Multilingual_Text_to_Speech
1.0.0
Demo sintesis interaktif
Situs web dengan sampel
Kertas & Deskripsi
Repositori ini menyediakan sampel yang disintesis, data pelatihan dan evaluasi, kode sumber, dan parameter untuk model satu model, banyak bahasa: pembelajaran meta untuk teks-ke-speech multibahasa .
Ini berisi implementasi Tacotron 2 yang mendukung eksperimen multibahasa dan yang mengimplementasikan pendekatan yang berbeda untuk berbagi parameter enkoder . Ini menyajikan model yang menggabungkan ide-ide dari belajar untuk berbicara dengan lancar dalam bahasa asing: sintesis ucapan multibahasa dan kloning suara lintas-bahasa, TTS-end-end-end-end-end-endchitched dengan campuran rekaman monolingual, dan generasi parameter kontekstual untuk terjemahan mesin saraf universal.
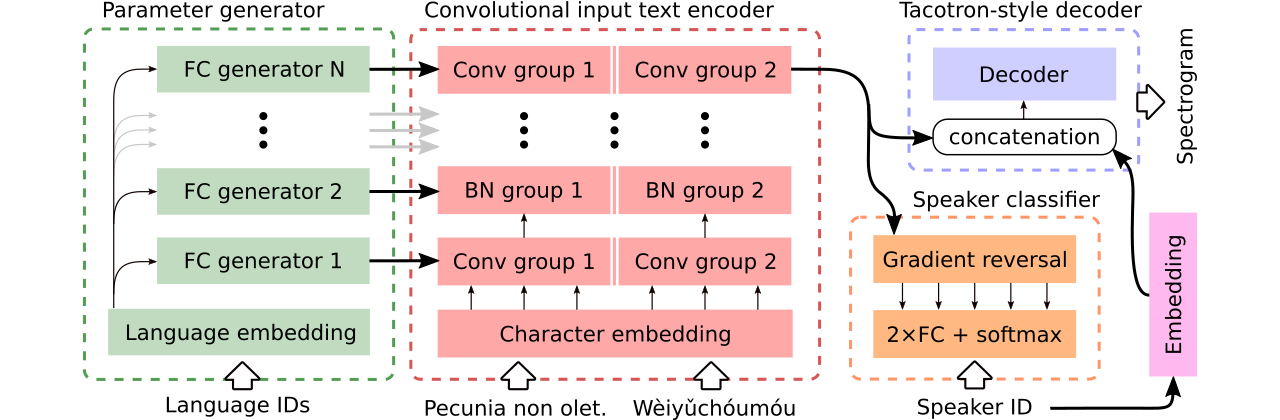
Kami menyediakan data untuk perbandingan tiga model teks-dengan-speech multibahasa . Yang pertama membagikan seluruh enkoder dan menggunakan classifier permusuhan untuk menghapus informasi yang bergantung pada pembicara dari enkoder. Yang kedua memiliki encoder terpisah untuk setiap bahasa. Akhirnya, yang ketiga adalah upaya kami untuk menggabungkan yang terbaik dari kedua pendekatan sebelumnya, yaitu, berbagi parameter yang efektif dari metode pertama dan fleksibilitas yang kedua. Ini memiliki enkoder konvolusional sepenuhnya dengan parameter spesifik bahasa yang dihasilkan oleh generator parameter . Ini juga memanfaatkan classifier pembicara permusuhan yang mengikuti prinsip -prinsip pelatihan permusuhan domain. Lihat ilustrasi di atas.
Demo interaktif memperkenalkan kemampuan pengalihan kode dan pelatihan multibahasa bersama dari model yang dihasilkan (dilatih pada dataset CSS10 yang ditingkatkan) tersedia di sini dan di sini, masing-masing.
Banyak sampel yang disintesis menggunakan tiga model yang dibandingkan ada di situs web ini. Ini juga berisi beberapa sampel yang disintesis oleh vanilla tacotron monolingual yang dilatih pada pidato LJ dengan Vocoder Griffin-Lim (pemeriksaan kewarasan implementasi kami).
Model terbaik kami mendukung pengalihan kode atau kloning suara dapat diunduh di sini dan model terbaik yang dilatih pada seluruh dataset CSS10 tanpa ambisi untuk melakukan kloning suara tersedia di sini.
