WavThruVec_pytorch
1.0.0
基於Pytorch的WavThruvec的非正式實施。
原始論文是wavthruvec:潛在語音表示為神經語音綜合的中間特徵
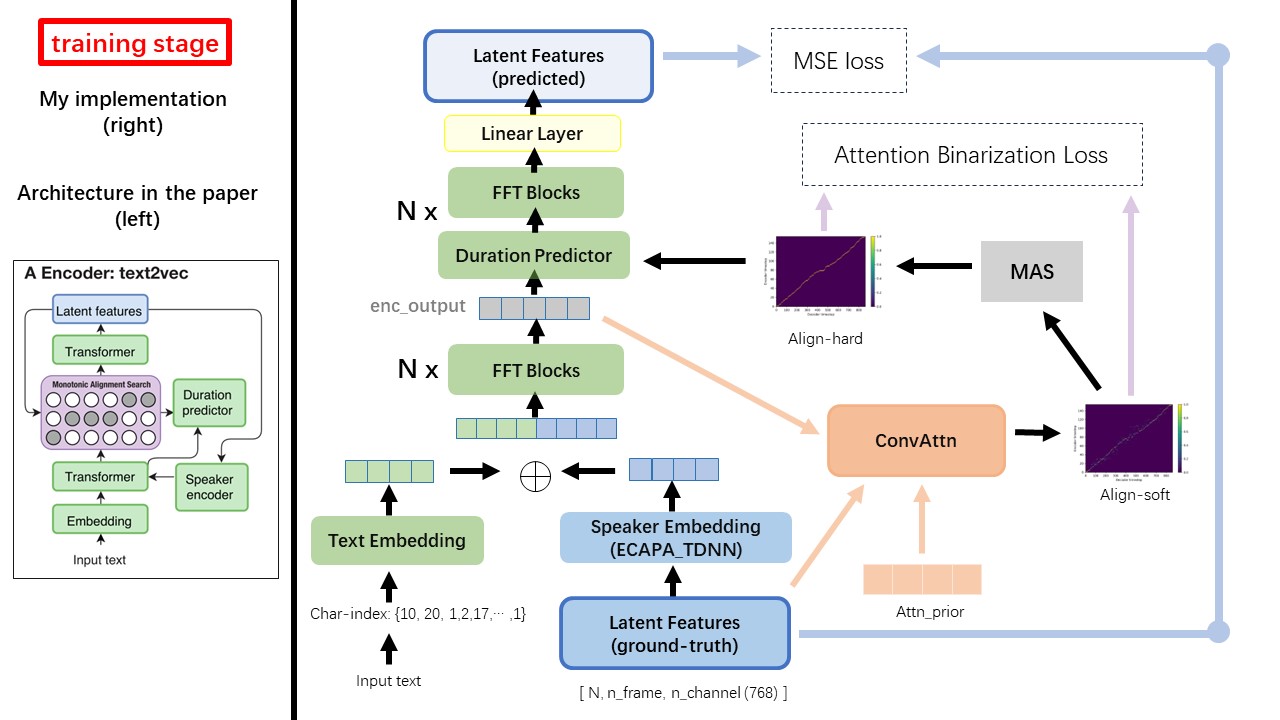
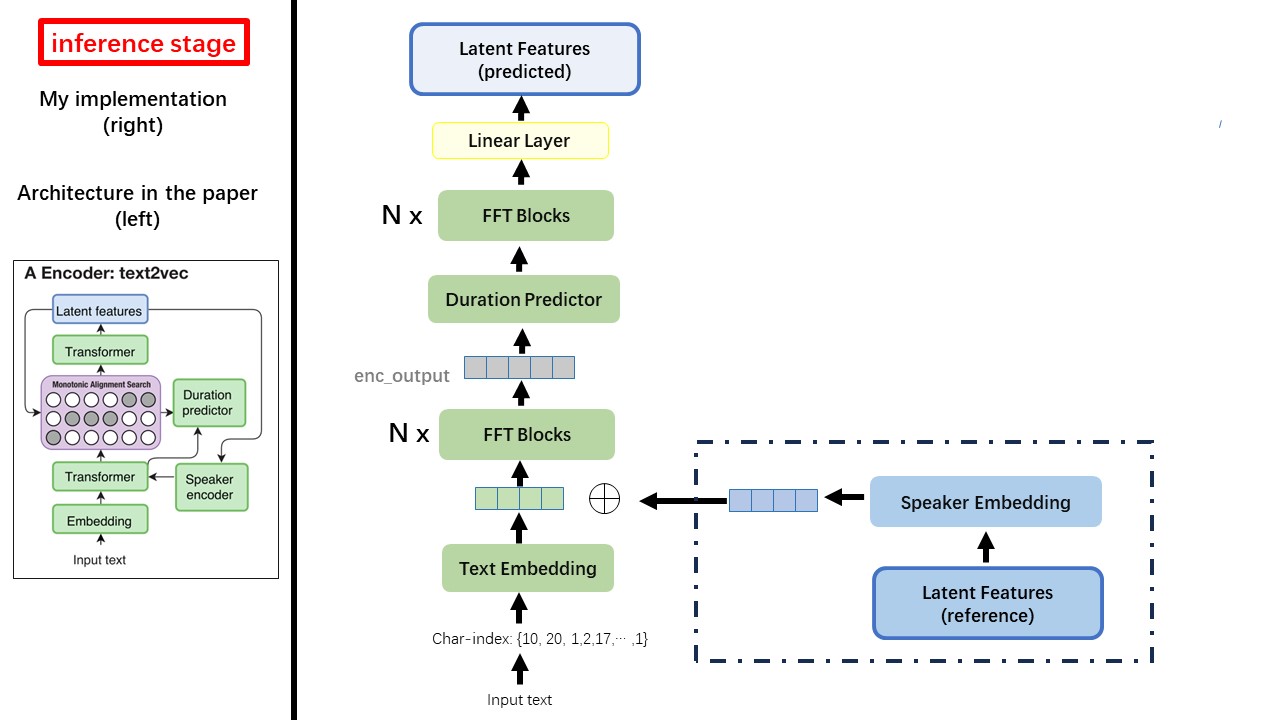
Text2VEC模型主要遵循FastSpeech(XCMYZ)架構。我修改了該模型,主要基於RAD-TTS(NVIDIA)。我添加了一個ecapa_tdnn作為揚聲器編碼器,用於多說話的條件。
對於論文中未提及的其他細節,我也遵循RAD-TT。
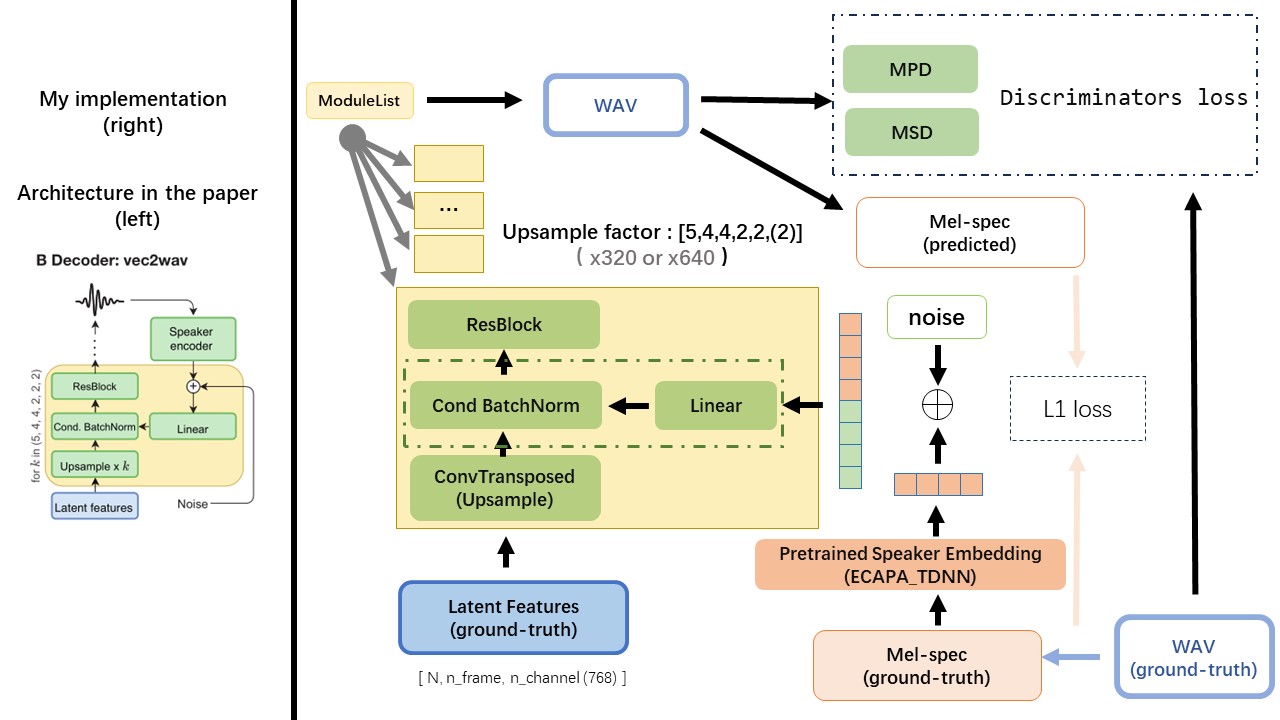
VEC2WAV主要基於HIFI-GAN,並引入有條件的批准化以調節揚聲器嵌入的網絡。上樣本率序列為(5,4,4,2,2),因此上採樣因子為
請勿使用任何基於規則的文本歸一化或音義方法,而是使用原始字符,而是將其轉換為文本插入作為輸入。
