pyinnovativetrend
1.0.0
トレンド分析は、特定の方向のパターン、トレンド、または動きを特定するために時間の経過とともにデータを調べるために使用される統計的手法です。金融、経済学、マーケティング、環境科学などのさまざまな分野で広く使用されています。トレンドを検出するための非常に一般的で従来の方法は、MannとKendallが提案したMann-Kendallトレンドテストです。ただし、SEN(2012)が提案した革新的な方法は、そのシンプルさとグラフィカルな特徴のために現在広く使用されています。この革新的なトレンド分析方法は非常に敏感であり、MKテストなどの従来の方法で見落とされている傾向を検出できます。
パッケージはPIPを使用してインストールされています:
pip install pyinnovativetrend
pyinnovativetrend.ita_single(x、length、alpha = 0.05、graph = {}、showgraph = true)
この関数は、単一リストまたはnumpy配列にトレンドとその他の必要なパラメーターを計算し、名前付きタプルを返します。デフォルトでは、グラフが図になり、ローカルマシンに保存されます。
例:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
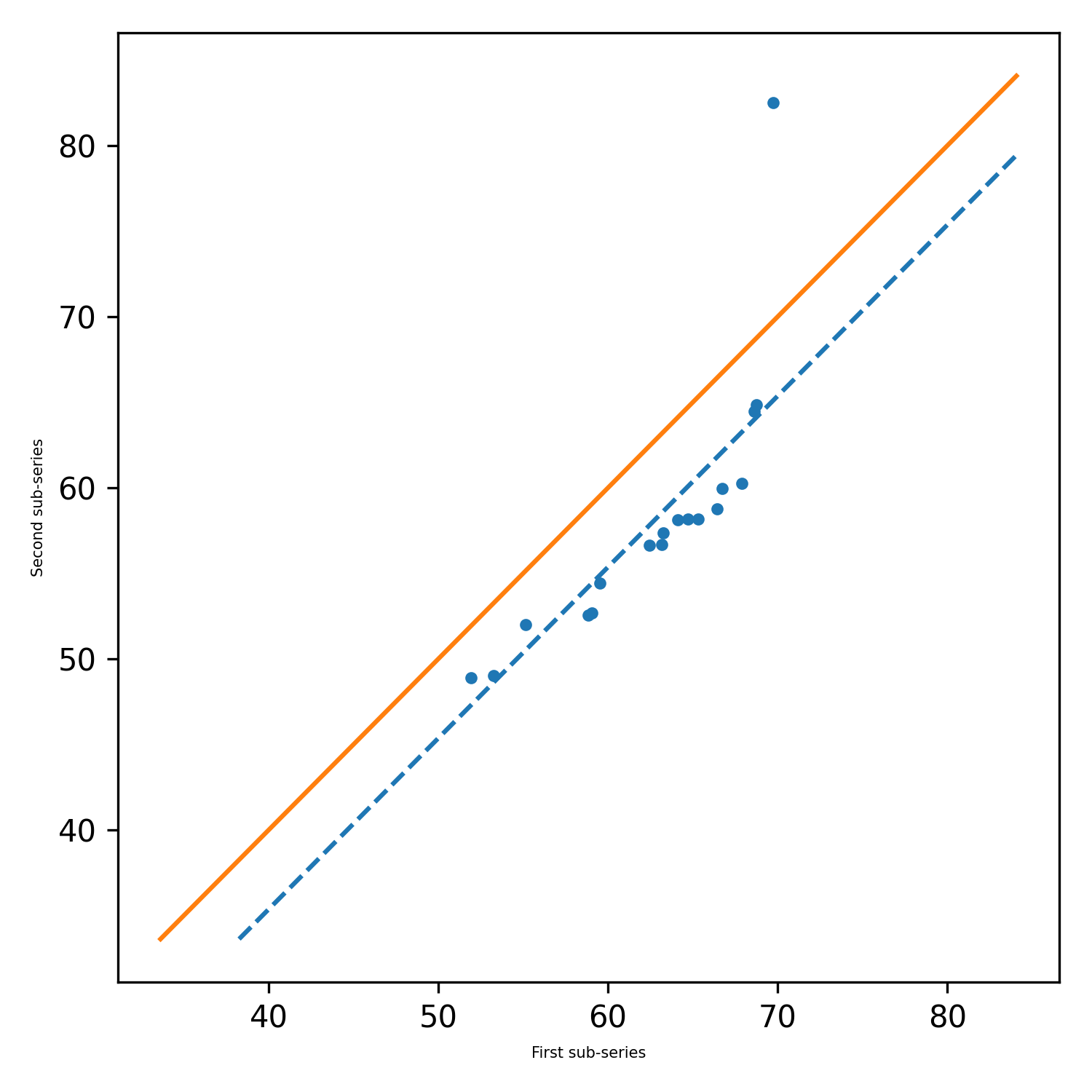
pit.ITA_single(x, 12, graph = graph)
出力:ita(trend = 'no trend'、h = false、p = 0.2049477839420626、z = -1.26758054282826508、勾配= -0.0277777777777777777752、標準_eviation slope_standard_deviation = 0.021914014011770254、相関= 0.934198732938274、lower_critical_level = -0.0429506782197758、uper_critical_level = 0.042950678219758
