Multilingual_Text_to_Speech
1.0.0
インタラクティブな合成デモ
サンプル付きのウェブサイト
紙と説明
このリポジトリは、合成されたサンプル、トレーニングおよび評価データ、ソースコード、およびペーパー1モデルのパラメーター、多言語テキストへのメタ学習の多くの言語を提供します。
多言語実験をサポートし、エンコーダーパラメーター共有にさまざまなアプローチを実装するタコトロン2の実装が含まれています。それは、多言語の音声合成と横断的な音声クローニング、単一言語録音の組み合わせと普遍的な神経機械翻訳のコンテキストパラメーター生成など、多言語の音声合成とクロス言語の音声クローニング、エンドツーエンドのコードスイッチングTTSなど、外国語で流fluentに話すことからのアイデアを組み合わせたモデルを提示します。
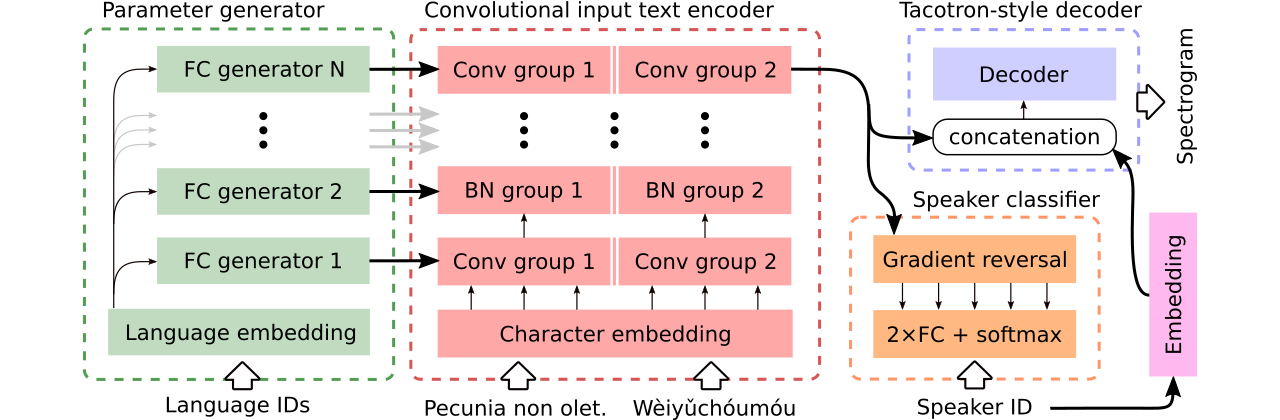
3つの多言語テキストからスピーチモデルの比較のためのデータを提供します。最初はエンコーダー全体を共有し、敵対的な分類器を使用して、エンコーダからスピーカー依存情報を削除します。 2番目には、各言語に個別のエンコーダーがあります。最後に、3番目は、以前のアプローチの両方の最良のアプローチ、すなわち、最初の方法の効果的なパラメーター共有と2番目の柔軟性を組み合わせようとする試みです。パラメータージェネレーターによって生成された言語固有のパラメーターを備えた完全に畳み込みのあるエンコーダーがあります。また、ドメインの敵対的訓練の原則に従う敵対的なスピーカー分類器を利用しています。上記の図を参照してください。
コードスイッチング能力を導入するインタラクティブなデモは、生成されたモデルの共同多言語トレーニング(強化されたCSS10データセットでトレーニングされています)をそれぞれこことここで入手できます。
このウェブサイトには、3つの比較モデルを使用して合成された多くのサンプルがあります。また、Griffin-Lim Vocoder(実装の正気チェック)でLJスピーチで訓練された単一言語のバニラタコトロンによって合成されたいくつかのサンプルも含まれています。
コードスイッチまたは音声クローニングをサポートする最良のモデルは、ここからダウンロードでき、ボイスクローニングを行うことなくCSS10データセット全体でトレーニングされた最良のモデルはこちらから入手できます。
現在、多言語のタコトロンのトレーニングを実行する方法を示します。 Wavernnモデルに基づいたボコーダーを使用しました。詳細については、このリポジトリを参照するか、事前に訓練されたモデルを使用します。
git clone https://github.com/Tomiinek/Multilingual_Text_to_Speech.git
cd Multilingual_Text_to_Speech
pip3 install -r requirements.txt
CSS10データセット(Apacheライセンス2.0)とクリーン化された共通音声データ(Creative Commons CC0)をダウンロードします。
cd /project_root/data/css10
CSS10リポジトリにアクセスし、すべての言語のデータをダウンロードします。ダウンロードしたアーカイブを抽出します。たとえば、フランス語の場合、次のフォルダー構造が表示されます。
data/css10/french/lesmis/
data/css10/french/lupincontresholme/
data/css10/french/transcript.txt
次に、クリーンな一般的な音声データセットをダウンロードしてください。
cd /project_root/data/comvoi_clean
wget https://github.com/Tomiinek/Multilingual_Text_to_Speech/releases/download/v1.0/comvoi.zip
unzip -q comvoi.zip -d clean_comvoi
rm comvoi.zip
