WavThruVec_pytorch
1.0.0
基于Pytorch的WavThruvec的非正式实施。
原始论文是wavthruvec:潜在语音表示为神经语音综合的中间特征
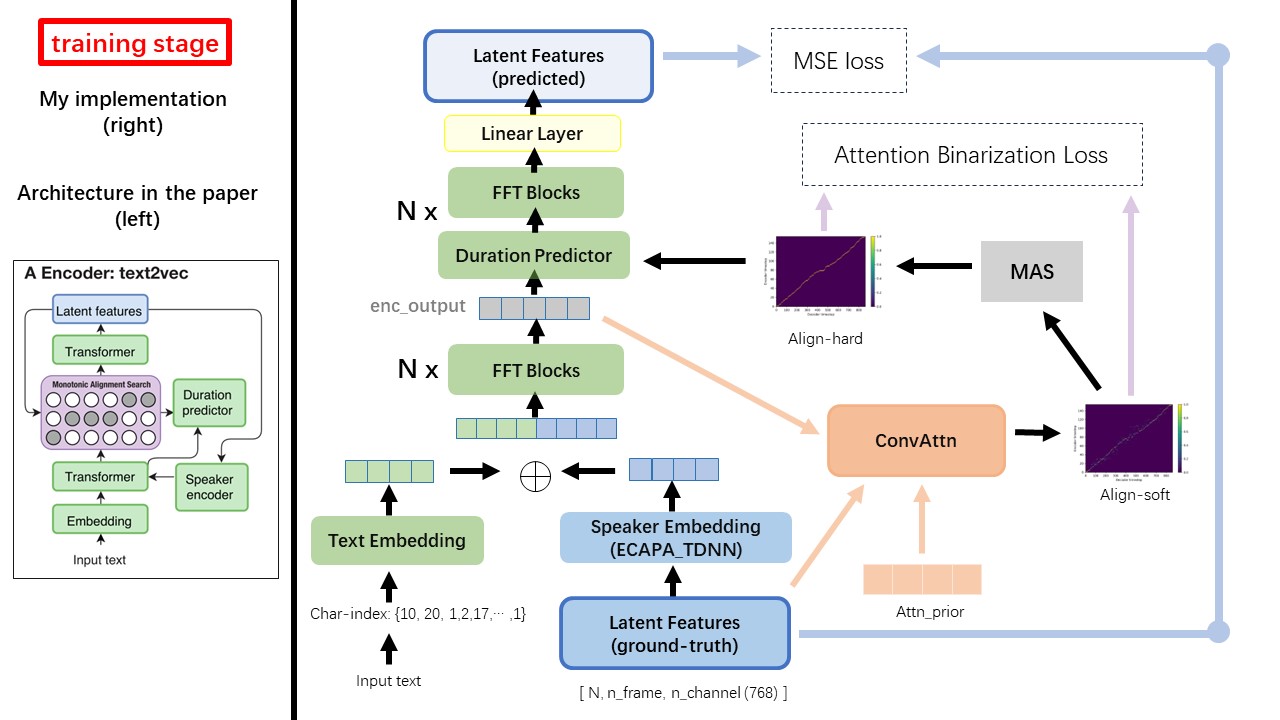
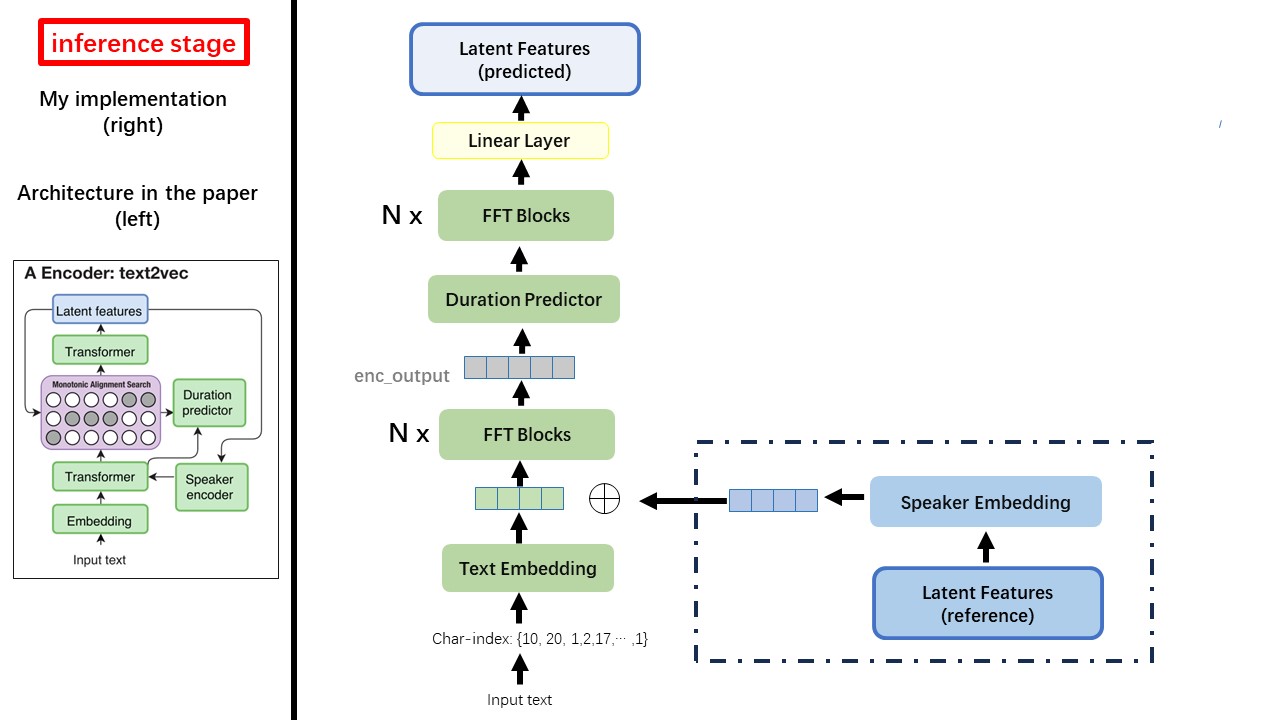
Text2VEC模型主要遵循FastSpeech(XCMYZ)架构。我修改了该模型,主要基于RAD-TTS(NVIDIA)。我添加了一个ecapa_tdnn作为扬声器编码器,用于多说话的条件。
对于论文中未提及的其他细节,我也遵循RAD-TT。
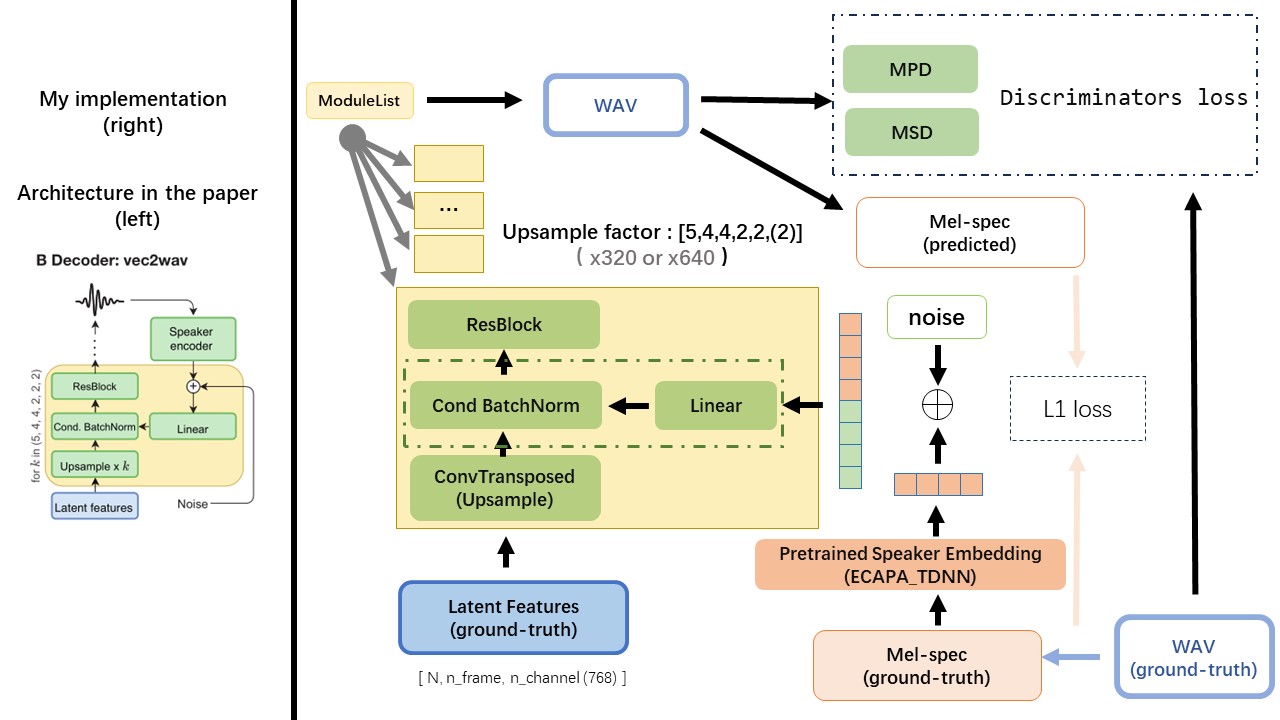
VEC2WAV主要基于HIFI-GAN,并引入有条件的批准化以调节扬声器嵌入的网络。上样本率序列为(5,4,4,2,2),因此上采样因子为
请勿使用任何基于规则的文本归一化或音义方法,而是使用原始字符,而是将其转换为文本插入作为输入。