ITA_MULTIPLE_BY_STATIAN(length、filename = []、column = []、を除き、column = []、graph = {}、alpha = 0.05、rnd = 2、csv = false、directory_path = "./"、output = []、out_direc = "./"))
この関数は、複数のステーションの傾向とその他の必要なパラメーターを計算します。データは、目的のディレクトリまたはルートディレクトリからExcelまたはCSVファイルから取得され、結果は希望またはルートディレクトリのステーションでソートされたExcel形式として保存されます。デフォルトでは、ステーションでソートされた複数のグラフが図解され、目的のディレクトリまたはルートディレクトリ上のローカルマシンに保存されます。
例:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_station(38, exceptcolumn=['Year'], graph = graph)
出力:
Excelファイルサンプル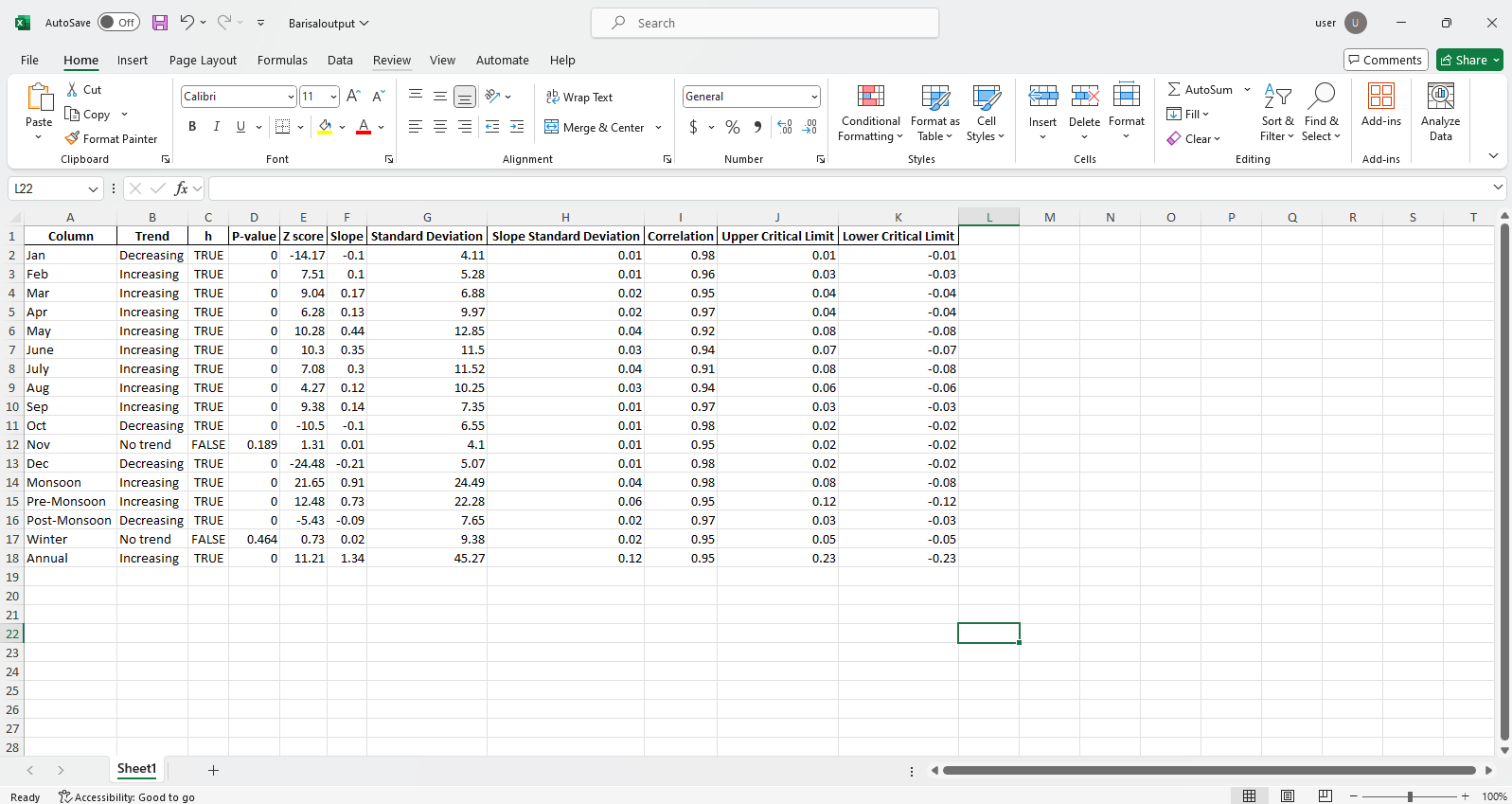 図サンプル
図サンプル
pyinnovativetrend.ita_multiple_by_station(length、filename = []、column = []、column = []、graph = {}、alpha = 0.05、rnd = 2、csv = false、directory_path = "./"、output = []、outdirec = "./"。
この関数は、複数のステーションの傾向とその他の必要なパラメーターを計算します。データは、目的のディレクトリまたはルートディレクトリからExcelまたはCSVファイルから取得され、結果は希望またはルートディレクトリの列でソートされたExcel形式として保存されます。デフォルトでは、列でソートされた複数のグラフが図解され、希望のディレクトリまたはルートディレクトリ上のローカルマシンに保存されます。
例:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_by_column(38, exceptcolumn=['Year'], graph = graph)
出力:
Excelファイルサンプル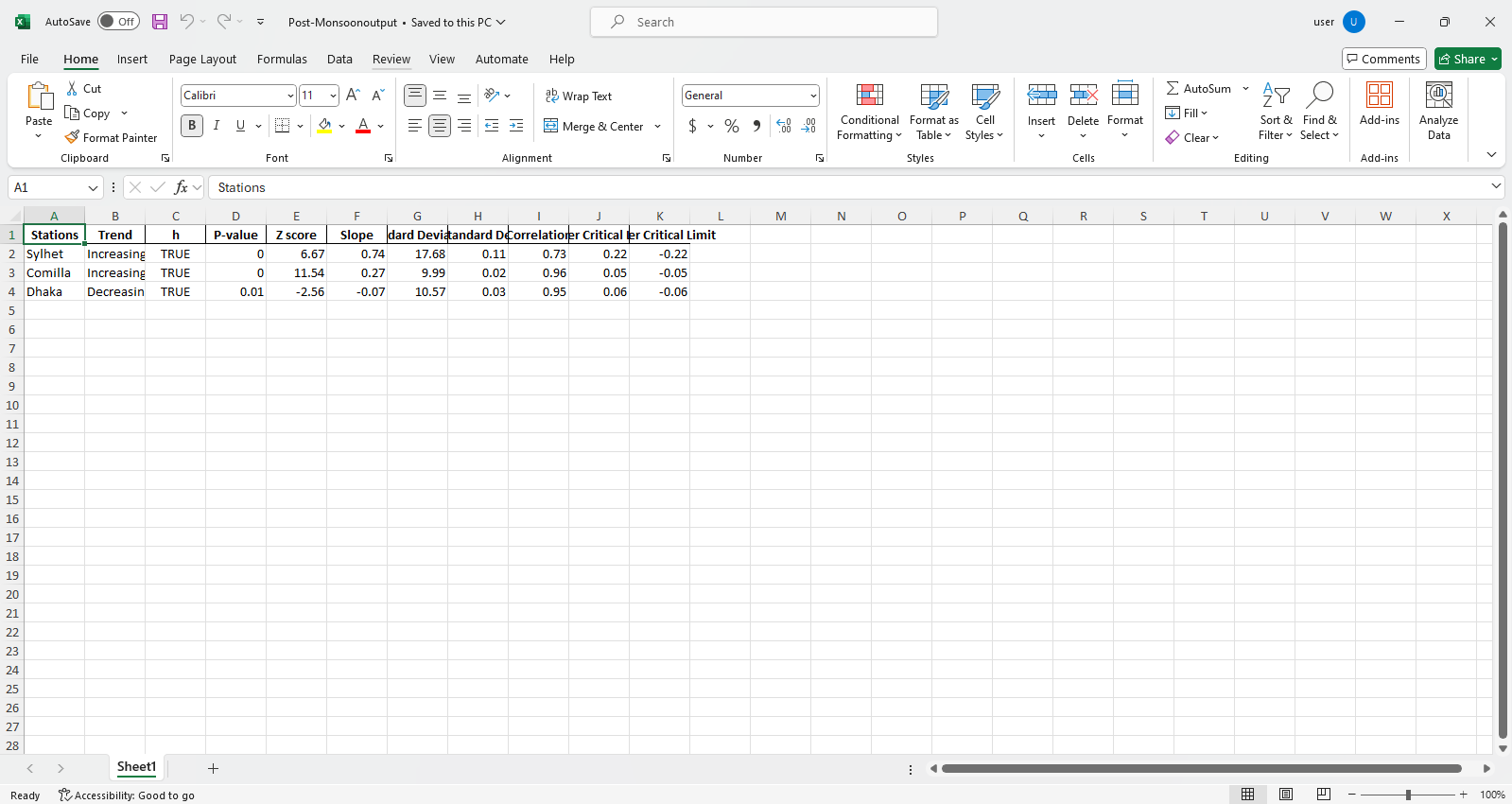 図サンプル
図サンプル
pyinnovativetrend.ita_single_vis(x、length、figsize =(10,10)、graph = {})
この関数はグラフを示し、ローカルマシンに保存します。
例:
import pyinnovativetrend as pit
x = [1,2,3,4,5,6,2,3,5,2,3,4,4]
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_single_vis(x, 12, graph = graph)
出力:
pyinnovativetrend.ita_multiple_vis_by_station(length、graph = {}、filename = []、column = []、Csv = false、false、directory_path = "./")
この関数は、ステーションでソートされた複数のグラフを示し、目的のディレクトリまたはルートディレクトリ上のローカルマシンに保存します。データは、目的のディレクトリまたはルートディレクトリからExcelまたはCSVファイルから取得され、結果は希望またはルートディレクトリのステーションでソートされたExcel形式として保存されます。例:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
出力:
pyinnovativetrend.ita_multiple_vis_by_column(length、graph = {}、filename = []、column = []、Csv = false、false、directory_path = "./")
