WavThruVec_pytorch
1.0.0
Eine inoffizielle Implementierung von Wavthruvec basierend auf Pytorch.
Das Originalpapier ist Wavthruvec: Latente Sprachrepräsentation als Zwischenmerkmale für die neuronale Sprachsynthese
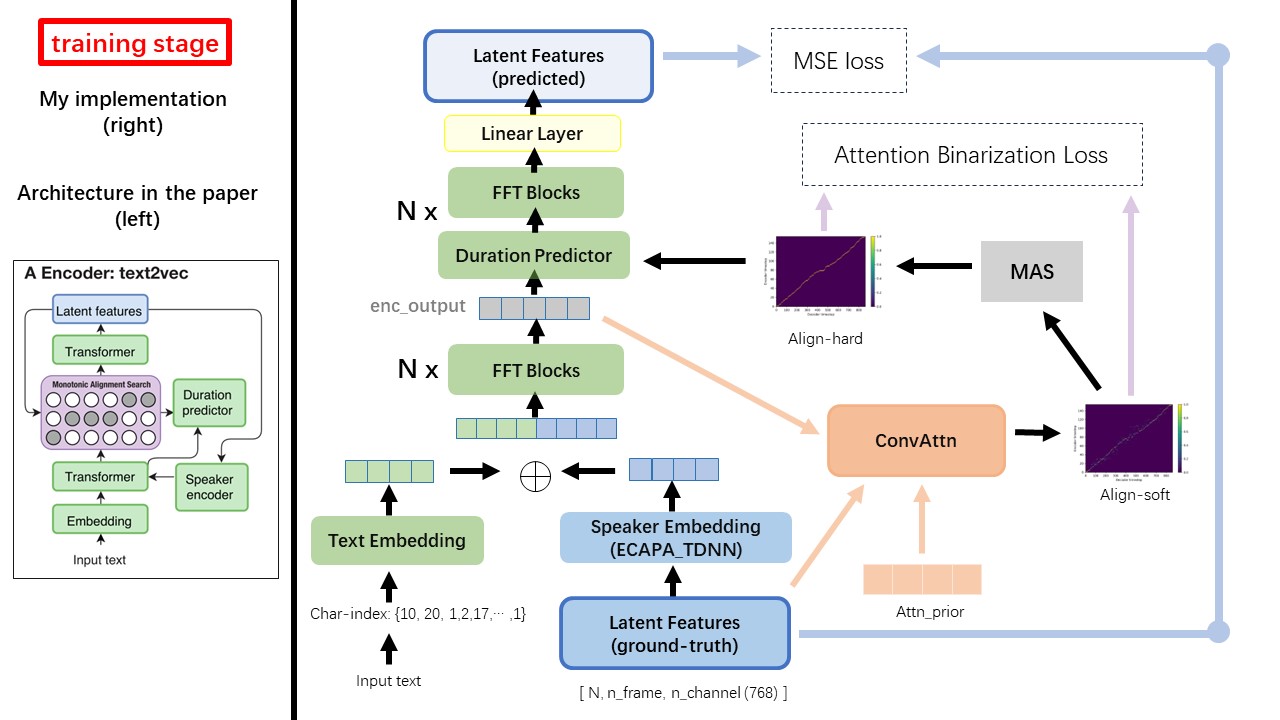
Das Text2VEC -Modell folgt hauptsächlich der Fastspeech -Architektur (XCMYZ). Ich habe das Modell modifiziert, hauptsächlich basierend auf Rad-TTs (NVIDIAs). Und ich füge einen ECAPA_TDNN als Lautsprecher-Encoder für Multi-Sprecher-Zustand hinzu.
Für weitere im Papier nicht erwähnte Details folge ich auch den Rad-TTs.