このリポジトリは、クリーニングされたトランスクリプトとメタファイルを提供し、対応する.wavファイルを既にダウンロードしています。ただし、スペクトログラムを事前に計算するのが便利です(トレーニングをスピードアップします)。それを考慮して、あなたのためにMELと線形のスペクトログラムを作成するアドホックスクリプトを実行できます:
cd /project_root/data/
python3 prepare_css_spectrograms.py
TextToSpeechDataset.create_meta_fileメソッドを元のダウンロードおよび抽出されたデータに適用することにより、他のデータセットのメタファイル、スペクトログラム、および音素転写産物を作成できます(LJ Speech、M- dataset/loaders.pyなど。メタファイルをtrain.txtおよびval.txtファイルに分割する必要があることに注意してください。
これで、トレーニングを実行できます。パラメーターの徹底的な説明を含むparams/params.pyファイルを参照してください。 paramsフォルダーには、CSS10データセット全体での多言語トレーニング、およびCSS10の5つの言語で構成されるデータセットでのコードスイッチングモデルのトレーニングのための準備されたパラメーター構成( generated_switching.jsonなど)も含まれています。
事前定義された構成でトレーニング(クイックスタートに推奨)、例:
PYTHONIOENCODING=utf-8 python3 train.py --hyper_parameters generated_switching
欠落している拡張機能( .json )に注意してください。
またはデフォルトのパラメーターを使用します(デフォルトデータセットはLJスピーチです):
PYTHONIOENCODING=utf-8 python3 train.py
デフォルトでは、トレーニングログはlogsディレクトリに保存されます。テンソルボードを使用してトレーニングを監視します。
tensorboard --logdir logs --port 6666 &
チェックポイントは、デフォルトでcheckpointsディレクトリに保存されます。モデルの重み、パラメーター、オプティマイザー状態、およびスケジューラの状態が含まれています。チェックポイントからトレーニングを復元するには、名前が付けられたcheckpoints/CHECKPOINT-1 、実行してください。
PYTHONIOENCODING=utf-8 python3 train.py --checkpoint CHECKPOINT-1
スペクトログラムの生成については、 synthesize.pyまたはインタラクティブコラブノートブック(こちらとこちら)を参照してください。チェックポイントcheckpoints/CHECKPOINT-1使用し、合成されたスペクトログラムとGriffin-LIMアルゴリズムを使用してボコードされた対応する波形の両方を保存する例:コール:
echo "01|Dies ist ein Beispieltext.|00-fr|de" | python3 synthesize.py --checkpoint checkpoints/CHECKPOINT-1 --save_spec
ボコードにWavernnモデルを使用しました。 CSS10データセット全体で事前に訓練されたWavernnウェイトをダウンロードできます。使用の例については、インタラクティブなデモ(こちらとこちら)またはこのリポジトリをご覧ください。
含まれているソースコードとその構造の詳細については、このファイルを参照してください。
@inproceedings{Nekvinda2020,
author={Tomáš Nekvinda and Ondřej Dušek},
title={{One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={2972--2976},
doi={10.21437/Interspeech.2020-2679},
url={http://dx.doi.org/10.21437/Interspeech.2020-2679}
}


