Multilingual_Text_to_Speech
1.0.0
توليف تفاعلي تجريبي
موقع مع عينات
الورق والوصف
يوفر هذا المستودع عينات توليف ، وبيانات التدريب والتقييم ، والرمز المصدر ، والمعلمات لنموذج الورق الأول ، والعديد من اللغات: التعلم التعويضي من أجل النص إلى الكلام متعدد اللغات .
أنه يحتوي على تنفيذ Tacotron 2 الذي يدعم التجارب متعددة اللغات وتنفذ مناهج مختلفة لمشاركة معلمات التشفير . إنه يقدم نموذجًا يجمع بين الأفكار من التعلم للتحدث بطلاقة بلغة أجنبية: تخليق الكلام متعدد اللغات واستنساخ الصوت عبر اللغة ، و TTS من طرف إلى طرف مع مزيج من التسجيلات أحادية اللغة ، وتوليد المعلمات السياقية للترجمة الآلية العصبية الشاملة.
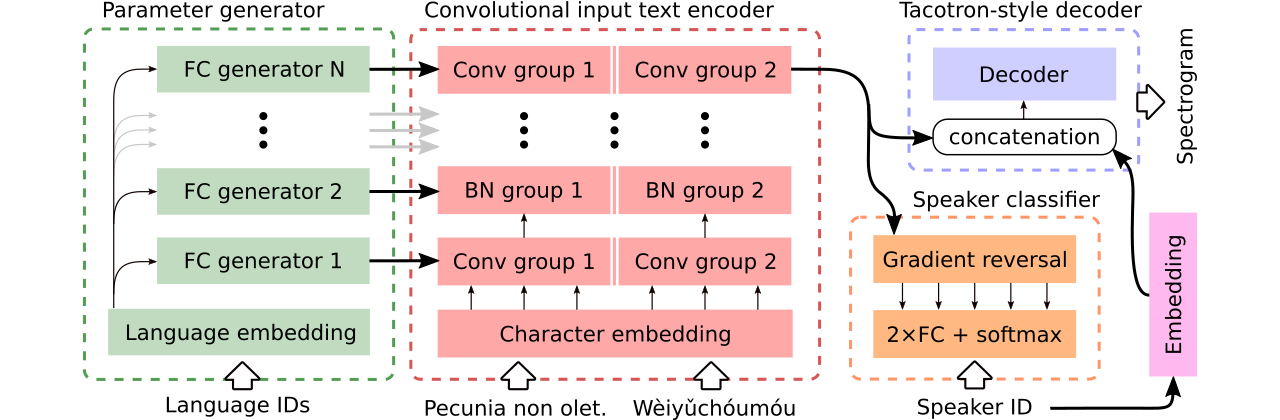
نحن نقدم بيانات لمقارنة ثلاث نماذج نصية إلى كلام متعددة اللغات . يشارك أول تشفير كامل ويستخدم مصنف العدواني لإزالة المعلومات التي تعتمد على السماعات من المشفر. والثاني لديه ترميزات منفصلة لكل لغة. أخيرًا ، والثالث هو محاولتنا للجمع بين أفضل الأساليب السابقة ، أي تقاسم المعلمات الفعال للطريقة الأولى ومرونة الثانية. يحتوي على تشفير تلفيلي بالكامل مع معلمات خاصة باللغة تم إنشاؤها بواسطة مولد المعلمة . كما أنه يستفيد من مصنف مكبر صوت عدواني يتبع مبادئ التدريب العدائي للمجال. انظر الرسم التوضيحي أعلاه.
تتوفر هنا التوصيف التفاعلي التي تقدم قدرات تبديل الكود والتدريب المشترك متعدد اللغات للنموذج الذي تم إنشاؤه (المدربين على مجموعة بيانات CSS10 المحسّنة) هنا ، على التوالي.
العديد من العينات التي تم تصنيعها باستخدام النماذج الثلاثة المقارنة موجودة في هذا الموقع. يحتوي أيضًا على عدد قليل من العينات التي تم تصنيعها بواسطة فانيليا تاكوترون أحادي اللغة المدربين على خطاب LJ مع Vocoder Griffin-Lim (فحص عقلانية لتنفيذنا).
يمكن تنزيل أفضل نموذج لتبديل الكود أو التصريف الصوتي هنا ، كما أن أفضل نموذج يتم تدريبه على مجموعة بيانات CSS10 بأكملها دون أن يتوفر طموح القيام بالتعديل الصوتي هنا.
