Multilingual_Text_to_Speech
1.0.0
การสาธิตการสังเคราะห์แบบโต้ตอบ
เว็บไซต์พร้อมตัวอย่าง
กระดาษและคำอธิบาย
ที่เก็บนี้ให้ตัวอย่างที่สังเคราะห์ข้อมูลการฝึกอบรมและการประเมินผลซอร์สโค้ดและพารามิเตอร์สำหรับกระดาษ รุ่นหนึ่งหลายภาษา: การเรียนรู้ meta สำหรับการพูดหลายภาษากับการพูดหลายภาษา
มันมีการใช้งานของ Tacotron 2 ที่รองรับ การทดลองหลายภาษา และใช้วิธีการที่แตกต่างกันใน การแชร์พารามิเตอร์แบบเข้ารหัส มันนำเสนอแบบจำลองการรวมความคิดจากการเรียนรู้ที่จะพูดอย่างคล่องแคล่วในภาษาต่างประเทศ: การสังเคราะห์คำพูดหลายภาษาและการโคลนเสียงข้ามภาษา, TTS สลับรหัสแบบครบวงจรกับการผสมผสานของการบันทึกภาษาเดียวและการสร้างพารามิเตอร์ตามบริบทสำหรับการแปลเครื่องประสาทสากล
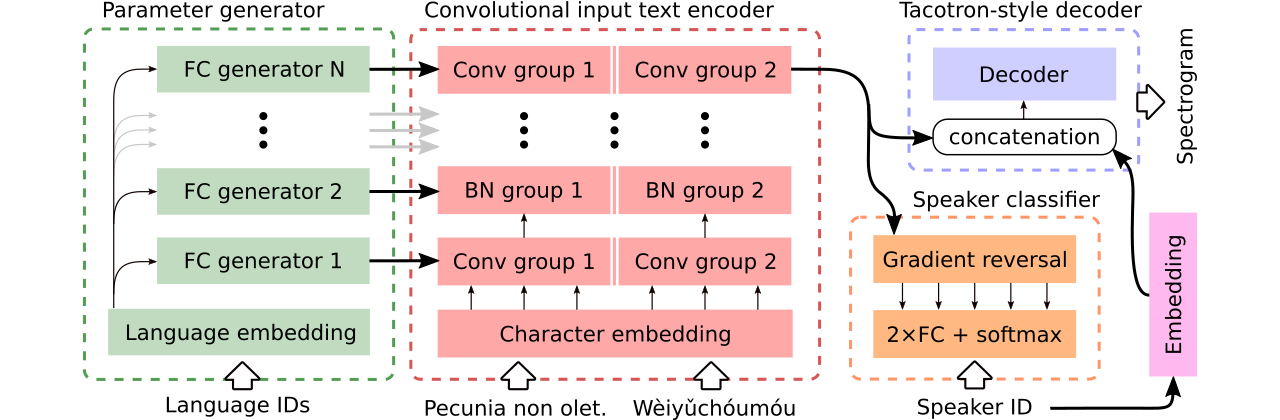
เราให้ข้อมูลสำหรับการเปรียบเทียบ โมเดลข้อความหลายภาษากับการพูดหลายภาษา ครั้งแรก แบ่งปันตัวเข้ารหัสทั้งหมด และใช้ตัวจําแนกที่เป็นปฏิปักษ์เพื่อลบข้อมูลขึ้นอยู่กับลำโพงออกจากตัวเข้ารหัส ที่สองมี ตัวเข้ารหัสแยกต่างหาก สำหรับแต่ละภาษา ในที่สุดสิ่งที่สามคือความพยายามของเราในการรวมวิธีที่ดีที่สุดของทั้งสองวิธีก่อนหน้านี้คือการแบ่งปันพารามิเตอร์ที่มีประสิทธิภาพของวิธีแรกและความยืดหยุ่นของวินาที มันมีตัวเข้ารหัสแบบ convolutional อย่างสมบูรณ์พร้อมพารามิเตอร์เฉพาะภาษาที่สร้างโดย เครื่องกำเนิดพารามิเตอร์ นอกจากนี้ยังใช้ประโยชน์จากตัวจําแนกลำโพงที่เป็นไปได้ซึ่งเป็นไปตามหลักการของการฝึกอบรมฝ่ายตรงข้ามโดเมน ดูภาพประกอบด้านบน
การสาธิตแบบอินเทอร์แอคทีฟ แนะนำความสามารถในการสลับรหัสและการฝึกอบรมหลายภาษาร่วมกันของโมเดลที่สร้างขึ้น (ได้รับการฝึกฝนในชุดข้อมูล CSS10 ที่ปรับปรุงแล้ว) มีให้ที่นี่และที่นี่ตามลำดับ
ตัวอย่างจำนวนมากสังเคราะห์โดยใช้ทั้งสามรุ่นเปรียบเทียบ อยู่ที่เว็บไซต์นี้ นอกจากนี้ยังมีตัวอย่างไม่กี่ตัวอย่างที่สังเคราะห์โดย Tacotron วานิลลาแบบ monolingual ที่ได้รับการฝึกฝนเกี่ยวกับคำพูด LJ กับ Griffin-Lim Vocoder (การตรวจสอบสติของการดำเนินการของเรา)
