WavThruVec_pytorch
1.0.0
Неофициальная реализация Wavthruvec на основе Pytorch.
Оригинальная статья - Wavthruvec: скрытое представление речи как промежуточные особенности для синтеза нейронной речи
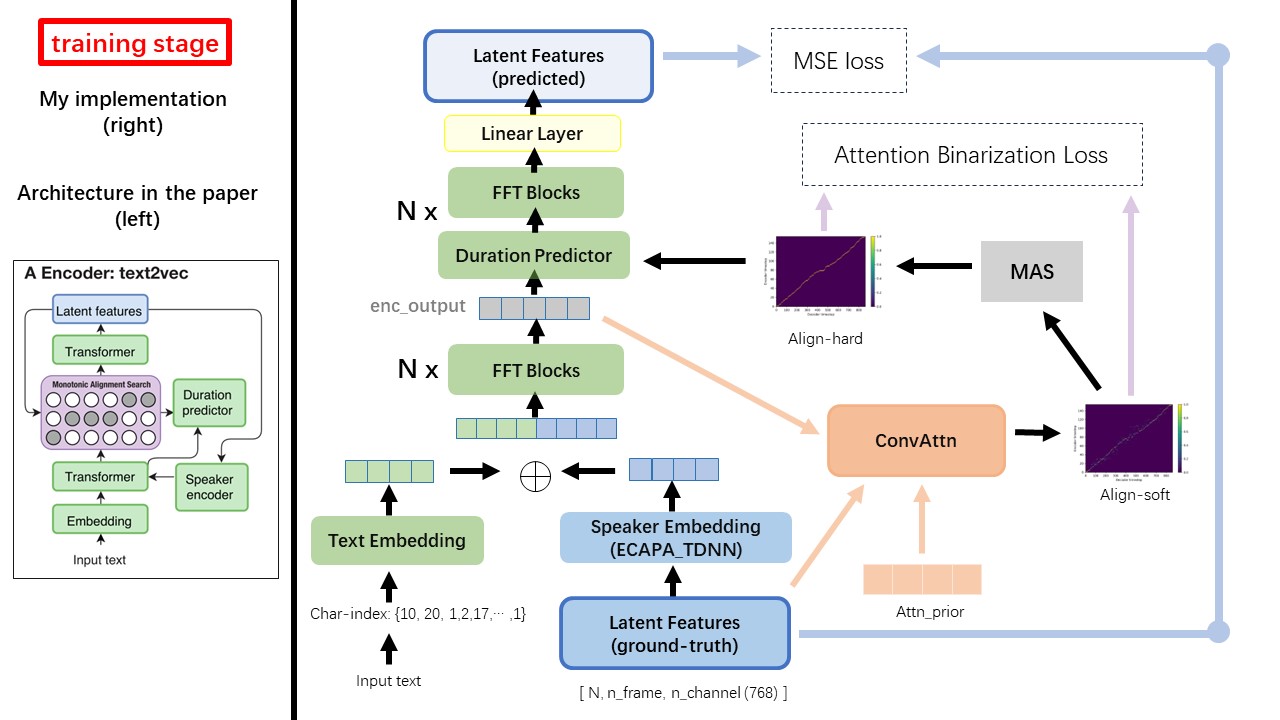
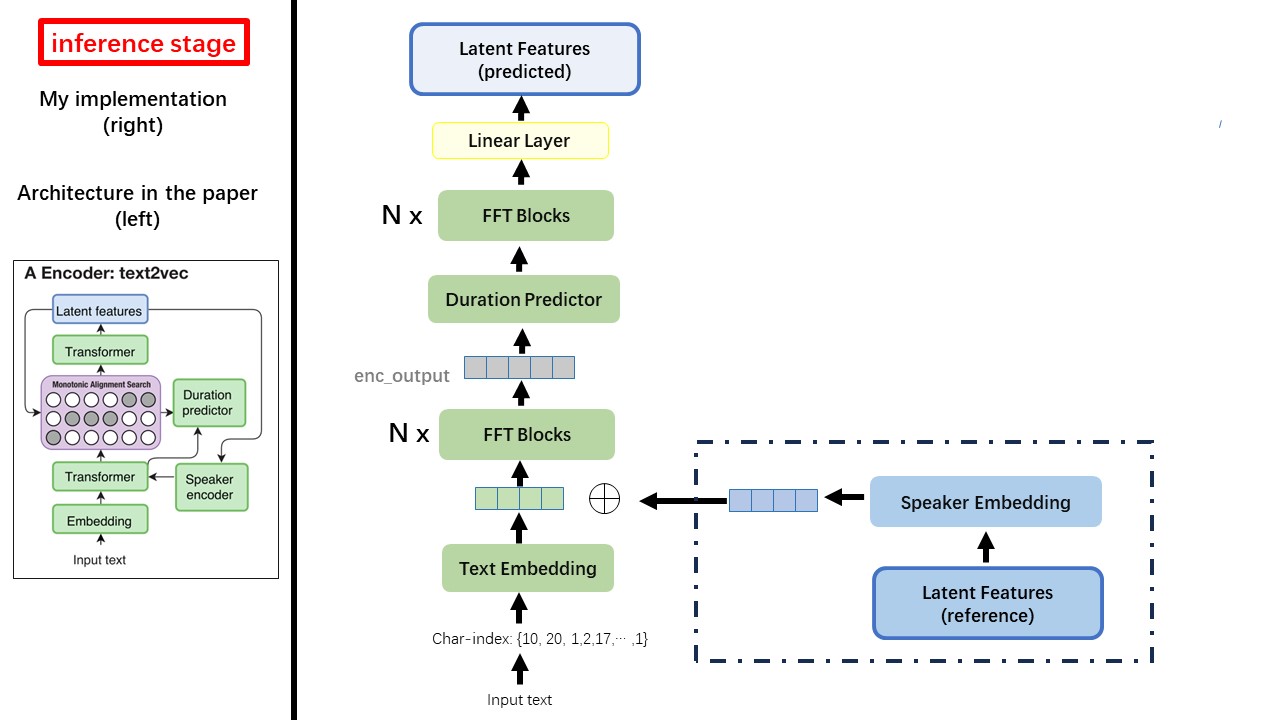
Модель Text2VEC в основном следует архитектуре Fastspeech (XCMYZ). Я изменил модель, в основном на основе RAD-TTS (NVIDIA). И я добавляю ecapa_tdnn в качестве энкодера динамика, для условия многопрофильного.
Для других деталей, не упомянутых в статье, я также следую за RAD-TTS.
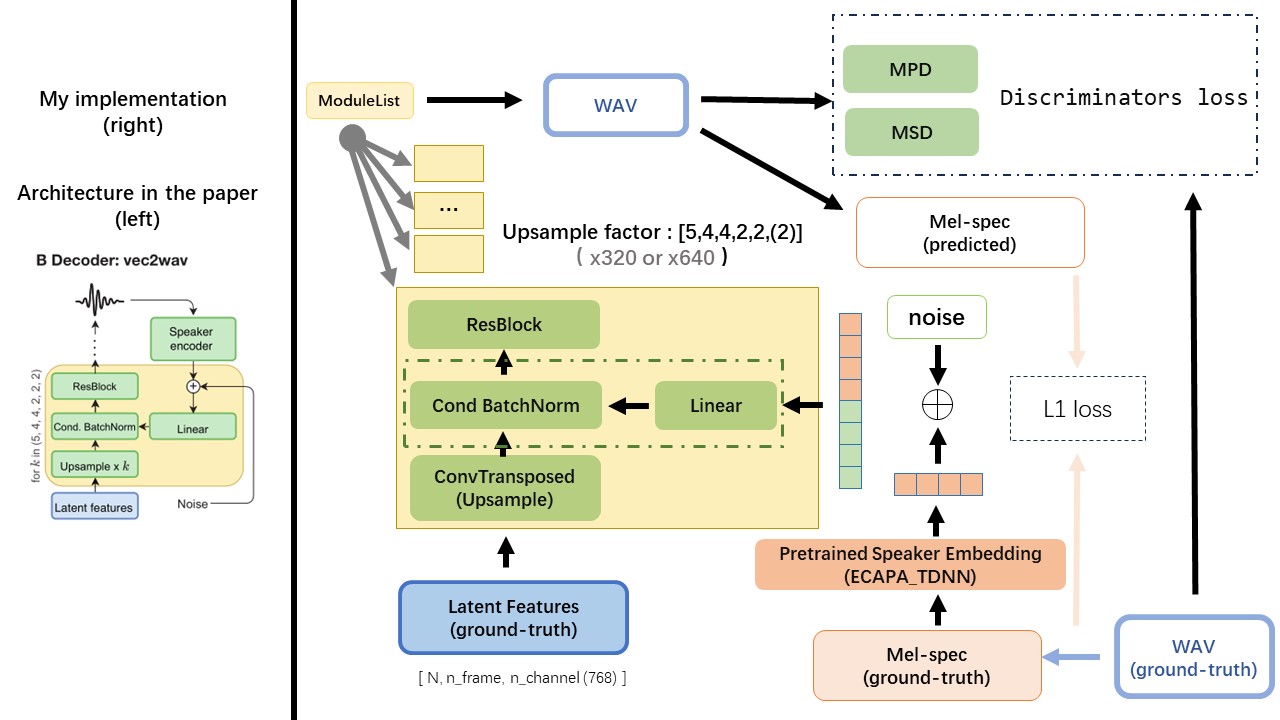
VEC2WAV в основном основан на Hifi-Gan и вводит условную нормализацию партии, чтобы установить сеть в встраивании динамика. Последовательность скоростей повышения квалификации составляет (5,4,4,2,2), поэтому коэффициент повышения дискретизации
Не используйте какие-либо методы нормализации текста или фонемизации на основе правил, но питайте необработанный характер и преобразуйте в стимулирование текста в качестве входных данных.
