pyinnovativetrend
1.0.0
El análisis de tendencias es una técnica estadística utilizada para examinar los datos a lo largo del tiempo para identificar patrones, tendencias o movimientos en una dirección particular. Se usa ampliamente en varios campos, como finanzas, economía, marketing, ciencias ambientales y muchos otros. Un método muy común y convencional para detectar tendencia es la prueba de tendencia de Mann-Kendall propuesta por Mann y Kendall. Sin embargo, un método innovador, propuesto por Sen (2012), se usa ampliamente hoy en día debido a su simplicidad y características gráficas. Este innovador método de análisis de tendencias es muy sensible y puede detectar tendencias que se pasan por alto por métodos convencionales como MK Test.
El paquete se instala con PIP:
pip install pyinnovativetrend
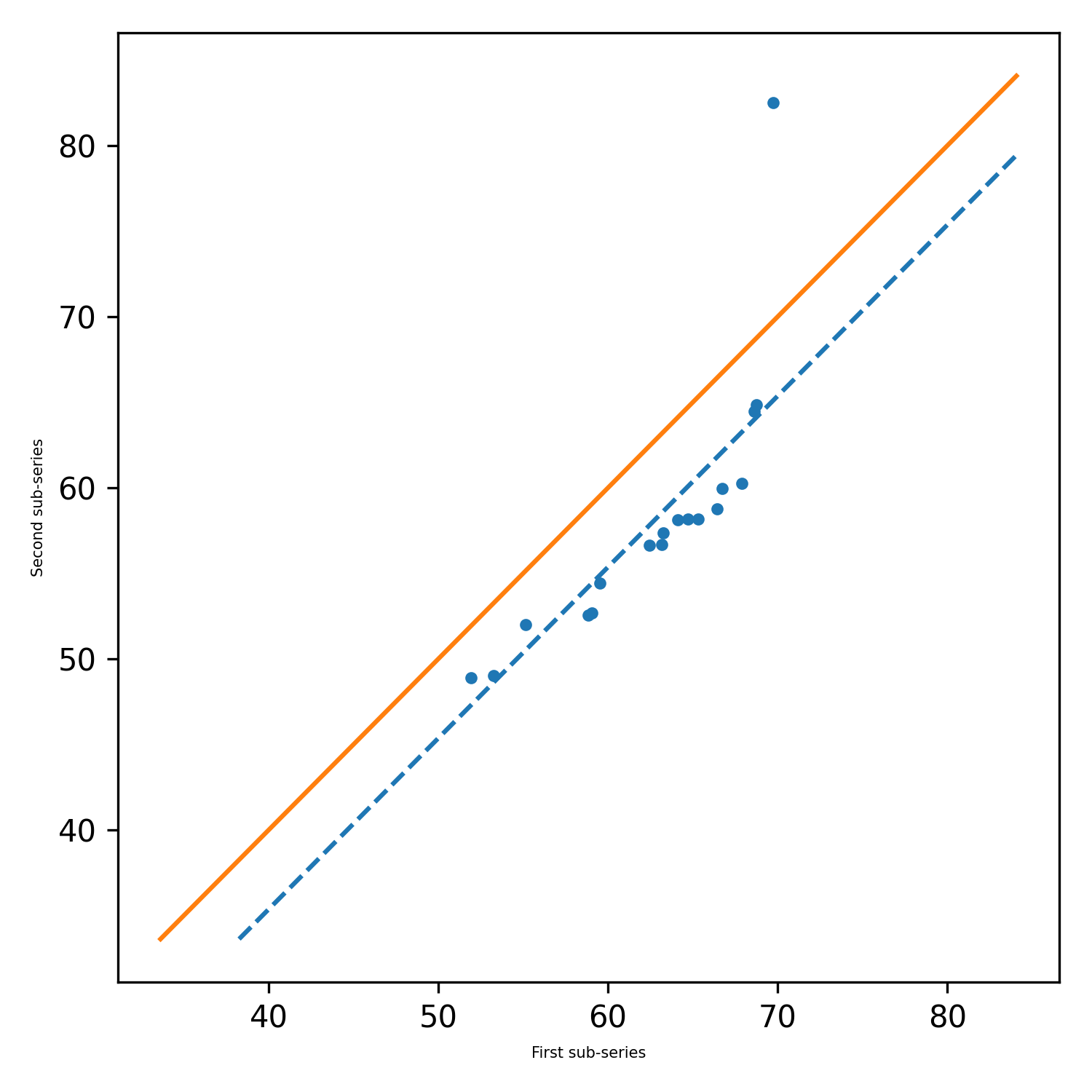
pyinnovativetrend.ita_single (x, longitud, alfa = 0.05, gráfico = {}, showgraph = true)
Esta función calcula la tendencia y otros parámetros necesarios para una lista única o una matriz Numpy y devuelve una tupla llamada. Por defecto, se ilustra y se guarda un gráfico en la máquina local.