โมเดลที่ดีที่สุดของเรารองรับการสลับรหัสหรือการโคลนนิ่งเสียงสามารถดาวน์โหลดได้ที่นี่และรุ่นที่ดีที่สุดที่ได้รับการฝึกฝนในชุดข้อมูล CSS10 ทั้งหมดโดยไม่มีความทะเยอทะยานในการทำโคลนด้วยเสียงที่นี่
ตอนนี้เรากำลังจะแสดงวิธีการฝึกอบรมทาโคทรอนหลายภาษาของเรา เราใช้นักร้องที่ใช้โมเดล Wavernn ดูที่เก็บนี้สำหรับรายละเอียดเพิ่มเติมหรือใช้โมเดลที่ผ่านการฝึกอบรมมาก่อน
git clone https://github.com/Tomiinek/Multilingual_Text_to_Speech.git
cd Multilingual_Text_to_Speech
pip3 install -r requirements.txt
ดาวน์โหลดชุดข้อมูล CSS10 (Apache License 2.0) และข้อมูลเสียงทั่วไปที่ทำความสะอาดของเรา (Creative Commons CC0)
cd /project_root/data/css10
เยี่ยมชมที่เก็บ CSS10 และดาวน์โหลดข้อมูลสำหรับทุกภาษา แยกคลังเก็บที่ดาวน์โหลดมา ตัวอย่างเช่นในกรณีของภาษาฝรั่งเศสคุณควรเห็นโครงสร้างโฟลเดอร์ต่อไปนี้:
data/css10/french/lesmis/
data/css10/french/lupincontresholme/
data/css10/french/transcript.txt
ต่อไปดาวน์โหลดชุดข้อมูลเสียงทั่วไปที่ทำความสะอาดของเรา:
cd /project_root/data/comvoi_clean
wget https://github.com/Tomiinek/Multilingual_Text_to_Speech/releases/download/v1.0/comvoi.zip
unzip -q comvoi.zip -d clean_comvoi
rm comvoi.zip
ที่เก็บนี้ให้การถอดเสียงที่ทำความสะอาดและ meta-files และคุณได้ดาวน์โหลดไฟล์ .wav ที่สอดคล้องกันแล้ว อย่างไรก็ตามมันมีประโยชน์ในการคำนวณ prectrograms (มันเพิ่มความเร็วในการฝึกอบรม) ในมุมมองนั้นคุณสามารถเรียกใช้สคริปต์เฉพาะกิจที่จะสร้าง MEL และ Spectrograms เชิงเส้นสำหรับคุณ:
cd /project_root/data/
python3 prepare_css_spectrograms.py
คุณสามารถสร้าง meta-file, spectrograms และ transcripts phonemicized สำหรับชุดข้อมูลอื่น ๆ โดยใช้วิธี dataset/loaders.py TextToSpeechDataset.create_meta_file กับ ข้อมูลที่ดาวน์โหลดและสกัดดั้งเดิม (เช่น LJ Speech, M-Ailabs ฯลฯ โปรดทราบว่าจำเป็นต้องแยกไฟล์ meta-file เป็นไฟล์ train.txt และ val.txt
ตอนนี้เราสามารถฝึกอบรมได้ ดูไฟล์ params/params.py พร้อมคำอธิบายแบบละเอียดของพารามิเตอร์ โฟลเดอร์ params ยังมี การกำหนดค่าพารามิเตอร์ที่เตรียมไว้ (เช่น generated_switching.json ) สำหรับการฝึกอบรมหลายภาษาในชุดข้อมูล CSS10 ทั้งหมดและสำหรับการฝึกอบรมโมเดลการสลับรหัสในชุดข้อมูลที่ประกอบด้วยเสียงทั่วไปที่ทำความสะอาดและห้าภาษาของ CSS10
