Multilingual_Text_to_Speech
1.0.0
Demonstração de síntese interativa
Site com amostras
Artigo e descrição
Este repositório fornece amostras sintetizadas, dados de treinamento e avaliação, código-fonte e parâmetros para o modelo de papel um, muitos idiomas: meta-aprendizagem para o texto em fala multilíngue .
Ele contém uma implementação do Tacotron 2 que suporta experimentos multilíngues e que implementa diferentes abordagens ao compartilhamento de parâmetros do codificador . Apresenta um modelo que combina idéias de aprender a falar fluentemente em uma língua estrangeira: síntese multilíngue de fala e clonagem de voz entre linguagem, TTS de ponta a ponta com mixagem de gravações monolíngues e geração contextual de parâmetros para tradução universal da máquina neural.
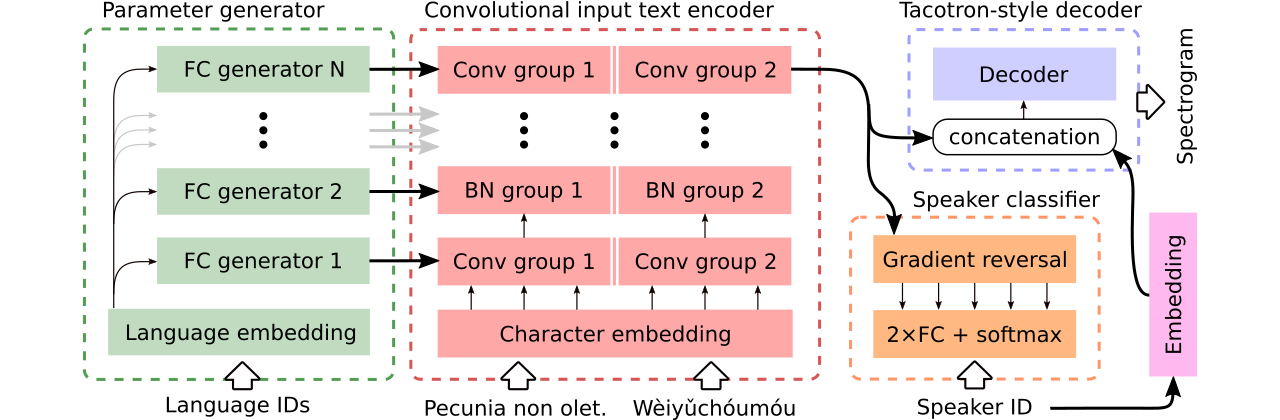
Fornecemos dados para comparação de três modelos multilíngues de texto em fala . O primeiro compartilha todo o codificador e usa um classificador adversário para remover informações dependentes do alto-falante do codificador. O segundo possui codificadores separados para cada idioma. Finalmente, o terceiro é a nossa tentativa de combinar o melhor das duas abordagens anteriores, ou seja, compartilhamento eficaz de parâmetros do primeiro método e flexibilidade do segundo. Possui um codificador totalmente convolucional com parâmetros específicos da linguagem gerados por um gerador de parâmetros . Também utiliza um classificador de alto -falante adversário que segue os princípios do treinamento adversário de domínio. Veja a ilustração acima.
Demonstrações interativas que introduzem habilidades de troca de código e treinamento multilíngue conjunto do modelo gerado (treinado em um conjunto de dados CSS10 aprimorado) estão disponíveis aqui e aqui, respectivamente.
Muitas amostras sintetizadas usando os três modelos em comparação estão neste site. Ele também contém algumas amostras sintetizadas por um tacotron de baunilha monolíngue treinado no discurso de LJ com o vocoder de Griffin-Lim (uma verificação de sanidade de nossa implementação).
Nosso melhor modelo que suporta a troca de código ou a clonagem de voz pode ser baixado aqui e o melhor modelo treinado no conjunto de dados CSS10 inteiro sem a ambição de fazer a clonagem de voz está disponível aqui.
