Multilingual_Text_to_Speech
1.0.0
Интерактивный синтез Демо
Веб -сайт с образцами
Бумага и описание
Этот репозиторий содержит синтезированные образцы, данные обучения и оценки, исходный код и параметры для статьи One Model, множество языков: мета-обучение для многоязычного текста в речь .
Он содержит реализацию Tacotron 2 , которая поддерживает многоязычные эксперименты и реализует различные подходы к обмену параметрами кодера . В нем представлена модель, объединяющая идеи от обучения, чтобы свободно говорить на иностранном языке: многоязычный синтез речи и клонирование голоса поперечного языка, сквозные кодовые TTS со смешиванием монолингальных записей и генерацию контекстуальных параметров для универсальной переводы нейронной машины.
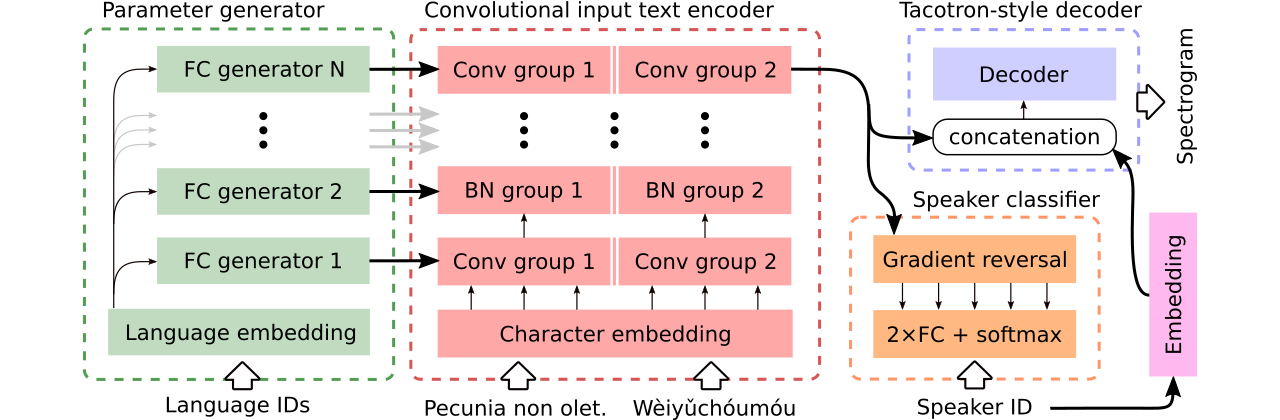
Мы предоставляем данные для сравнения трех многоязычных моделей текста в речь . Первый разделяет весь энкодер и использует состязательный классификатор для удаления зависимой от динамика информации из кодера. Второй имеет отдельные кодеры для каждого языка. Наконец, третьим является наша попытка объединить лучшие из обоих предыдущих подходов, то есть эффективное обмен параметров первого метода и гибкость второго. Он имеет полностью сверточный энкодер с языковыми параметрами, сгенерированными генератором параметров . Он также использует классификатор состязательного оратора, который следует за принципами доменного состязательного обучения. Смотрите иллюстрацию выше.
Интерактивные демонстрации, внедряющие способности к переключению кода и совместное многоязычное обучение сгенерированной модели (обученная на наборе данных CSS10) доступны здесь и здесь, соответственно.
Многие образцы, синтезированные с использованием трех сравниваемых моделей, находятся на этом веб -сайте. Он также содержит несколько образцов, синтезируемых одноязычным ванильным такотроном, обученным речи LJ с Griffin-Lim Vocoder (проверка здравомыслия нашей реализации).
Наша лучшая модель, поддерживающая переключение кода или голосовой клонирование, можно загрузить здесь, и лучшая модель, обученная цельному набору данных CSS10 без амбиций для выполнения голоса, доступна здесь.
