Multilingual_Text_to_Speech
1.0.0
대화식 합성 데모
샘플이있는 웹 사이트
종이 및 설명
이 저장소는 종이 하나의 모델, 여러 언어 : 다국어 텍스트 음성 연사를위한 메타 학습 의 합성 된 샘플, 교육 및 평가 데이터, 소스 코드 및 매개 변수를 제공합니다.
여기에는 다국어 실험을 지원하고 인코더 파라미터 공유 에 대한 다양한 접근법을 구현하는 타코트론 2 의 구현이 포함되어 있습니다. 그것은 외국어로 유창하게 말하는 학습의 아이디어를 결합한 모델을 제시합니다. 다국어 음성 합성 및 교차 음성 복제, 단일 언어 녹음이 혼합 된 엔드 투 엔드 코드 스위치 TT 및 범용 신경 기계 번역을위한 상황에 맞는 매개 변수 생성.
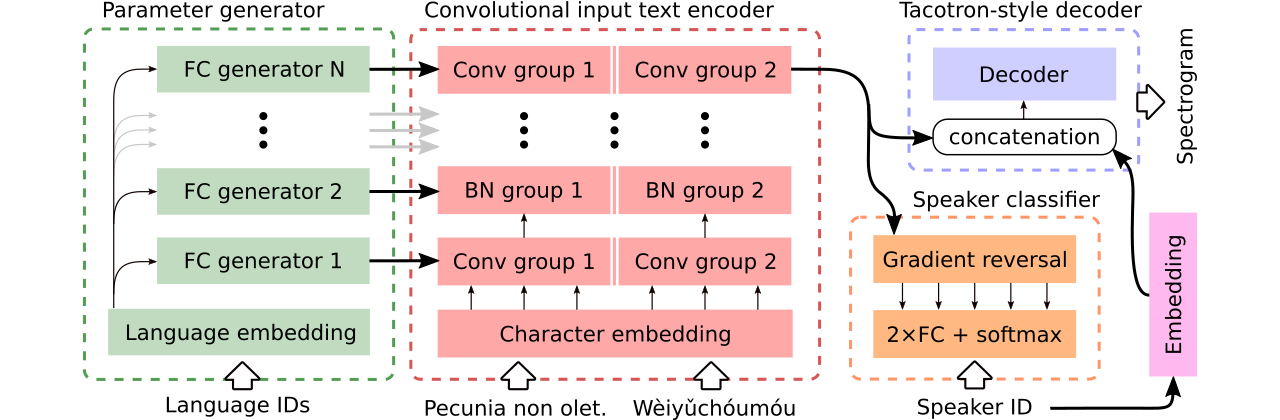
우리는 세 가지 다국어 텍스트 음성 연설 모델을 비교하기위한 데이터를 제공합니다. 첫 번째는 전체 인코더를 공유 하고 Adversarial Classifier를 사용하여 인코더에서 스피커 의존 정보를 제거합니다. 두 번째는 각 언어에 대해 별도의 인코더가 있습니다. 마지막으로, 세 번째는 첫 번째 방법, 즉 첫 번째 방법의 효과적인 매개 변수 공유와 두 번째 방법의 유연성을 결합하려는 시도입니다. 매개 변수 생성기 에 의해 생성 된 언어 별 매개 변수를 갖춘 완전히 컨볼 루션 인코더가 있습니다. 또한 도메인 적대적인 훈련의 원리를 따르는 적대 스피커 분류기를 사용합니다. 위의 그림을 참조하십시오.
대화식 데모는 코드 전환 능력을 도입하고 생성 된 모델의 공동 다국어 교육 (Enhanced CSS10 데이터 세트에 대한 교육)을 각각 여기 및 여기에서 사용할 수 있습니다.
세 가지 비교 모델을 사용하여 합성 된 많은 샘플 이이 웹 사이트에 있습니다. 여기에는 Griffin-Lim 보코더 (구현의 정신 점검)와 함께 LJ Speech에서 훈련 된 단일 언어 바닐라 타코트론에 의해 합성 된 몇 가지 샘플이 포함되어 있습니다.
코드 전환 또는 음성 클로닝을 지원하는 최상의 모델은 여기에서 다운로드 할 수 있으며 음성 클로닝을 수행하려는 야망없이 전체 CSS10 데이터 세트에 대한 최고의 모델을 여기에서 사용할 수 있습니다.
