Multilingual_Text_to_Speech
1.0.0
Interaktive Synthese -Demo
Website mit Beispielen
Papier & Beschreibung
Dieses Repository enthält synthetisierte Muster, Schulungs- und Bewertungsdaten, Quellcode und Parameter für das Papier -One-Modell, viele Sprachen: Meta-Learning für mehrsprachige Text-zu-Sprache .
Es enthält eine Implementierung von Tacotron 2 , die mehrsprachige Experimente unterstützt und unterschiedliche Ansätze zur gemeinsamen Nutzung des Encoder -Parameters implementiert. Es präsentiert ein Modell, das Ideen aus dem Lernen kombiniert, fließend in einer Fremdsprache zu sprechen: mehrsprachige Sprachsynthese und sprachübergreifende Sprachklone, von End-to-End-Code-gestellte TTs mit Mischung Monolingualaufzeichnungen und kontextbezogener Parametergenerierung für die universelle neuronale maschinelle Übersetzung.
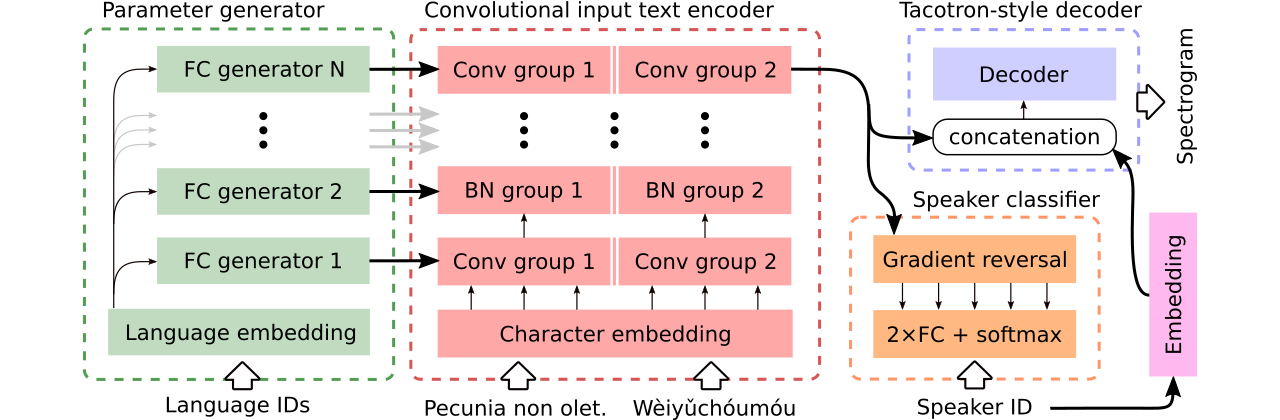
Wir liefern Daten zum Vergleich von drei mehrsprachigen Text-zu-Sprach-Modellen . Der erste teilt den gesamten Encoder mit und verwendet einen kontroversen Klassifikator, um lautsprecherabhängige Informationen aus dem Encoder zu entfernen. Die zweite hat separate Encoder für jede Sprache. Schließlich ist der dritte unser Versuch, das Beste aus beiden früheren Ansätzen zu kombinieren, dh eine effektive Parameterfreigabe der ersten Methode und Flexibilität der zweiten. Es verfügt über einen vollständig Faltungscodierer mit sprachspezifischen Parametern, die von einem Parametergenerator erzeugt werden. Es nutzt auch einen kontroversen Sprecher -Klassifikator, der den Prinzipien des domänenverträgen Trainings folgt. Siehe die Abbildung oben.
Interaktive Demos, die Code-Switching-Fähigkeiten und gemeinsame mehrsprachige Schulungen des generierten Modells (geschult auf einem erweiterten CSS10-Datensatz) einführen, sind hier bzw. hier verfügbar.
Viele Muster, die mit den drei verglichenen Modellen synthetisiert wurden, befinden sich auf dieser Website. Es enthält auch einige Proben, die von einem einsprachigen Vanille-Tacotron synthetisiert wurden, der mit dem Griffin-Lim-Vocoder (eine Vernunftprüfung unserer Implementierung) auf LJ-Rede trainiert wurde.
Unser bestes Modell, das Code-Switching oder Sprachkloning unterstützt, kann hier heruntergeladen werden und das beste Modell, das im gesamten CSS10-Datensatz trainiert wird, ohne dass hier der Ehrgeiz, das Sprachkloning zu machen, verfügbar ist.
