Multilingual_Text_to_Speech
1.0.0
Démo de synthèse interactive
Site Web avec des échantillons
Papier et description
Ce référentiel fournit des échantillons synthétisés, des données de formation et d'évaluation, le code source et les paramètres du modèle Paper One, de nombreuses langues: méta-apprentissage pour le texte-parole multilingue .
Il contient une implémentation de Tacotron 2 qui prend en charge des expériences multilingues et qui met en œuvre différentes approches du partage des paramètres d'encodeur . Il présente un modèle combinant des idées de l'apprentissage à parler couramment dans une langue étrangère: synthèse de la parole multilingue et clonage vocal transversal, TTS à commutation de code de bout en bout avec mélange d'enregistrements monolinguaux et génération de paramètres contextuels pour la traduction machine neurale universelle.
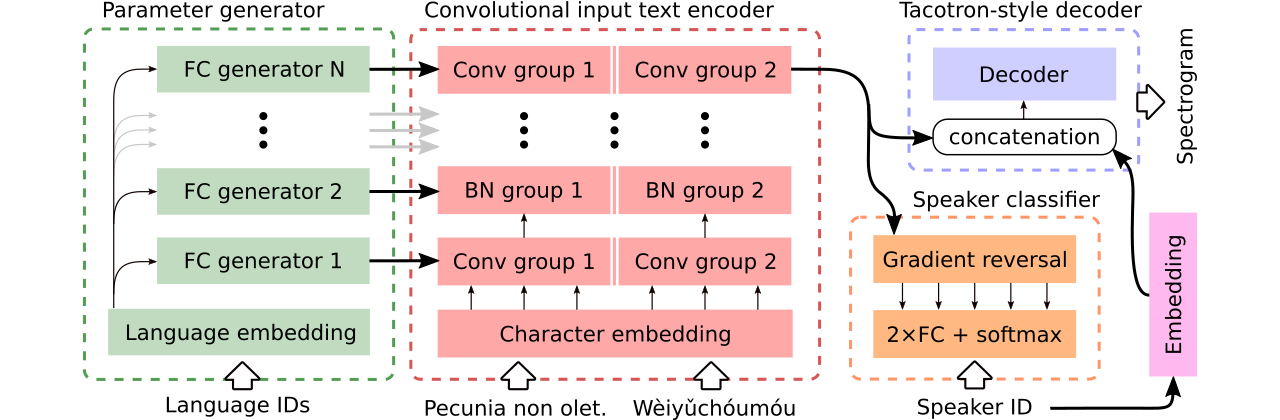
Nous fournissons des données pour la comparaison de trois modèles multilingues de texte vocale . Le premier partage l'ensemble de l'encodeur et utilise un classificateur contradictoire pour supprimer les informations dépendantes de l'enceinte de l'encodeur. Le second a des encodeurs distincts pour chaque langue. Enfin, le troisième est notre tentative de combinaison du meilleur des deux approches précédentes, c'est-à-dire un partage de paramètres efficace de la première méthode et de la flexibilité de la seconde. Il a un codeur entièrement convolutionnel avec des paramètres spécifiques au langage générés par un générateur de paramètres . Il utilise également un classificateur de conférences contradictoires qui suit les principes de la formation contradictoire du domaine. Voir l'illustration ci-dessus.
Les démos interactives introduisant les capacités de commutation de code et la formation multilingue conjointe du modèle généré (formé sur un ensemble de données CSS10 amélioré) sont disponibles ici et ici, respectivement.
De nombreux échantillons synthétisés à l'aide des trois modèles comparés sont sur ce site Web. Il contient également quelques échantillons synthétisés par un tacotron à vanille monolingue formé sur la parole LJ avec le Griffin-LIM Vocoder (une vérification de la santé mentale de notre implémentation).
Notre meilleur modèle de prise en charge de code ou de clonage vocal peut être téléchargé ici et le meilleur modèle formé sur l'ensemble de l'ensemble de données CSS10 sans l'ambition de faire un clonage vocal est disponible ici.