Kami sekarang akan menunjukkan cara menjalankan pelatihan tacotron multibahasa kami. Kami menggunakan vocoder yang didasarkan pada model Wavernn, lihat repositori ini untuk detail lebih lanjut, atau menggunakan model pra-terlatih kami.
git clone https://github.com/Tomiinek/Multilingual_Text_to_Speech.git
cd Multilingual_Text_to_Speech
pip3 install -r requirements.txt
Unduh dataset CSS10 (Lisensi Apache 2.0) dan data suara umum kami yang dibersihkan (Creative Commons CC0).
cd /project_root/data/css10
Kunjungi repositori CSS10 dan unduh data untuk semua bahasa. Ekstrak arsip yang diunduh. Misalnya, dalam kasus Prancis, Anda akan melihat struktur folder berikut:
data/css10/french/lesmis/
data/css10/french/lupincontresholme/
data/css10/french/transcript.txt
Selanjutnya, unduh dataset suara umum yang dibersihkan kami:
cd /project_root/data/comvoi_clean
wget https://github.com/Tomiinek/Multilingual_Text_to_Speech/releases/download/v1.0/comvoi.zip
unzip -q comvoi.zip -d clean_comvoi
rm comvoi.zip
Repositori ini menyediakan transkrip yang dibersihkan dan file meta dan Anda telah mengunduh file .wav yang sesuai. Namun, ini berguna untuk mengukuhkan spektrogram (ini mempercepat pelatihan). Mengingat hal itu, Anda dapat menjalankan skrip ad-hoc yang akan membuat spektrogram Mel dan linear untuk Anda:
cd /project_root/data/
python3 prepare_css_spectrograms.py
Anda dapat membuat meta-file, spektrogram, dan transkrip fonemik untuk set data lainnya dengan menerapkan metode TextToSpeechDataset.create_meta_file ke data asli yang diunduh dan diekstraksi (seperti LJ Speech, M-ADABS, dll., Lihat dataset/loaders.py untuk dataset yang didukung). Perhatikan bahwa kemudian diperlukan untuk membagi file meta menjadi file train.txt dan val.txt .
Sekarang, kita bisa menjalankan pelatihan. Lihat file params/params.py dengan deskripsi parameter yang lengkap. Folder params juga berisi konfigurasi parameter yang disiapkan (seperti generated_switching.json ) untuk pelatihan multibahasa pada seluruh dataset CSS10 dan untuk pelatihan model pengalihan kode pada dataset yang terdiri dari suara umum yang dibersihkan dan lima bahasa CSS10.
Latih dengan konfigurasi yang telah ditentukan (disarankan untuk memulai cepat), misalnya:
PYTHONIOENCODING=utf-8 python3 train.py --hyper_parameters generated_switching
Harap dicatat ekstensi yang hilang ( .json ).
Atau dengan parameter default (dataset default adalah lj wicara):
PYTHONIOENCODING=utf-8 python3 train.py
Secara default, log pelatihan disimpan ke direktori logs . Gunakan Tensorboard untuk memantau pelatihan:
tensorboard --logdir logs --port 6666 &
Pos pemeriksaan disimpan ke direktori checkpoints secara default. Mereka berisi bobot model, parameter, status pengoptimal, dan keadaan penjadwal. Untuk memulihkan pelatihan dari pos pemeriksaan, katakanlah bernama checkpoints/CHECKPOINT-1 , jalankan:
PYTHONIOENCODING=utf-8 python3 train.py --checkpoint CHECKPOINT-1
Untuk menghasilkan spektrogram, lihat synthesize.py atau notebook Colab interaktif (di sini dan di sini). Contoh panggilan yang menggunakan checkpoints/CHECKPOINT-1 dan yang menyimpan kedua spektrogram yang disintesis dan bentuk gelombang yang sesuai yang dipilih menggunakan algoritma Griffin-Lim:
echo "01|Dies ist ein Beispieltext.|00-fr|de" | python3 synthesize.py --checkpoint checkpoints/CHECKPOINT-1 --save_spec
Kami menggunakan model Wavernn untuk vokoding. Anda dapat mengunduh bobot Wavernn yang sudah dilatih sebelumnya di seluruh dataset CSS10. Untuk contoh penggunaan, kunjungi demo interaktif kami (di sini dan di sini) atau repositori ini.
Tolong, lihat file ini untuk detail lebih lanjut tentang kode sumber yang terkandung dan strukturnya.
@inproceedings{Nekvinda2020,
author={Tomáš Nekvinda and Ondřej Dušek},
title={{One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={2972--2976},
doi={10.21437/Interspeech.2020-2679},
url={http://dx.doi.org/10.21437/Interspeech.2020-2679}
}