使用wav2Vec 2.0的輸出作為WAV的功能(而不是MEL頻譜圖),並具有'float32'的dtype和(batch_size, n_frame, n_channel)的形狀。
注意:N_Channel = 768或1024,這取決於您正在使用的WAV2VEC 2.0的版本,因為TencentGamemate提供Fairseq-version(768)和HuggingFace-version(1024)。這兩個版本具有不同的輸出形狀。
從此存儲庫WAV2VEC2.0(中國的演講預處理),也可以在Huggingface中找到
Wavthuvec和FastSpeech之間最大的區別之一是單調對齊搜索(MAS)模塊(請參閱alignment.py )。
在FastSpeech中,培訓輸入包括梅爾框架和文本令牌的教師對齊。具體而言,它涉及使用MFA在訓練之前為每個文本令牌生成MEL框架的duration 。
在WavThruvec中,使用RAD-TTS的MAS生成duration ,並將其送入長度調節器(持續時間預測器)。
根據單調對齊搜索和RAD-TTS實現,當您訓練模型時,將在'./data/align_prior'下生成Align-Prior文件,並使用{n_token}_{n_feat}_prior.pth的文件名格式。
aishell3
prepar_data.py:
例如,準備_data.py只需幾個揚聲器和幾個WAV文件。
WavThruvec違反了2個組件:Text2Vec(編碼器)和VEC2WAV(解碼器),它們獨立訓練
因此,我將它們放在兩個單獨的DIRS中,並為每種配置使用了不同的訓練配置。
張板記錄器存儲在run/{log_seed}/tb_logs目錄中。假設log_seed=1 ,您可以使用此命令在本地主機上使用張量。
tensorboard --logdir run/1/tb_logs
模型檢查點保存在run/{log_seed}/model_new目錄中。
假設您每10000迭代保存檢查點,現在您有一個檢查點checkpoint_10000.pth.tar 。如果您需要在step 10000重新啟動培訓,請使用此命令。
python ./text2vec/train.py --restore_step 10000


