WavThruVec_pytorch
1.0.0
تطبيق غير رسمي لـ Wavthruvec على أساس Pytorch.
الورقة الأصلية هي Wavthruvec: تمثيل الكلام الكامن كسمات وسيطة لتوليف الكلام العصبي
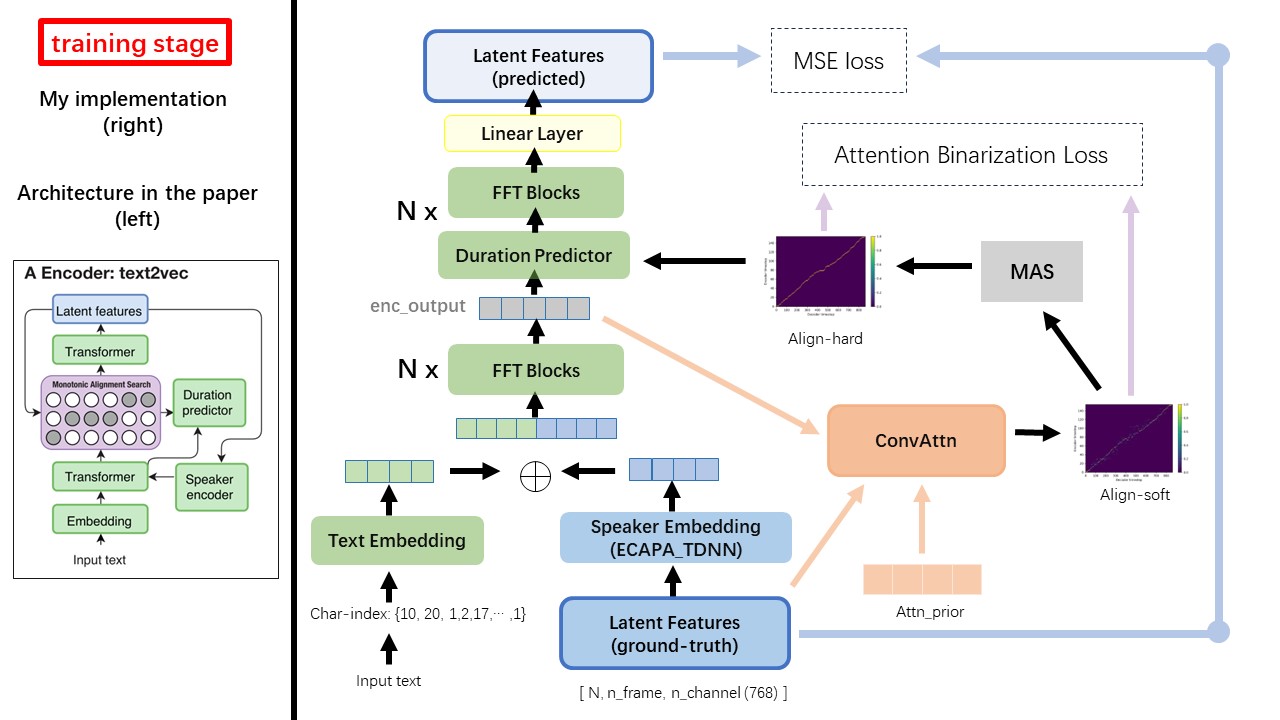
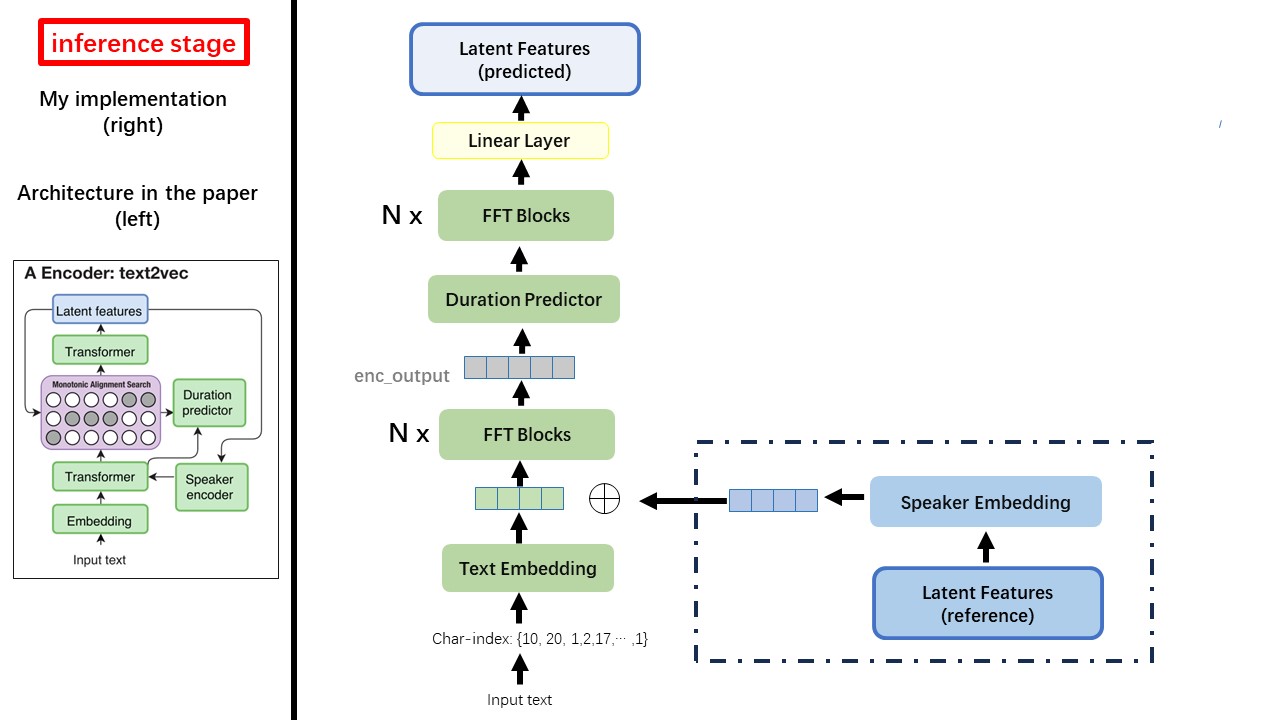
يتبع نموذج Text2VEC في الغالب بنية Fastspeech (xcmyz's). لقد قمت بتعديل النموذج ، بشكل رئيسي على RAD-TTS (NVIDIA'S). وأضيف ECAPA_TDNN كمشفر مكبر صوت ، لحالة Multi-Speaker.