Ejemplo:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single(x, 12, graph = graph)
Salida: ITA (Trend = 'No Trend', H = False, P = 0.2049477839420626, z = -1.2675805428826508, slope = -0.02777777777777777752, Standard_deviation = 1.25555432644432805,, slope_standard_deviation = 0.021914014011770254, correlación = 0.9341987329938274, Lower_Critical_Level = -0.042950678219758, uper_critical_level = 0.04295067821977588)
Ita_multiple_by_station (longitud, filename = [], columna = [], exceptocolumn = [], gráfico = {}, alfa = 0.05, rnd = 2, csv = false, directorio_path = "./", output = [], out_direc = "./")
Esta función calcula la tendencia y otros parámetros necesarios para múltiples estaciones. Los datos se recuperan de los archivos Excel o CSV de un directorio deseado o raíz y los resultados se guardan como formato de Excel ordenado por las estaciones en el directorio deseado o raíz. Por defecto, se ilustran y guardan múltiples gráficos múltiples ordenados por estaciones en la máquina local en el directorio deseado o el directorio raíz.
Ejemplo:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_station(38, exceptcolumn=['Year'], graph = graph)
Producción:
Muestra de archivos de Excel 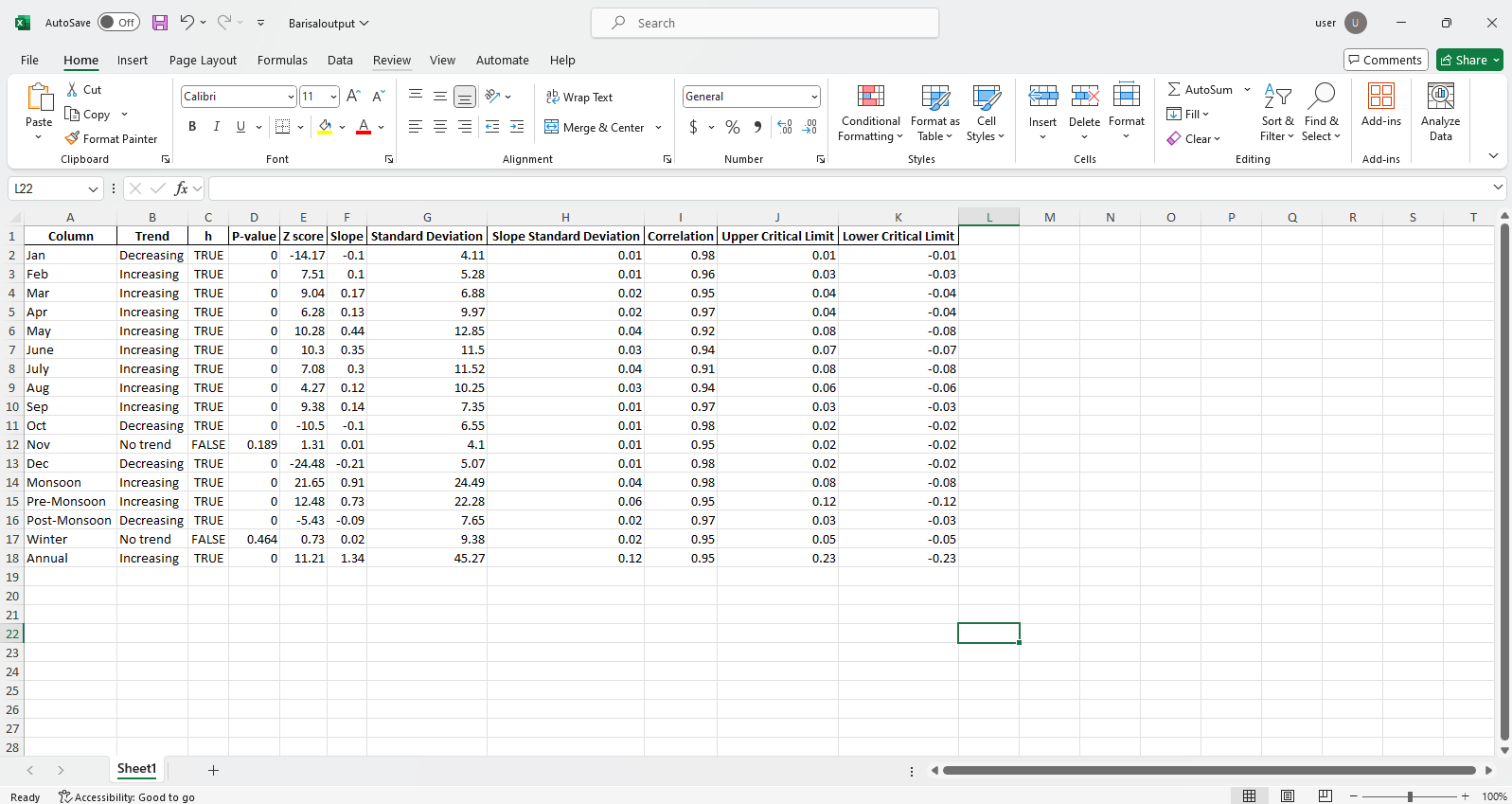 Muestra de figura
Muestra de figura 
pyinnovativetrend.ita_multiple_by_station (longitud, filename = [], column = [], exceptocolumn = [], gráfico = {}, alfa = 0.05, rnd = 2, csv = false, directorio_path = "./", salida = [], out_direc = "./")
Esta función calcula la tendencia y otros parámetros necesarios para múltiples estaciones. Los datos se recuperan de los archivos Excel o CSV de un directorio deseado o raíz y los resultados se guardan como formato de Excel ordenado por columnas en el directorio deseado o raíz. De manera predeterminada, se ilustran y guardan múltiples gráficos múltiples ordenados por columnas en la máquina local en el directorio deseado o el directorio raíz.