ฝึกอบรมด้วยการกำหนดค่าที่กำหนดไว้ล่วงหน้า (แนะนำสำหรับการเริ่มต้นอย่างรวดเร็ว) ตัวอย่างเช่น:
PYTHONIOENCODING=utf-8 python3 train.py --hyper_parameters generated_switching
โปรดทราบส่วนขยายที่หายไป ( .json )
หรือด้วยพารามิเตอร์เริ่มต้น (ชุดข้อมูลเริ่มต้นคือคำพูด LJ):
PYTHONIOENCODING=utf-8 python3 train.py
โดยค่าเริ่ม ต้นบันทึกการฝึกอบรม จะถูกบันทึกลงในไดเรกทอรี logs ใช้ Tensorboard เพื่อตรวจสอบการฝึกอบรม:
tensorboard --logdir logs --port 6666 &
จุดตรวจจะถูกบันทึกลงในไดเรกทอรี checkpoints โดยค่าเริ่มต้น พวกเขามีน้ำหนักแบบจำลองพารามิเตอร์สถานะเครื่องมือเพิ่มประสิทธิภาพและสถานะของตัวกำหนดตารางเวลา ในการกู้คืนการฝึกอบรมจากจุดตรวจสอบสมมติว่ามีชื่อว่า checkpoints/CHECKPOINT-1 รัน:
PYTHONIOENCODING=utf-8 python3 train.py --checkpoint CHECKPOINT-1
สำหรับการสร้าง spectrograms ดู synthesize.py หรือ notebook colab แบบโต้ตอบ (ที่นี่และที่นี่) ตัวอย่างการโทรที่ใช้ checkpoints/CHECKPOINT-1 และที่บันทึกทั้ง synthesized spectrogram และรูปคลื่นที่สอดคล้องกันโดยใช้อัลกอริทึม griffin-lim:
echo "01|Dies ist ein Beispieltext.|00-fr|de" | python3 synthesize.py --checkpoint checkpoints/CHECKPOINT-1 --save_spec
เราใช้โมเดล Wavernn สำหรับการร้อง คุณสามารถดาวน์โหลด Wavernn Weights ที่ผ่านการฝึกอบรมไว้ล่วงหน้าในชุดข้อมูล CSS10 ทั้งหมด สำหรับตัวอย่างการใช้งานเยี่ยมชมการสาธิตแบบโต้ตอบของเรา (ที่นี่และที่นี่) หรือที่เก็บนี้
โปรดดูไฟล์นี้สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับรหัสแหล่งที่มาและโครงสร้าง
@inproceedings{Nekvinda2020,
author={Tomáš Nekvinda and Ondřej Dušek},
title={{One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={2972--2976},
doi={10.21437/Interspeech.2020-2679},
url={http://dx.doi.org/10.21437/Interspeech.2020-2679}
}