Используйте выход WAV2VEC 2.0 в качестве функции WAV (вместо спектрограммы MEL), с dtype 'float32' и формой (batch_size, n_frame, n_channel) .
Примечание: N_CHANLER = 768 или 1024, это зависит от того, какая версия предварительно предварительно вытянутой модели WAV2VEC 2.0 вы используете, потому что TencentGamemate предоставляет Fairseq-версию (768) и HuggingFace-Version (1024). Эти две версии имеют различную форму вывода.
Из этого хранилища wav2vec2.0 (предварительное предварительное значение китайской речи), и его также можно найти в Huggingface
Одним из самых больших различий между Wavthruvec и Fastspeech является модуль монотонного поиска выравнивания (MAS) (см. alignment.py ).
В Fastspeech учебные поступления включают выравнивание учителей для рамков MEL и токенов текста. В частности, это включает использование MFA для генерации duration кадров MEL для каждого текста -тона перед тренировкой.
Находясь в Wavthruvec, duration генерируется с использованием MAS от RAD-TTS и подается в длину.
В соответствии с монотонным поиском выравнивания и реализации Rad-TTS, когда вы обучаете модель, файлы Align-Prior будут сгенерированы в каталоге './data/align_prior' с форматом имени файла {n_token}_{n_feat}_prior.pth .
Aishell3
Prepare_Data.py:
Например, Prepare_Data.py Возьмите только несколько динамиков и несколько файлов WAV.
Wavthruvec contrignes 2 компонента: Text2VEC (Encoder) и VEC2WAV (декодер), и они тренируются независимо
Таким образом, я поместил их в два отдельных направления и использовал различные тренировочные конфигурации для каждого.
Логисты Tensorboard хранятся в каталоге run/{log_seed}/tb_logs . Предположим, log_seed=1 , вы можете использовать эту команду, чтобы обслуживать Tensorboard на вашем локальном хосте.
tensorboard --logdir run/1/tb_logs
Контрольные точки модели сохраняются в каталоге run/{log_seed}/model_new .
Предположим, вы сохраняете контрольные точки каждые 10000 итераций, и теперь у вас есть контрольная точка checkpoint_10000.pth.tar . Если вам нужно перезапустить обучение на step 10000 , используйте эту команду.
python ./text2vec/train.py --restore_step 10000