Ejemplo:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_column(38, exceptcolumn=['Year'], graph = graph)
Producción:
Muestra de archivos de Excel 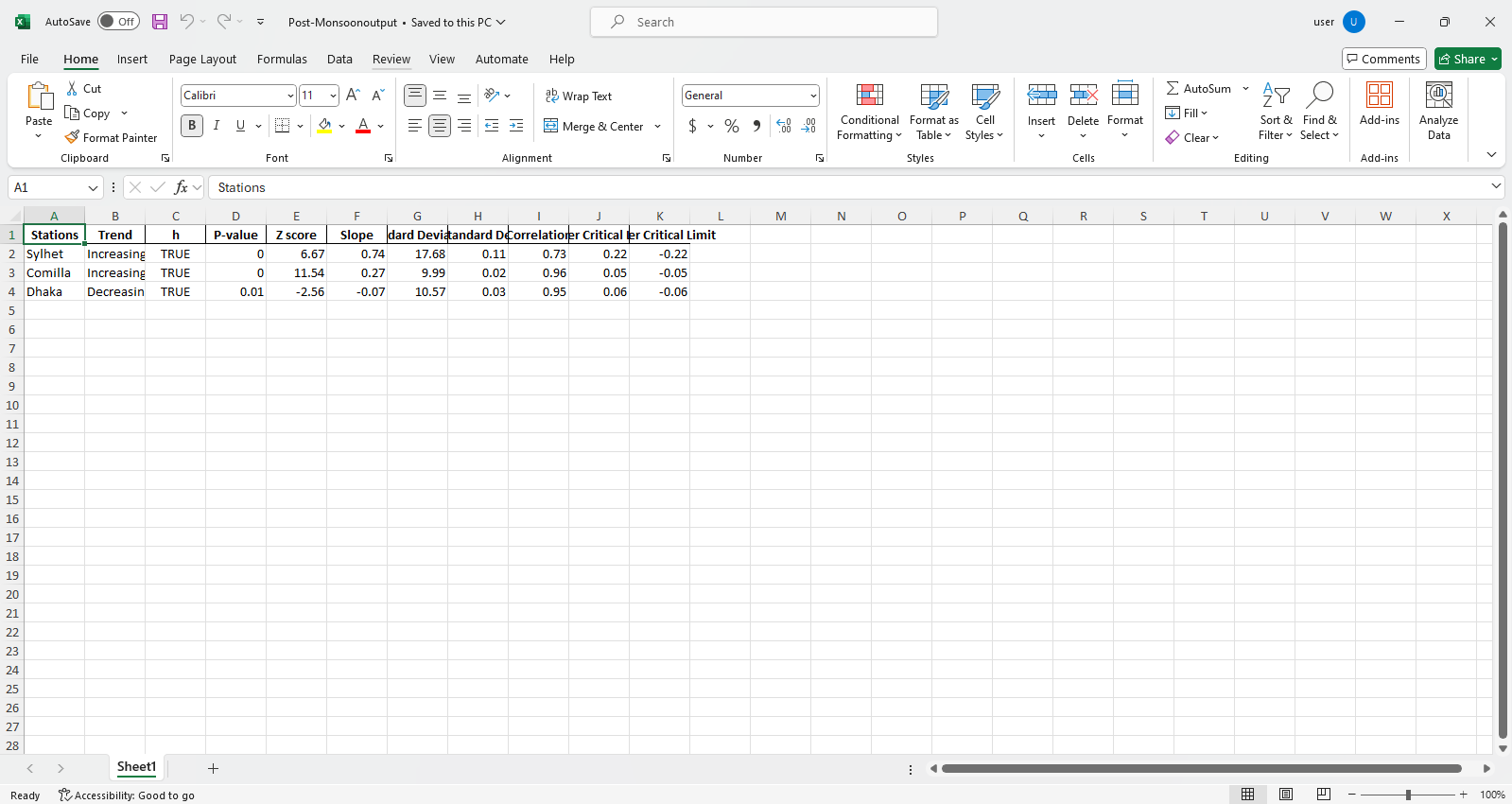 Muestra de figura
Muestra de figura 
pyinnovativetrend.ita_single_vis (x, longitud, figsize = (10,10), gráfico = {})
Esta función ilustra un gráfico y guarda en la máquina local.
