Multilingual_Text_to_Speech
1.0.0
交互式合成演示
帶有樣品的網站
紙張和描述
該存儲庫提供綜合樣本,培訓和評估數據,源代碼和參數的紙張模型,許多語言:用於多語言文本到語音的元學習。
它包含TACOTRON 2的實現,該實現支持多語言實驗,並實現了不同的編碼參數共享方法。它提出了一個模型,結合了學習的想法,以一種外語說話:多語言語音綜合和跨語言語音克隆,端到端代碼轉換的TT與單語錄音的混合在一起,以及用於通用神經機器翻譯的上下文參數生成。
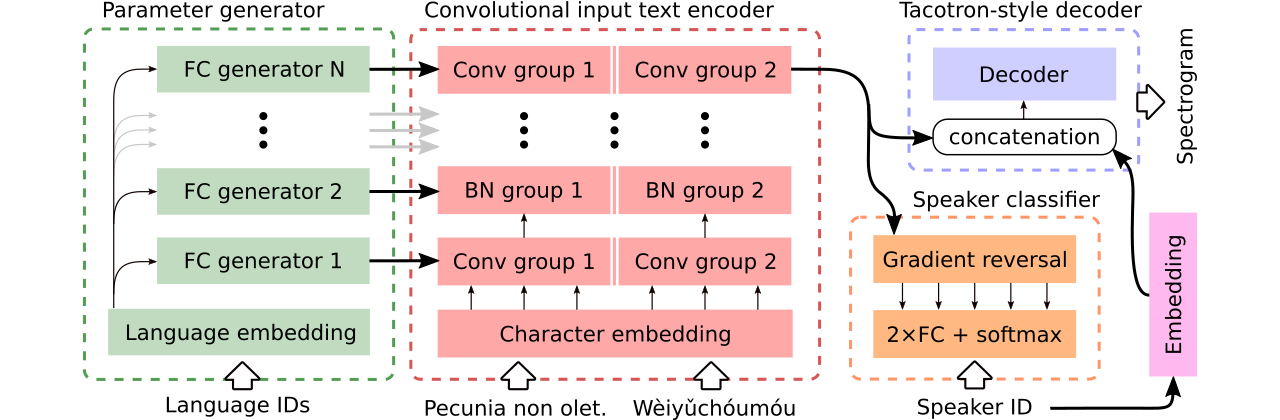
我們提供數據以比較三種多語言文本到語音模型。第一個共享整個編碼器,並使用對抗分類器從編碼器中刪除依賴說話者的信息。第二個具有每種語言的單獨編碼器。最後,第三個是我們嘗試結合以前兩種方法中最好的最好的方法,即第一種方法的有效參數共享和第二種方法的靈活性。它具有一個完全卷積編碼器,該編碼器具有由參數生成器生成的語言特定參數。它還利用遵循域對抗訓練的原理的對抗揚聲器分類器。請參閱上面的插圖。
交互式演示分別在此處和此處都提供了介紹代碼轉換能力和生成模型的聯合多語言培訓(在增強的CSS10數據集上進行了培訓)。
使用三個比較模型合成的許多樣本都在此網站上。它還包含一些由Griffin-Lim Vocoder(我們實施的理智檢查)訓練LJ演講的單語言Tacotron合成的樣品。
我們可以在此處下載我們最佳的模型支持代碼轉換或語音關閉的模型,並且在整個CSS10數據集中訓練的最佳模型,而無需雄心勃勃地進行語音關注。
現在,我們將展示如何進行多語言Tacotron的培訓。我們使用了基於Wavernn模型的Vocoder,有關更多詳細信息,請參見此存儲庫,或使用我們的預訓練模型。
git clone https://github.com/Tomiinek/Multilingual_Text_to_Speech.git
cd Multilingual_Text_to_Speech
pip3 install -r requirements.txt
下載CSS10數據集(Apache License 2.0)和我們清潔的通用語音數據(Creative Commons CC0)。
cd /project_root/data/css10
訪問CSS10存儲庫,並下載所有語言的數據。提取下載的檔案。例如,對於法語,您應該看到以下文件夾結構:
data/css10/french/lesmis/
data/css10/french/lupincontresholme/
data/css10/french/transcript.txt
接下來,下載我們清潔的通用語音數據集:
cd /project_root/data/comvoi_clean
wget https://github.com/Tomiinek/Multilingual_Text_to_Speech/releases/download/v1.0/comvoi.zip
unzip -q comvoi.zip -d clean_comvoi
rm comvoi.zip
該存儲庫提供清潔的成績單和元文件,您已經下載了相應的.wav文件。但是,預先計算頻譜圖(加速訓練)很方便。鑑於此,您可以運行一個臨時腳本,該腳本將為您創建MEL和線性頻譜圖:
cd /project_root/data/
python3 prepare_css_spectrograms.py
您可以通過將TextToSpeechDataset.create_meta_file方法應用於原始下載和提取的數據(例如LJ語音,M-ailabs等,請參見dataset/loaders.py ),為其他數據集創建其他數據集的元文件,頻譜圖和音素化的成績單。請注意,然後需要將元文件拆分為train.txt和val.txt文件。
現在,我們可以進行培訓。請參閱帶有參數的詳盡描述的params/params.py文件。 params文件夾還包含準備好的參數配置(例如generated_switching.json ),用於整個CSS10數據集的多語言培訓,以及在數據集中訓練由COMSS10的通用語音和五種語言組成的數據集上的代碼轉換模型。
具有預定義配置的訓練(建議快速啟動),例如:
PYTHONIOENCODING=utf-8 python3 train.py --hyper_parameters generated_switching
請注意丟失的擴展名( .json )。
或使用默認參數(默認數據集為LJ語音):
PYTHONIOENCODING=utf-8 python3 train.py
默認情況下,將培訓日誌保存到logs目錄中。使用張板監視培訓:
tensorboard --logdir logs --port 6666 &
默認情況下,將檢查點保存到checkpoints目錄中。它們包含模型權重,參數,優化器狀態和調度程序的狀態。要從檢查點恢復培訓,請說名為checkpoints/CHECKPOINT-1 ,運行:
PYTHONIOENCODING=utf-8 python3 train.py --checkpoint CHECKPOINT-1
有關生成頻譜圖,請參見synthesize.py或Interactive Colab筆記本電腦(此處和此處)。使用CheckPoint checkpoints/CHECKPOINT-1示例調用,並使用Griffin-Lim算法保存合成的頻譜圖和相應的波形VOCOD:
echo "01|Dies ist ein Beispieltext.|00-fr|de" | python3 synthesize.py --checkpoint checkpoints/CHECKPOINT-1 --save_spec
我們使用了Wavernn模型進行錄音。您可以在整個CSS10數據集中下載預先訓練的Wavernn權重。有關使用的示例,請訪問我們的交互式演示(此處和此處)或此存儲庫。
請參閱此文件,以獲取有關包含的源代碼及其結構的更多詳細信息。
@inproceedings{Nekvinda2020,
author={Tomáš Nekvinda and Ondřej Dušek},
title={{One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={2972--2976},
doi={10.21437/Interspeech.2020-2679},
url={http://dx.doi.org/10.21437/Interspeech.2020-2679}
}