Теперь мы собираемся показать, как провести обучение нашего многоязычного такотрона. Мы использовали Vocoder, который основан на модели Wavernn, см. Этот репозиторий для получения более подробной информации или используйте нашу предварительно обученную модель.
git clone https://github.com/Tomiinek/Multilingual_Text_to_Speech.git
cd Multilingual_Text_to_Speech
pip3 install -r requirements.txt
Загрузите набор данных CSS10 (Apache License 2.0) и наши Cleaned Common Voice Data (Creative Commons CC0).
cd /project_root/data/css10
Посетите данные CSS10 и загрузку данных для всех языков. Извлеките загруженные архивы. Например, в случае с французским вы должны увидеть следующую структуру папок:
data/css10/french/lesmis/
data/css10/french/lupincontresholme/
data/css10/french/transcript.txt
Далее загрузите наш набор данных Cleaned Common Voice:
cd /project_root/data/comvoi_clean
wget https://github.com/Tomiinek/Multilingual_Text_to_Speech/releases/download/v1.0/comvoi.zip
unzip -q comvoi.zip -d clean_comvoi
rm comvoi.zip
Этот репозиторий предоставляет очищенные транскрипты и мета-штучки, и вы уже загрузили соответствующие файлы .wav . Тем не менее, это удобно для предварительных выкомплектованных спектрограмм (это ускоряет тренировку). Ввиду этого вы можете запустить специальное сценарий, который создаст для вас MEL и линейные спектрограммы:
cd /project_root/data/
python3 prepare_css_spectrograms.py
Вы можете создавать мета-файлы, спектрограммы и фонемизированные транскрипты для других наборов данных, применяя метод TextToSpeechDataset.create_meta_file к исходным загруженным и извлеченным данным (например, речь LJ, M-ailabs и т. Д., См. dataset/loaders.py для поддерживаемых данных DataSets). Обратите внимание, что затем необходимо разделить мета-файл на файлы train.txt и val.txt .
Теперь мы можем провести обучение. См. Файл params/params.py с исчерпывающим описанием параметров. Папка params также содержит подготовленные конфигурации параметров (например, generated_switching.json ) для многоязычного обучения по всему набору данных CSS10 и для обучения моделей переключения кодов на наборе данных, который состоит из очищенного общего голоса и пяти языков CSS10.
Например, тренировка с предопределенными конфигурациями (рекомендуется для быстрого запуска):
PYTHONIOENCODING=utf-8 python3 train.py --hyper_parameters generated_switching
Обратите внимание на пропущенное расширение ( .json ).
Или с параметрами по умолчанию (набор данных по умолчанию - речь LJ):
PYTHONIOENCODING=utf-8 python3 train.py
По умолчанию журналы обучения сохраняются в каталоге logs . Используйте Tensorboard для мониторинга обучения:
tensorboard --logdir logs --port 6666 &
Контрольные точки сохраняются в каталоге checkpoints по умолчанию. Они содержат веса модели, параметры, состояние оптимизатора и состояние планировщика. Чтобы восстановить обучение с контрольной точки, скажем, с именем checkpoints/CHECKPOINT-1 запустите:
PYTHONIOENCODING=utf-8 python3 train.py --checkpoint CHECKPOINT-1
Для генерации спектрограмм см. synthesize.py или интерактивные ноутбуки Colab (здесь и здесь). Пример вызова, в котором используется контрольная точка контрольной checkpoints/CHECKPOINT-1 и сохраняет как синтезированную спектрограмму, так и соответствующую воканут формы сигнала с использованием алгоритма Griffin-Lim:
echo "01|Dies ist ein Beispieltext.|00-fr|de" | python3 synthesize.py --checkpoint checkpoints/CHECKPOINT-1 --save_spec
Мы использовали модель Wavernn для вокана. Вы можете скачать Wavernn Weights, предварительно обученные в целом наборе данных CSS10. Для примеров использования посетите наши интерактивные демонстрации (здесь и здесь) или этот репозиторий.
Пожалуйста, посмотрите этот файл для получения более подробной информации о содержащемся исходном коде и его структуре.
@inproceedings{Nekvinda2020,
author={Tomáš Nekvinda and Ondřej Dušek},
title={{One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={2972--2976},
doi={10.21437/Interspeech.2020-2679},
url={http://dx.doi.org/10.21437/Interspeech.2020-2679}
}


