Multilingual_Text_to_Speech
1.0.0
交互式合成演示
带有样品的网站
纸张和描述
该存储库提供综合样本,培训和评估数据,源代码和参数的纸张模型,许多语言:用于多语言文本到语音的元学习。
它包含TACOTRON 2的实现,该实现支持多语言实验,并实现了不同的编码参数共享方法。它提出了一个模型,结合了学习的想法,以一种外语说话:多语言语音综合和跨语言语音克隆,端到端代码转换的TT与单语录音的混合在一起,以及用于通用神经机器翻译的上下文参数生成。
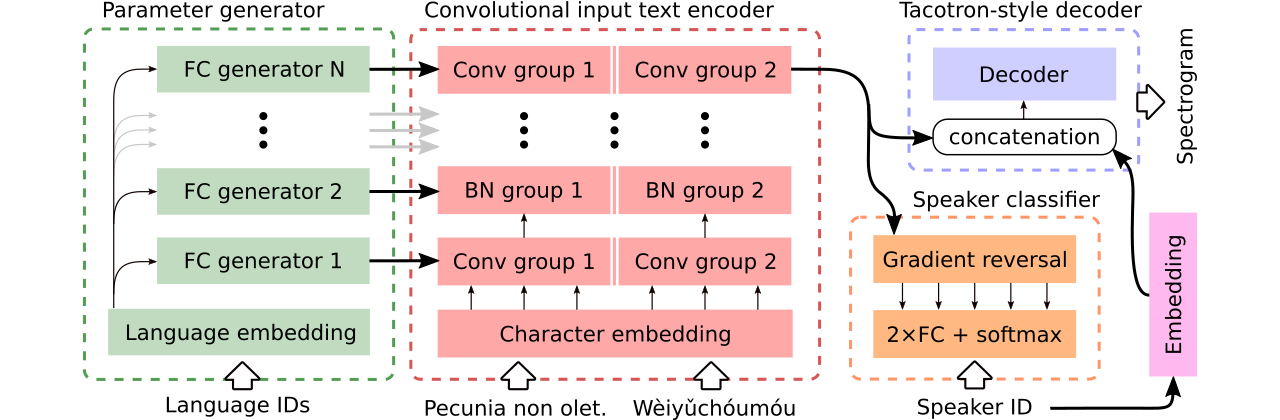
我们提供数据以比较三种多语言文本到语音模型。第一个共享整个编码器,并使用对抗分类器从编码器中删除依赖说话者的信息。第二个具有每种语言的单独编码器。最后,第三个是我们尝试结合以前两种方法中最好的最好的方法,即第一种方法的有效参数共享和第二种方法的灵活性。它具有一个完全卷积编码器,该编码器具有由参数生成器生成的语言特定参数。它还利用遵循域对抗训练的原理的对抗扬声器分类器。请参阅上面的插图。
交互式演示分别在此处和此处都提供了引入代码转换能力和生成模型的联合多语言培训(在增强的CSS10数据集中进行培训)。
使用三个比较模型合成的许多样本都在此网站上。它还包含一些由Griffin-Lim Vocoder(我们实施的理智检查)训练LJ演讲的单语言Tacotron合成的样品。
我们可以在此处下载我们最佳的模型支持代码转换或语音关闭的模型,并且在整个CSS10数据集中训练的最佳模型,而无需雄心勃勃地进行语音关注。
现在,我们将展示如何进行多语言Tacotron的培训。我们使用了基于Wavernn模型的Vocoder,有关更多详细信息,请参见此存储库,或使用我们的预训练模型。
git clone https://github.com/Tomiinek/Multilingual_Text_to_Speech.git
cd Multilingual_Text_to_Speech
pip3 install -r requirements.txt
下载CSS10数据集(Apache License 2.0)和我们清洁的通用语音数据(Creative Commons CC0)。
cd /project_root/data/css10
访问CSS10存储库,并下载所有语言的数据。提取下载的档案。例如,对于法语,您应该看到以下文件夹结构:
data/css10/french/lesmis/
data/css10/french/lupincontresholme/
data/css10/french/transcript.txt
接下来,下载我们清洁的通用语音数据集:
cd /project_root/data/comvoi_clean
wget https://github.com/Tomiinek/Multilingual_Text_to_Speech/releases/download/v1.0/comvoi.zip
unzip -q comvoi.zip -d clean_comvoi
rm comvoi.zip
该存储库提供清洁的成绩单和元文件,您已经下载了相应的.wav文件。但是,预先计算频谱图(加速训练)很方便。鉴于此,您可以运行一个临时脚本,该脚本将为您创建MEL和线性频谱图:
cd /project_root/data/
python3 prepare_css_spectrograms.py
您可以通过将TextToSpeechDataset.create_meta_file方法应用于原始下载和提取的数据(例如LJ语音,M-ailabs等,请参见dataset/loaders.py ),为其他数据集创建其他数据集的元文件,频谱图和音素化的成绩单。请注意,然后需要将元文件拆分为train.txt和val.txt文件。
现在,我们可以进行培训。请参阅带有参数的详尽描述的params/params.py文件。 params文件夹还包含准备好的参数配置(例如generated_switching.json ),用于整个CSS10数据集的多语言培训,以及在数据集中训练由COMSS10的通用语音和五种语言组成的数据集上的代码转换模型。
具有预定义配置的训练(建议快速启动),例如:
PYTHONIOENCODING=utf-8 python3 train.py --hyper_parameters generated_switching
请注意丢失的扩展名( .json )。
或使用默认参数(默认数据集为LJ语音):
PYTHONIOENCODING=utf-8 python3 train.py
默认情况下,将培训日志保存到logs目录中。使用张板监视培训:
tensorboard --logdir logs --port 6666 &
默认情况下,将检查点保存到checkpoints目录中。它们包含模型权重,参数,优化器状态和调度程序的状态。要从检查点恢复培训,请说名为checkpoints/CHECKPOINT-1 ,运行:
PYTHONIOENCODING=utf-8 python3 train.py --checkpoint CHECKPOINT-1
有关生成频谱图,请参见synthesize.py或Interactive Colab笔记本电脑(此处和此处)。使用CheckPoint checkpoints/CHECKPOINT-1示例调用,并使用Griffin-Lim算法保存合成的频谱图和相应的波形VOCOD:
echo "01|Dies ist ein Beispieltext.|00-fr|de" | python3 synthesize.py --checkpoint checkpoints/CHECKPOINT-1 --save_spec
我们使用了Wavernn模型进行录音。您可以在整个CSS10数据集中下载预先训练的Wavernn权重。有关使用的示例,请访问我们的交互式演示(此处和此处)或此存储库。
请参阅此文件,以获取有关包含的源代码及其结构的更多详细信息。
@inproceedings{Nekvinda2020,
author={Tomáš Nekvinda and Ondřej Dušek},
title={{One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={2972--2976},
doi={10.21437/Interspeech.2020-2679},
url={http://dx.doi.org/10.21437/Interspeech.2020-2679}
}


