Multilingual_Text_to_Speech
1.0.0
Demostración de síntesis interactiva
Sitio web con muestras
Documento y descripción
Este repositorio proporciona muestras sintetizadas, datos de capacitación y evaluación, código fuente y parámetros para el modelo Paper One, muchos idiomas: meta-aprendizaje para texto a voz multilingüe .
Contiene una implementación de Tacotron 2 que admite experimentos multilingües y que implementa diferentes enfoques para el intercambio de parámetros del codificador . Presenta un modelo que combina ideas de aprender a hablar con fluidez en un idioma extranjero: síntesis de habla multilingüe y clonación de voz de lenguaje cruzado, TTS con código de extremo a extremo con una mezcla de grabaciones monolingües y generación de parámetros contextuales para la traducción de la máquina neuronal universal.
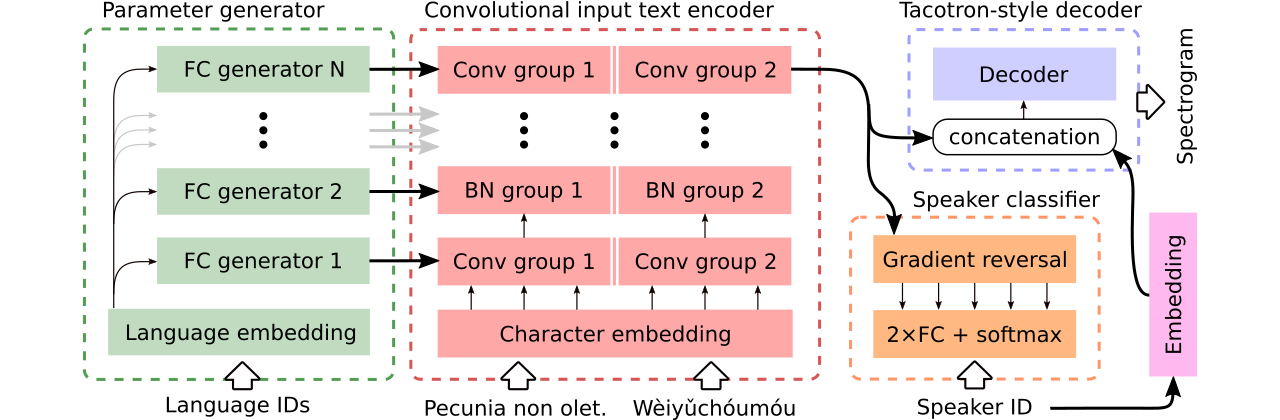
Proporcionamos datos para la comparación de tres modelos multilingües de texto a voz . El primero comparte todo el codificador y utiliza un clasificador adversario para eliminar la información dependiente del altavoz del codificador. El segundo tiene codificadores separados para cada idioma. Finalmente, el tercero es nuestro intento de combinar lo mejor de ambos enfoques anteriores, es decir, compartir parámetros efectivos del primer método y flexibilidad del segundo. Tiene un codificador totalmente convolucional con parámetros específicos del lenguaje generados por un generador de parámetros . También utiliza un clasificador de altavoces adversos que sigue los principios de la capacitación adversaria de dominio. Vea la ilustración de arriba.
Las demostraciones interactivas que introducen habilidades de cambio de código y capacitación multilingüe conjunta del modelo generado (capacitado en un conjunto de datos CSS10 mejorado) están disponibles aquí y aquí, respectivamente.
Muchas muestras sintetizadas usando los tres modelos comparados están en este sitio web. Contiene también algunas muestras sintetizadas por un tacotrón de vainilla monolingüe entrenado en el discurso LJ con el vocoder griffin-lim (una verificación de cordura de nuestra implementación).
Nuestro mejor modelo de cambio de código o clonación de voz se puede descargar aquí y el mejor modelo capacitado en todo el conjunto de datos CSS10 sin la ambición de hacer una clonación de voz está disponible aquí.