우리는 이제 다국어 타코트론의 훈련을 실행하는 방법을 보여줄 것입니다. Wavernn 모델을 기반으로 한 보코더를 사용하거나 자세한 내용은 저장소를 참조하거나 미리 훈련 된 모델을 사용하십시오.
git clone https://github.com/Tomiinek/Multilingual_Text_to_Speech.git
cd Multilingual_Text_to_Speech
pip3 install -r requirements.txt
CSS10 데이터 세트 (Apache License 2.0)와 청소 된 공통 음성 데이터 (Creative Commons CC0)를 다운로드하십시오.
cd /project_root/data/css10
CSS10 저장소를 방문하여 모든 언어에 대한 데이터를 다운로드하십시오. 다운로드 된 아카이브를 추출하십시오. 예를 들어, 프랑스어의 경우 다음 폴더 구조가 표시됩니다.
data/css10/french/lesmis/
data/css10/french/lupincontresholme/
data/css10/french/transcript.txt
다음으로 청소 된 공통 음성 데이터 세트를 다운로드하십시오.
cd /project_root/data/comvoi_clean
wget https://github.com/Tomiinek/Multilingual_Text_to_Speech/releases/download/v1.0/comvoi.zip
unzip -q comvoi.zip -d clean_comvoi
rm comvoi.zip
이 저장소는 정리 된 전사 및 메타 파일을 제공하며 해당 .wav 파일을 이미 다운로드했습니다. 그러나 스펙트로 그램을 선입하는 것은 편리합니다 (훈련 속도를 높이기). 이를 고려할 때 Mel 및 Linear Spectrograms를 생성하는 임시 스크립트를 실행할 수 있습니다.
cd /project_root/data/
python3 prepare_css_spectrograms.py
TextToSpeechDataset.create_meta_file 메소드를 원래 다운로드 및 추출한 데이터 (LJ 음성, M- 아일 라브 등에 예 : dataset/loaders.py 참조)에 적용하여 다른 데이터 세트에 대한 메타 파일, 스펙트로 그램 및 음운 전 사체를 만들 수 있습니다. 그런 다음 메타 파일을 train.txt 및 val.txt 파일로 나누어야합니다.
이제 우리는 훈련을 실행할 수 있습니다. 매개 변수에 대한 철저한 설명이있는 params/params.py 파일을 참조하십시오. params 폴더에는 CSS10 데이터 세트 전체에 대한 다국어 교육 및 정리 된 공통 음성 및 CSS10의 5 개 언어로 구성된 데이터 세트의 코드 전환 모델 교육을위한 준비된 매개 변수 구성 ( generated_switching.json 등)도 포함되어 있습니다.
예를 들어 미리 정의 된 구성 (빠른 시작에 권장)으로 훈련하십시오 .
PYTHONIOENCODING=utf-8 python3 train.py --hyper_parameters generated_switching
누락 된 확장자 ( .json )에 유의하십시오.
또는 기본 매개 변수가있는 (기본 데이터 세트는 LJ Speech) :
PYTHONIOENCODING=utf-8 python3 train.py
기본적으로 교육 로그는 logs 디렉토리에 저장됩니다. Tensorboard를 사용하여 교육을 모니터링하십시오.
tensorboard --logdir logs --port 6666 &
체크 포인트는 기본적으로 checkpoints 디렉토리에 저장됩니다. 여기에는 모델 가중치, 파라미터, Optimizer 상태 및 스케줄러 상태가 포함됩니다. 체크 포인트에서 교육을 복원하려면 checkpoints/CHECKPOINT-1 이라는 이름이 다음과 같이 가정 해 보겠습니다.
PYTHONIOENCODING=utf-8 python3 train.py --checkpoint CHECKPOINT-1
스펙트로 그램을 생성하려면 synthesize.py 또는 대화식 콜랩 노트북 (여기 및 여기)을 참조하십시오. 체크 포인트 checkpoints/CHECKPOINT-1 사용하고 합성 된 스펙트로 그램과 그리핀-LIM 알고리즘을 사용하여 보코드 된 해당 파형을 모두 저장하는 예제 호출.
echo "01|Dies ist ein Beispieltext.|00-fr|de" | python3 synthesize.py --checkpoint checkpoints/CHECKPOINT-1 --save_spec
우리는 wavernn 모델을 사용하여 보코딩을 사용했습니다. 전체 CSS10 데이터 세트에서 사전 훈련 된 Wavernn weights를 다운로드 할 수 있습니다. 사용의 예를 보려면 대화식 데모 (여기 및 여기) 또는이 저장소를 방문하십시오.
포함 된 소스 코드 및 해당 구조에 대한 자세한 내용은이 파일을 참조하십시오.
@inproceedings{Nekvinda2020,
author={Tomáš Nekvinda and Ondřej Dušek},
title={{One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={2972--2976},
doi={10.21437/Interspeech.2020-2679},
url={http://dx.doi.org/10.21437/Interspeech.2020-2679}
}