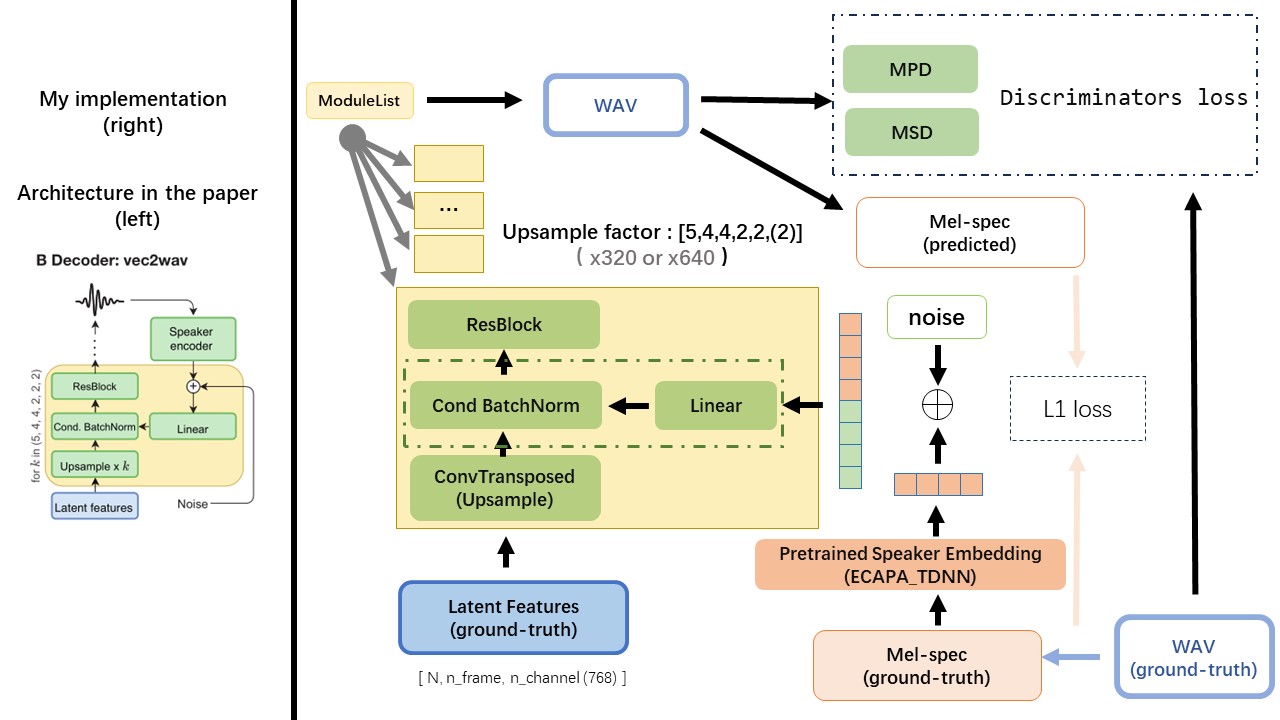
Der VEC2WAV basiert hauptsächlich auf dem Hifi-Gan und führt eine bedingte Chargennormalisierung ein, um das Netzwerk am Einbettung des Sprechers zu stimmen. Die Up -Beispiel -Ratensequenz ist (5,4,4,2,2), sodass der Upsampling -Faktor ist
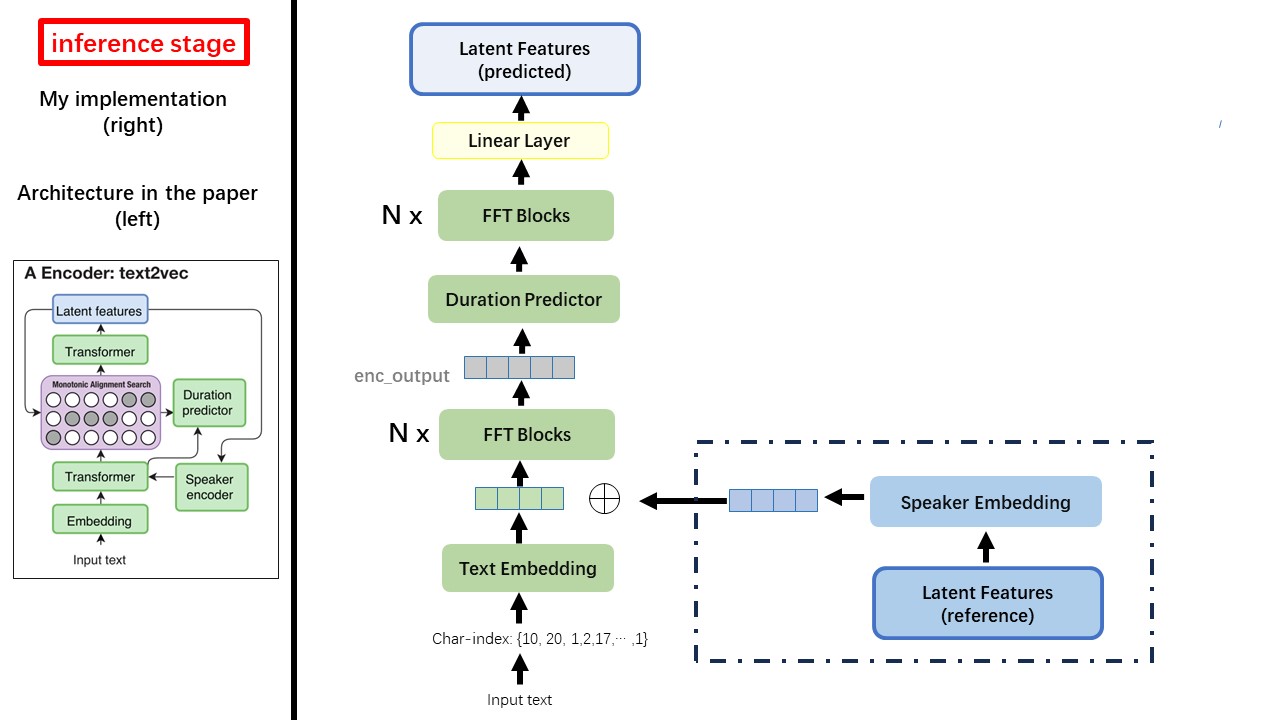
Verwenden Sie keine regelbasierten Textnormalisierung oder Phonemisierungsmethoden, sondern füttern Sie RAW-Zeichen und verwandeln Sie sich als Eingaben in Text-Embedding.
Verwenden Sie die Ausgabe von WAV2VEC 2.0 als WAV -Funktion (anstelle von MEL -Spektrogram) mit einem DTYPE von 'float32' und einer Form von (batch_size, n_frame, n_channel) .
HINWEIS: N_Channel = 768 oder 1024, es hängt davon ab, welche Version des von Ihnen verwendeten WAV2VEC 2.0-Modells, da Tencentgamemate ein FairSeq-Version (768) und die Huggingface-Version (1024) liefert. Diese beiden Versionen hat eine andere Ausgangsform.
Aus diesem Repository WAV2VEC2.0 (chinesischer Sprachvorbereitung) und kann auch bei Huggingface gefunden werden
Einer der größten Unterschiede zwischen Wavthruvec und Fastspeech ist das monotonische Ausrichtungssuchmodul (MAS) (siehe alignment.py ).
In Fastspeech enthalten die Trainingseingaben die Ausrichtung des Lehrers für MEL-Frames und Text-Token. Insbesondere besteht die Verwendung von MFA, um die duration der MEL -Rahmen für jeden Text -Token vor dem Training zu generieren.