この関数は、ステーションでソートされた複数のグラフを示し、目的のディレクトリまたはルートディレクトリ上のローカルマシンに保存します。データは、目的のディレクトリまたはルートディレクトリからExcelまたはCSVファイルから取得され、結果は希望またはルートディレクトリの列でソートされたExcel形式として保存されます。例:
import pyinnovativetrend as pit
graph ={
'xlabel' : 'First sub-series (1980 - 1985)',
'ylabel' : 'Second sub-series (1986 - 1991)',
'title' : 'Time series analysis',
'dpi' : 450,
'fontsize' : 10
}
pit.ITA_multiple_vis_by_stations(38, exceptcolumn=['Year'], graph = graph)
出力:
X:リストまたはnumpy配列
傾向が決定される時系列またはデータシリーズ
長さ:整数
時系列の長さ。時系列の長さが奇妙な場合、最も早い/最初のエントリがemmittedになります。
ファイル名:デフォルトのすべてのExcel/CSVファイルをリストします
月/年/季節ごとにソートされたデータを含むファイルまたはステーションのリスト。
列:デフォルトのすべての列をリストします
データを含む列またはデータシリーズのリスト。
コラムを除く:デフォルトの空のリストをリストします
分析が必要ない列のリスト(たとえば、年の列)。
CSV:ブールデフォルトFALSEファイルのタイプ。デフォルトでは、ファイルタイプはExcelです。ただし、ファイルがCSV形式である場合、CSVはTrueに割り当てる必要があります。
Directory_Path:文字列デフォルトルート
ファイルが保存されているファイルのディレクトリパス。
出力:デフォルトのステーション名または列名をリストします
結果が保存されるファイルの名前。
out_direc:文字列デフォルトルート
結果が保存されるファイルのディレクトリパス。
アルファ:フロートデフォルト0.05