Nous allons maintenant montrer comment suivre l'entraînement de notre tacotron multilingue. Nous avons utilisé un vocodeur basé sur le modèle Wavernn, voir ce référentiel pour plus de détails ou utiliser notre modèle pré-formé.
git clone https://github.com/Tomiinek/Multilingual_Text_to_Speech.git
cd Multilingual_Text_to_Speech
pip3 install -r requirements.txt
Téléchargez l'ensemble de données CSS10 (Licence Apache 2.0) et nos données vocales communes nettoyées (Creative Commons CC0).
cd /project_root/data/css10
Visitez le référentiel CSS10 et téléchargez des données pour toutes les langues. Extraire les archives téléchargées. Par exemple, dans le cas du français, vous devriez voir la structure du dossier suivant:
data/css10/french/lesmis/
data/css10/french/lupincontresholme/
data/css10/french/transcript.txt
Ensuite, téléchargez notre ensemble de données vocales commune nettoyés:
cd /project_root/data/comvoi_clean
wget https://github.com/Tomiinek/Multilingual_Text_to_Speech/releases/download/v1.0/comvoi.zip
unzip -q comvoi.zip -d clean_comvoi
rm comvoi.zip
Ce référentiel fournit des transcriptions et des méta-fichiers nettoyés et vous avez déjà téléchargé des fichiers .wav correspondants. Cependant, il est pratique de précomputer les spectrogrammes (il accélère l'entraînement). Compte tenu de cela, vous pouvez exécuter un script ad hoc qui créera des spectrogrammes MEL et linéaires pour vous:
cd /project_root/data/
python3 prepare_css_spectrograms.py
Vous pouvez créer les méta-fichiers, les spectrogrammes et les transcrits phonémifiés pour d'autres ensembles de données en appliquant la méthode TextToSpeechDataset.create_meta_file sur les données téléchargées et extraites d'origine (comme LJ Speech, M-uabs, etc., voir dataset/loaders.py pour les données de données supportées). Notez qu'il est alors nécessaire de diviser le méta-fichier en fichiers train.txt et val.txt .
Maintenant, nous pouvons suivre une formation. Voir le fichier params/params.py avec une description exhaustive des paramètres. Le dossier params contient également des configurations de paramètres préparés (tels que generated_switching.json ) pour une formation multilingue sur l'ensemble de l'ensemble de données CSS10 et pour la formation de modèles de commutation de code sur l'ensemble de données qui consiste en voix commune nettoyée et cinq langues de CSS10.
Train avec des configurations prédéfinies (recommandées pour un démarrage rapide), par exemple:
PYTHONIOENCODING=utf-8 python3 train.py --hyper_parameters generated_switching
Veuillez noter l'extension manquante ( .json ).
Ou avec les paramètres par défaut (l'ensemble de données par défaut est un discours LJ):
PYTHONIOENCODING=utf-8 python3 train.py
Par défaut, les journaux de formation sont enregistrés dans le répertoire logs . Utilisez Tensorboard pour surveiller la formation:
tensorboard --logdir logs --port 6666 &
Les points de contrôle sont enregistrés dans le répertoire checkpoints par défaut. Ils contiennent des poids du modèle, des paramètres, l'état d'optimiseur et l'état du planificateur. Pour restaurer la formation à partir d'un point de contrôle, disons nommé checkpoints/CHECKPOINT-1 , exécutez:
PYTHONIOENCODING=utf-8 python3 train.py --checkpoint CHECKPOINT-1
Pour générer des spectrogrammes, voir synthesize.py ou interactifs Colab Notebooks (ici et ici). Un exemple d'appel qui utilise un checkpoints/CHECKPOINT-1 et qui enregistre à la fois le spectrogramme synthétisé et la forme d'onde correspondante vocale à l'aide de l'algorithme Griffin-LIM:
echo "01|Dies ist ein Beispieltext.|00-fr|de" | python3 synthesize.py --checkpoint checkpoints/CHECKPOINT-1 --save_spec
Nous avons utilisé le modèle Wavernn pour vocoding. Vous pouvez télécharger les poids Wavernn pré-formés sur l'ensemble de l'ensemble de données CSS10. Pour des exemples d'utilisation, visitez nos démos interactives (ici et ici) ou ce référentiel.
Veuillez consulter ce fichier pour plus de détails sur le code source contenu et sa structure.
@inproceedings{Nekvinda2020,
author={Tomáš Nekvinda and Ondřej Dušek},
title={{One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={2972--2976},
doi={10.21437/Interspeech.2020-2679},
url={http://dx.doi.org/10.21437/Interspeech.2020-2679}
}