سنعرض الآن كيفية تشغيل التدريب على Tacotron متعدد اللغات. استخدمنا Vocoder يعتمد على نموذج Wavernn ، أو نرى هذا المستودع لمزيد من التفاصيل ، أو استخدم نموذجنا الذي تم تدريبه مسبقًا.
git clone https://github.com/Tomiinek/Multilingual_Text_to_Speech.git
cd Multilingual_Text_to_Speech
pip3 install -r requirements.txt
قم بتنزيل مجموعة بيانات CSS10 (Apache License 2.0) وبياناتنا الصوتية المشتركة التي تم تنظيفها (Creative Commons CC0).
cd /project_root/data/css10
قم بزيارة مستودع CSS10 وتنزيل البيانات لجميع اللغات. استخراج المحفوظات التي تم تنزيلها. على سبيل المثال ، في حالة الفرنسية ، يجب أن ترى هيكل المجلد التالي:
data/css10/french/lesmis/
data/css10/french/lupincontresholme/
data/css10/french/transcript.txt
بعد ذلك ، قم بتنزيل مجموعة البيانات الصوتية المشتركة الخاصة بنا:
cd /project_root/data/comvoi_clean
wget https://github.com/Tomiinek/Multilingual_Text_to_Speech/releases/download/v1.0/comvoi.zip
unzip -q comvoi.zip -d clean_comvoi
rm comvoi.zip
يوفر هذا المستودع النصوص التي تم تنظيفها وملفات التعريف وقمت بتنزيل ملفات .wav المقابلة بالفعل. ومع ذلك ، فمن السهل أن تتمثل في الطيفية (فهو يسرع التدريب). في ضوء ذلك ، يمكنك تشغيل برنامج نصي مخصص من شأنه أن يخلق طيف MEL والخطية لك:
cd /project_root/data/
python3 prepare_css_spectrograms.py
يمكنك إنشاء ملف التعريف ، والطيبيون ، والنصوص الصوتية لمجموعات البيانات الأخرى من خلال تطبيق TextToSpeechDataset.create_meta_file على البيانات الأصلية التي تم تنزيلها واستخلاصها (مثل خطاب LJ ، M-ilabs ، وما إلى ذلك ، انظر dataset/loaders.py . لاحظ أنه من الضروري بعد ذلك تقسيم ملف التعريف إلى ملفات train.txt و val.txt .
الآن ، يمكننا تشغيل التدريب. راجع ملف params/params.py مع وصف شامل للمعلمات. يحتوي مجلد params أيضًا على تكوينات معلمة معدّة (مثل generated_switching.json ) للتدريب متعدد اللغات على مجموعة بيانات CSS10 بالكامل ولتدرب نماذج تبديل الكود على مجموعة البيانات التي تتكون من صوت مشترك تم تنظيفه وخمس لغات من CSS10.
تدريب مع تكوينات محددة مسبقًا (موصى بها للبدء السريع) ، على سبيل المثال:
PYTHONIOENCODING=utf-8 python3 train.py --hyper_parameters generated_switching
يرجى ملاحظة الامتداد المفقود ( .json ).
أو مع المعلمات الافتراضية (مجموعة البيانات الافتراضية هي خطاب LJ):
PYTHONIOENCODING=utf-8 python3 train.py
بشكل افتراضي ، يتم حفظ سجلات التدريب في دليل logs . استخدم Tensorboard لمراقبة التدريب:
tensorboard --logdir logs --port 6666 &
يتم حفظ نقاط التفتيش في دليل checkpoints بشكل افتراضي. أنها تحتوي على أوزان نموذجية ، والمعلمات ، وحالة المحسن ، وحالة الجدولة. لاستعادة التدريب من نقطة تفتيش ، دعنا نقول أن checkpoints/CHECKPOINT-1 المسماة ، تشغيل:
PYTHONIOENCODING=utf-8 python3 train.py --checkpoint CHECKPOINT-1
لتوليد الطيف ، راجع أجهزة الكمبيوتر المحمولة colab synthesize.py أو التفاعلية (هنا وهنا). مكالمة مثال تستخدم checkpoints/CHECKPOINT-1 والتي تحفظ كلاً من الطيفية المتوازنة والمفرط الموجي المقابل باستخدام خوارزمية غريفين--LIM:
echo "01|Dies ist ein Beispieltext.|00-fr|de" | python3 synthesize.py --checkpoint checkpoints/CHECKPOINT-1 --save_spec
استخدمنا نموذج Wavernn للمفردات. يمكنك تنزيل أوزان Wavernn المدربة مسبقًا على مجموعة بيانات CSS10 بأكملها. للحصول على أمثلة على الاستخدام ، تفضل بزيارة العروض التفاعلية (هنا وهنا) أو هذا المستودع.
يرجى الاطلاع على هذا الملف لمزيد من التفاصيل حول رمز المصدر المعني وهيكله.
@inproceedings{Nekvinda2020,
author={Tomáš Nekvinda and Ondřej Dušek},
title={{One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={2972--2976},
doi={10.21437/Interspeech.2020-2679},
url={http://dx.doi.org/10.21437/Interspeech.2020-2679}
}