Agora vamos mostrar como executar o treinamento de nosso tacotron multilíngue. Usamos um vocoder baseado no modelo Wavernn, consulte este repositório para obter mais detalhes ou usar nosso modelo pré-treinado.
git clone https://github.com/Tomiinek/Multilingual_Text_to_Speech.git
cd Multilingual_Text_to_Speech
pip3 install -r requirements.txt
Faça o download do conjunto de dados CSS10 (Licença Apache 2.0) e nossos dados de voz comuns limpos (Creative Commons CC0).
cd /project_root/data/css10
Visite o repositório CSS10 e faça o download de dados para todos os idiomas. Extraia os arquivos baixados. Por exemplo, no caso do francês, você deve ver a seguinte estrutura de pastas:
data/css10/french/lesmis/
data/css10/french/lupincontresholme/
data/css10/french/transcript.txt
Em seguida, baixe nosso conjunto de dados de voz comum limpo:
cd /project_root/data/comvoi_clean
wget https://github.com/Tomiinek/Multilingual_Text_to_Speech/releases/download/v1.0/comvoi.zip
unzip -q comvoi.zip -d clean_comvoi
rm comvoi.zip
Este repositório fornece transcrições e meta-arquivos limpos e você já baixou os arquivos .wav correspondentes. No entanto, é útil pré -computar espectrogramas (acelera o treinamento). Em vista disso, você pode executar um script ad-hoc que criará espectrogramas MEL e lineares para você:
cd /project_root/data/
python3 prepare_css_spectrograms.py
Você pode criar o meta-arquivo, espectrogramas e transcritos fonemicizados para outros conjuntos de dados aplicando o método TextToSpeechDataset.create_meta_file aos dados baixados e extraídos originais (como discursos LJ, M-Aailabs, etc., consulte dataset/loaders.py para dados apoiados). Observe que é necessário dividir o meta-arquivo em arquivos train.txt e val.txt .
Agora, podemos executar treinamento. Consulte o arquivo params/params.py com uma descrição exaustiva dos parâmetros. A pasta params também contém configurações de parâmetros preparados (como generated_switching.json ) para treinamento multilíngue no conjunto de dados CSS10 e para o treinamento de modelos de troca de código no conjunto de dados que consiste em voz comum limpa e cinco idiomas do CSS10.
Treine com configurações predefinidas (recomendado para início rápido), por exemplo:
PYTHONIOENCODING=utf-8 python3 train.py --hyper_parameters generated_switching
Observe a extensão ausente ( .json ).
Ou com parâmetros padrão (o conjunto de dados padrão é o discurso LJ):
PYTHONIOENCODING=utf-8 python3 train.py
Por padrão, os registros de treinamento são salvos no diretório logs . Use o Tensorboard para monitorar o treinamento:
tensorboard --logdir logs --port 6666 &
Os pontos de verificação são salvos no diretório checkpoints por padrão. Eles contêm pesos do modelo, parâmetros, o estado do otimizador e o estado do agendador. Para restaurar o treinamento do ponto de verificação, digamos que checkpoints/CHECKPOINT-1 , executem:
PYTHONIOENCODING=utf-8 python3 train.py --checkpoint CHECKPOINT-1
Para gerar espectrogramas, consulte synthesize.py ou notebooks colab interativos (aqui e aqui). Um exemplo de chamada que usa um checkpoints/CHECKPOINT-1 e salva o espectrograma sintetizado e a forma de onda correspondente vocodificada usando o algoritmo Griffin-Lim:
echo "01|Dies ist ein Beispieltext.|00-fr|de" | python3 synthesize.py --checkpoint checkpoints/CHECKPOINT-1 --save_spec
Usamos o modelo wavernn para vocoding. Você pode baixar pesos wavernn pré-treinados em todo o conjunto de dados CSS10. Para exemplos de uso, visite nossas demonstrações interativas (aqui e aqui) ou este repositório.
Consulte este arquivo para obter mais detalhes sobre o código de origem contido e sua estrutura.
@inproceedings{Nekvinda2020,
author={Tomáš Nekvinda and Ondřej Dušek},
title={{One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={2972--2976},
doi={10.21437/Interspeech.2020-2679},
url={http://dx.doi.org/10.21437/Interspeech.2020-2679}
}