使用wav2Vec 2.0的输出作为WAV的功能(而不是MEL频谱图),并具有'float32'的dtype和(batch_size, n_frame, n_channel)的形状。
注意:N_Channel = 768或1024,这取决于您正在使用的WAV2VEC 2.0的版本,因为TencentGamemate提供Fairseq-version(768)和HuggingFace-version(1024)。这两个版本具有不同的输出形状。
从此存储库WAV2VEC2.0(中国的演讲预处理),也可以在Huggingface中找到
Wavthuvec和FastSpeech之间最大的区别之一是单调对齐搜索(MAS)模块(请参阅alignment.py )。
在FastSpeech中,培训输入包括梅尔框架和文本令牌的教师对齐。具体而言,它涉及使用MFA在训练之前为每个文本令牌生成MEL框架的duration 。
在WavThruvec中,使用RAD-TTS的MAS生成duration ,并将其送入长度调节器(持续时间预测器)。
根据单调对齐搜索和RAD-TTS实现,当您训练模型时,将在'./data/align_prior'下生成Align-Prior文件,并使用{n_token}_{n_feat}_prior.pth的文件名格式。
aishell3
prepar_data.py:
例如,准备_data.py只需几个扬声器和几个WAV文件。
WavThruvec违反了2个组件:Text2Vec(编码器)和VEC2WAV(解码器),它们独立训练
因此,我将它们放在两个单独的DIRS中,并为每种配置使用了不同的训练配置。
张板记录器存储在run/{log_seed}/tb_logs目录中。假设log_seed=1 ,您可以使用此命令在本地主机上使用张量。
tensorboard --logdir run/1/tb_logs
模型检查点保存在run/{log_seed}/model_new目录中。
假设您每10000迭代保存检查点,现在您有一个检查点checkpoint_10000.pth.tar 。如果您需要在step 10000重新启动培训,请使用此命令。
python ./text2vec/train.py --restore_step 10000