Ahora vamos a mostrar cómo ejecutar el entrenamiento de nuestro tacotrón multilingüe. Utilizamos un vocoder que se basa en el modelo Wavernn, consulte este repositorio para obtener más detalles o use nuestro modelo previamente capacitado.
git clone https://github.com/Tomiinek/Multilingual_Text_to_Speech.git
cd Multilingual_Text_to_Speech
pip3 install -r requirements.txt
Descargue el conjunto de datos CSS10 (Licencia Apache 2.0) y nuestros datos de voz comunes limpios (Creative Commons CC0).
cd /project_root/data/css10
Visite el repositorio CSS10 y descargue datos para todos los idiomas. Extraiga los archivos descargados. Por ejemplo, en el caso del francés, debe ver la siguiente estructura de carpetas:
data/css10/french/lesmis/
data/css10/french/lupincontresholme/
data/css10/french/transcript.txt
A continuación, descargue nuestro conjunto de datos de voz común limpio:
cd /project_root/data/comvoi_clean
wget https://github.com/Tomiinek/Multilingual_Text_to_Speech/releases/download/v1.0/comvoi.zip
unzip -q comvoi.zip -d clean_comvoi
rm comvoi.zip
Este repositorio proporciona transcripciones limpias y meta-archivos y ya ha descargado los archivos .wav correspondientes. Sin embargo, es útil precomputar espectrogramas (acelera el entrenamiento). En vista de eso, puede ejecutar un script ad-hoc que creará espectrogramas MEL y lineales para usted:
cd /project_root/data/
python3 prepare_css_spectrograms.py
Puede crear las transcripciones meta-archivo, espectrogramas y fonemicizadas para otros conjuntos de datos aplicando el método TextToSpeechDataset.create_meta_file a los datos originales descargados y extraídos (como el habla LJ, los m-coles, etc., ver dataset/loaders.py para datos compatibles). Tenga en cuenta que luego se necesita dividir el meta-archivo en archivos train.txt y val.txt .
Ahora, podemos ejecutar el entrenamiento. Consulte el archivo params/params.py con una descripción exhaustiva de los parámetros. La carpeta params también contiene configuraciones de parámetros preparadas (como generated_switching.json ) para el entrenamiento multilingüe en todo el conjunto de datos CSS10 y para el entrenamiento de modelos de cambio de código en el conjunto de datos que consiste en una voz común limpia y cinco idiomas de CSS10.
Entrena con configuraciones predefinidas (recomendadas para un inicio rápido), por ejemplo:
PYTHONIOENCODING=utf-8 python3 train.py --hyper_parameters generated_switching
Tenga en cuenta la extensión faltante ( .json ).
O con los parámetros predeterminados (el conjunto de datos predeterminado es LJ Speech):
PYTHONIOENCODING=utf-8 python3 train.py
Por defecto, los registros de capacitación se guardan en el directorio logs . Use Tensorboard para monitorear la capacitación:
tensorboard --logdir logs --port 6666 &
Los puntos de control se guardan en el directorio checkpoints de forma predeterminada. Contienen pesos de modelo, parámetros, el estado del optimizador y el estado del planificador. Para restaurar la capacitación desde un punto de control, digamos que se llamó checkpoints/CHECKPOINT-1 , ejecute:
PYTHONIOENCODING=utf-8 python3 train.py --checkpoint CHECKPOINT-1
Para generar espectrogramas, consulte synthesize.py o cuadernos de colab interactivos (aquí y aquí). Una llamada de ejemplo que utiliza un checkpoints/CHECKPOINT-1 y que guarda tanto el espectrograma sintetizado como la forma de onda correspondiente con el algoritmo Griffin-Lim:
echo "01|Dies ist ein Beispieltext.|00-fr|de" | python3 synthesize.py --checkpoint checkpoints/CHECKPOINT-1 --save_spec
Utilizamos el modelo Wavernn para vocodar. Puede descargar Wavernn Peso previamente entrenado en todo el conjunto de datos CSS10. Para ver ejemplos de uso, visite nuestras demostraciones interactivas (aquí y aquí) o este repositorio.
Por favor, consulte este archivo para obtener más detalles sobre el código fuente contenido y su estructura.
@inproceedings{Nekvinda2020,
author={Tomáš Nekvinda and Ondřej Dušek},
title={{One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={2972--2976},
doi={10.21437/Interspeech.2020-2679},
url={http://dx.doi.org/10.21437/Interspeech.2020-2679}
}