両側テストでの有意水準。
showgraph:bool default true
単一の分析での計算とともにグラフを図解するかどうかを選択します。
グラフ:Python Dictionary(オプション)デフォルト値'TrendLinestyle': 'Dashed'#ラインスタイルのトレンドライン。
'Spattermarker': '。' #マーカーのタイプ散乱データポイント、より多くのマーカーのためにMatplotlibのドキュメントにアクセスする
「タイトル」: ''#グラフまたはイラストのタイトル
'xlabel': '最初のサブシリーズ'#x軸のラベル
'ylabel': '2番目のサブシリーズ'#y軸のラベル
「NotRendLinestyle」:「SOLID」#トレンドラインまたは1:1のラインのラインスタイル、より多くのラインスタイルタイプのMatplotlibのドキュメントをご覧ください
'output_dir': './'#グラフが保存する出力ファイルのディレクトリ
'output_name': 'outputfig.png'#グラフまたはイラストの名前
「DPI」:グラフまたはイラストのインチあたり300#ドット(DPI)
'row': - #列のサブプロットの番号。提供されていない場合、自動的に計算されます。 (複数の分析でのみ利用可能)
'colm': - #サブプロットの列番号。提供されていない場合、自動的に計算されます。 (複数の分析でのみ利用可能)
傾向:
トレンドが存在するかどうか、トレンドの種類を伝えます
H:
true(トレンドが存在する場合)および偽(トレンドがない場合)
P:
重要なテストのP値(2テールテスト)
Z:
正規化されたテスト統計(2テールテスト)
スロープ:
トレンドの勾配
Standard_Deviation:
データ系列の標準偏差
slope_standard_deviation:
勾配相関の標準偏差:
ソートされたサブシリーズ間の相関
lower_critical_level:
2テールテストの臨界値が低い
apper_critical_level:
2テールテストの上部臨界値