Wir werden jetzt zeigen, wie man das Training unseres mehrsprachigen Tacotrons durchführt. Wir haben einen Vocoder verwendet, der auf dem Mervern-Modell basiert, dieses Repository für weitere Details siehe oder unser vorgebildetes Modell verwendet.
git clone https://github.com/Tomiinek/Multilingual_Text_to_Speech.git
cd Multilingual_Text_to_Speech
pip3 install -r requirements.txt
Laden Sie den CSS10 -Datensatz (Apache -Lizenz 2.0) und unsere gereinigten gemeinsamen Sprachdaten (Creative Commons CC0) herunter.
cd /project_root/data/css10
Besuchen Sie das CSS10 -Repository und laden Sie Daten für alle Sprachen herunter. Extrahieren Sie die heruntergeladenen Archive. Beispielsweise sollten Sie im Fall von Französisch die folgende Ordnerstruktur sehen:
data/css10/french/lesmis/
data/css10/french/lupincontresholme/
data/css10/french/transcript.txt
Laden Sie als nächstes unseren gereinigten Common Voice Dataset herunter:
cd /project_root/data/comvoi_clean
wget https://github.com/Tomiinek/Multilingual_Text_to_Speech/releases/download/v1.0/comvoi.zip
unzip -q comvoi.zip -d clean_comvoi
rm comvoi.zip
Dieses Repository enthält saubere Transkripte und Meta-Files, und Sie haben bereits entsprechende .wav Dateien heruntergeladen. Es ist jedoch praktisch, Spektrogramme vorzubereiten (es beschleunigt das Training). In Anbetracht dessen können Sie ein Ad-hoc-Skript ausführen, mit dem Sie MEL- und lineare Spektrogramme für Sie erstellen:
cd /project_root/data/
python3 prepare_css_spectrograms.py
Sie können die Meta-File, Spektrogramme und phonemisierten Transkripte für andere Datensätze erstellen dataset/loaders.py indem Sie die Methode TextToSpeechDataset.create_meta_file auf die original heruntergeladene und extrahierte Daten anwenden (wie LJ-Sprache, M-Sailabs usw.). Beachten Sie, dass es dann benötigt wird, um das Meta-File in Dateien train.txt und val.txt aufzuteilen.
Jetzt können wir Training durchführen. Siehe die Datei params/params.py mit einer umfassenden Beschreibung der Parameter. Der params -Ordner enthält auch vorbereitete Parameterkonfigurationen (z. B. generated_switching.json ) für mehrsprachiges Training im gesamten CSS10-Datensatz und für das Training von Code-Switching-Modellen auf dem Datensatz, das aus gereinigten gemeinsamen Sprache und fünf Sprachen von CSS10 besteht.
Zug mit vordefinierten Konfigurationen (für den schnellen Start empfohlen), zum Beispiel:
PYTHONIOENCODING=utf-8 python3 train.py --hyper_parameters generated_switching
Bitte beachten Sie die fehlende Erweiterung ( .json ).
Oder mit Standardparametern (Standarddatensatz ist LJ -Sprache):
PYTHONIOENCODING=utf-8 python3 train.py
Standardmäßig werden Trainingsprotokolle in das logs gespeichert. Verwenden Sie das Tensorboard, um das Training zu überwachen:
tensorboard --logdir logs --port 6666 &
Kontrollpunkte werden standardmäßig in das checkpoints gespeichert. Sie enthalten Modellgewichte, Parameter, den Optimiererzustand und den Status des Schedulers. Um das Training von einem Kontrollpunkt wiederherzustellen, sagen wir mit den benannten checkpoints/CHECKPOINT-1 : Rennen Sie:
PYTHONIOENCODING=utf-8 python3 train.py --checkpoint CHECKPOINT-1
Weitere Informationen zum Generieren von Spektrogrammen finden Sie in synthesize.py oder interaktiven Colab -Notizbüchern (hier und hier). Ein Beispiel-Aufruf, bei dem ein Checkpoint- checkpoints/CHECKPOINT-1 verwendet wird und sowohl das synthetisierte Spektrogramm als auch das entsprechende Wellenform-Vocoded unter Verwendung des Griffin-Lim-Algorithmus speichert:
echo "01|Dies ist ein Beispieltext.|00-fr|de" | python3 synthesize.py --checkpoint checkpoints/CHECKPOINT-1 --save_spec
Wir verwendeten das Wvernn -Modell zum Vokodieren. Sie können die im gesamten CSS10-Datensatz vorgebrachten Raernn-Gewichte herunterladen. Beispiele für die Nutzung finden Sie in unseren interaktiven Demos (hier und hier) oder in diesem Repository.
Bitte finden Sie in dieser Datei weitere Informationen zum enthaltenen Quellcode und seiner Struktur.
@inproceedings{Nekvinda2020,
author={Tomáš Nekvinda and Ondřej Dušek},
title={{One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={2972--2976},
doi={10.21437/Interspeech.2020-2679},
url={http://dx.doi.org/10.21437/Interspeech.2020-2679}
}