Ejemplo:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single_vis(x, 12, graph = graph)
Producción:
pyinnovativetrend.ita_multiple_vis_by_station (longitud, gráfico = {}, filename = [], column = [], exceptocolumn = [], csv = false, directorio_path = "./")
Esta función ilustra múltiples gráficos ordenados por estaciones y guarda en la máquina local en el directorio deseado o el directorio raíz. Los datos se recuperan de los archivos Excel o CSV de un directorio deseado o raíz y los resultados se guardan como formato de Excel ordenado por las estaciones en el directorio deseado o raíz. Ejemplo:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
Producción:
pyinnovativetrend.ita_multiple_vis_by_column (longitud, gráfico = {}, filename = [], column = [], exceptocolumn = [], csv = false, directorio_path = "./")
Esta función ilustra múltiples gráficos ordenados por estaciones y guarda en la máquina local en el directorio deseado o el directorio raíz. Los datos se recuperan de los archivos Excel o CSV de un directorio deseado o raíz y los resultados se guardan como formato de Excel ordenado por columnas en el directorio deseado o raíz. Ejemplo:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
Producción:
X: lista o matriz numpy
La serie de tiempo o la serie de datos cuya tendencia se debe determinar
Longitud: entero
Longitud de la serie temporal. Si se administra la longitud de la serie temporal es extraña, la primera/primera entrada se omitirá.
nombre de archivo: lista predeterminada todos los archivos Excel/CSV
Lista de archivos o estaciones que contienen los datos ordenados por mes/año/temporada.
columna: lista predeterminada todas las columnas
Lista de columnas o series de datos que contienen los datos.
Excepto COMUMN: Lista de la lista vacía predeterminada
Lista de columnas para las cuales no se requiere análisis (por ejemplo, columna de año).
CSV: bool predeterminado falso el tipo de archivos. Por defecto, el tipo de archivo es Excel. Sin embargo, si los archivos están en formato CSV, CSV debe asignarse a True.
directorio_path: string root predeterminado
Ruta de directorio de los archivos donde se almacenan los archivos.
Salida: enumere los nombres de la estación o los nombres de columna predeterminados
Nombre de los archivos por los cuales se guardarán los resultados.
out_direc: string root predeterminado
Ruta de directorio de los archivos donde se guardarán los resultados.
alfa: float predeterminado 0.05
Nivel de importancia en una prueba de dos colas.
showgraph: bool predeterminado verdadero
Elija si se debe ilustrar el gráfico junto con el cálculo en un análisis único.
Gráfico: Python Dictionary (Opcional) Valores predeterminados 'TrendLinestyle': 'Dable' # Línea de línea de línea de tendencia, para obtener más estilo de estilo de línea, visite la documentación de Matplotlib
'Scattermarker': '.' # Tipo de marcador de puntos de datos dispersos, para obtener más marcador, visite la documentación de Matplotlib
'Título': '' # Título del gráfico o ilustración
'xlabel': 'Primera sub-series' # etiqueta del eje X
'Ylabel': 'Segunda sub-series' # etiqueta del eje Y
'norendlinestyle': 'sólido' # estilo de línea sin línea de tendencia o línea 1: 1, para obtener más estilo de estilo de línea documentación de matplotlib
'output_dir': './' # Directorio del archivo de salida donde se va a guardar el gráfico
'output_name': 'outputfig.png' # nombre del gráfico o ilustración
'DPI': 300 # punto por pulgada (DPI) del gráfico o ilustración
'fila': - # número de fila de las subtramas. Si no se proporciona, se calculará automáticamente. (Disponible solo para análisis múltiple)
'colm': - # número de columna de las subtramas. Si no se proporciona, se calculará automáticamente. (Disponible solo para análisis múltiple)
tendencia:
Dice si existe tendencia y tipo de tendencia
H:
Verdadero (si la tendencia está presente) y falso (si la tendencia está ausente)
pag:
Valor P para la prueba significativa (prueba de 2 colas)
Z:
Estadísticas de prueba normalizadas (prueba de 2 colas)
pendiente:
Pendiente de la tendencia
Standard_Deviation:
Desviación estándar de la serie de datos
slope_standard_deviation:
Desviación estándar de la correlación de la pendiente:
Correlación entre la sub-serie ordenada
Lower_Critical_Level:
Valor crítico más bajo para la prueba de 2 colas
superior_critical_level:
Valor crítico superior para la prueba de 2 colas


