세의 유형이 있는지 알려줍니다
시간:
True (추세가있는 경우) 및 False (트렌드가없는 경우)
피:
중요한 테스트를위한 p- 값 (2- 꼬리 테스트)
지:
정규화 된 테스트 통계 (2- 꼬리 테스트)
경사:
트렌드의 경사
Standard_Deviation :
데이터 시리즈의 표준 편차
slope_standard_deviation :
경사 상관의 표준 편차 :
분류 된 하위 시리즈 간의 상관 관계
lower_critical_level :
양측 테스트의 임계 값이 낮습니다
Upper_Critical_Level :
양측 테스트의 상위 임계 값