Während in Wavthruvc wird die duration unter Verwendung des MAS von den rad-tts erzeugt und in den Langermaterial (Dauerpredictor) eingespeist.
Gemäß der monotonischen Ausrichtungssuche und der RAD-TTS-Implementierung würden nach dem Training des Modells Align-Pro-Prior-Dateien unter './data/align_prior' Verzeichnis mit dem Dateinamenformat von {n_token}_{n_feat}_prior.pth generiert.
Aishell3
Die prepe_data.py:
Preped_data.py nehmen Sie beispielsweise nur ein paar Lautsprecher und ein paar WAV -Dateien.
Wavthruvec -Gegenden 2 Komponenten: Text2VEC (Encoder) und VEC2WAV (Decoder), und sie trainieren unabhängig
Somit habe ich sie in zwei separate Dires platziert und jeweils unterschiedliche Trainingskonfigurationen verwendet.
Die Tensorboard -Logger werden im Verzeichnis run/{log_seed}/tb_logs gespeichert. Nehmen wir an, log_seed=1 , Sie können diesen Befehl verwenden, um das Tensorboard auf Ihrem Localhost zu bedienen.
tensorboard --logdir run/1/tb_logs
Die Modell -Checkpoints werden im Verzeichnis run/{log_seed}/model_new gespeichert.
Angenommen, Sie speichern alle 10000 Iterationen und haben jetzt einen Checkpoint checkpoint_10000.pth.tar . Wenn Sie das Training bei step 10000 neu starten müssen, verwenden Sie diesen Befehl.
python ./text2vec/train.py --restore_step 10000