للحصول على تفاصيل أخرى لم يتم ذكرها في الورقة ، أتابع أيضًا RAD-TTS.
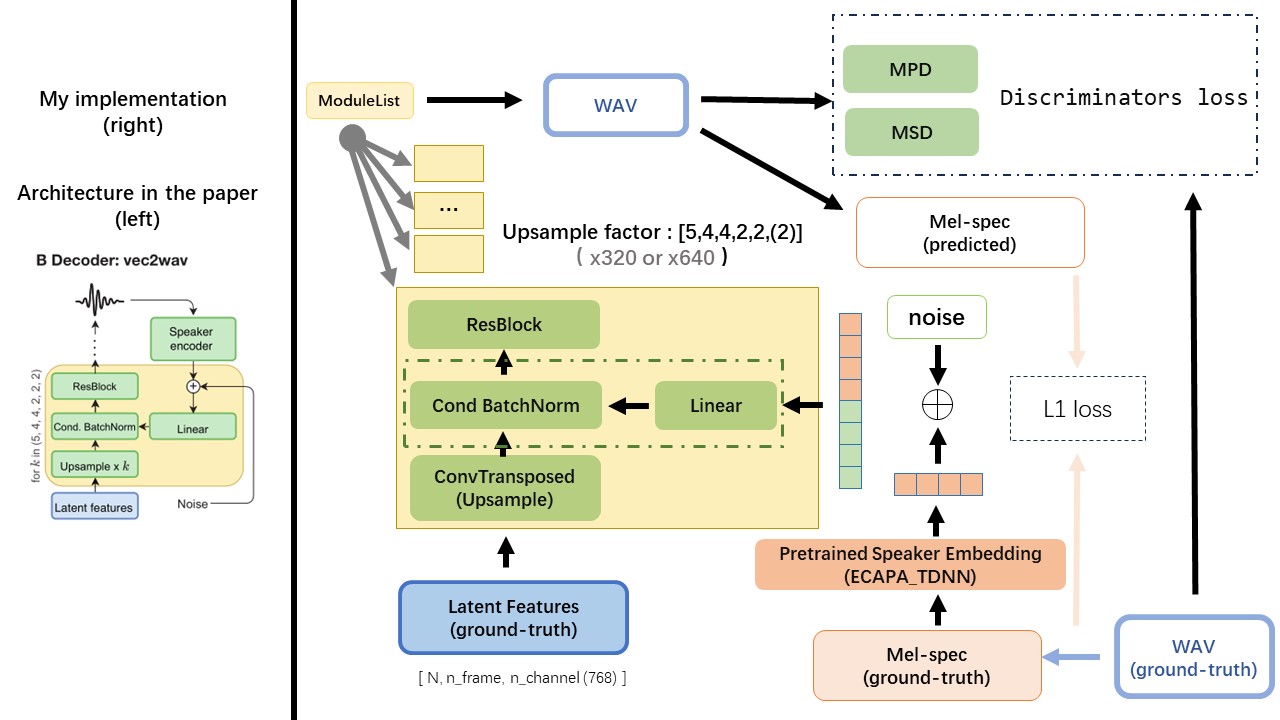
يعتمد VEC2WAV في الغالب على HIFI-GAN ، ويقدم تطبيع الدُفعات الشرطية لشرط الشبكة على تضمين السماعة. تسلسل معدلات upsample هو (5،4،4،2،2) وبالتالي فإن عامل التخطي هو
لا تستخدم أي طرق تطبيع نص أو صوتية مستندة إلى القواعد ، ولكن تغذية الحرف الخام والتحول إلى إبطال النصوص كمدخلات.
استخدم إخراج WAV2VEC 2.0 كميزة WAV (بدلاً من طيف MEL) ، مع DTYPE من 'float32' وشكل (batch_size, n_frame, n_channel) .
ملاحظة: N_Channel = 768 أو 1024 ، يعتمد على إصدار نموذج WAV2VEC 2.0 الذي تستخدمه ، لأن TencentGamemate توفر Vistseq-Version (768) و Unggingface-Version (1024). هذين الإصدارين له شكل إخراج مختلف.
من هذا المستودع WAV2VEC2.0 (خطاب الكلام الصيني قبل) ، ويمكن العثور عليه أيضًا في Huggingface
أحد أكبر الفرق بين Wavthruvec و Fastspeech هو وحدة البحث عن المحاذاة الرتابة (MAS) (راجع إلى alignment.py ).
في Fastspeech ، تشمل مدخلات التدريب محاذاة للمعلم لإطارات MEL ورموز النص. على وجه التحديد ، يتضمن استخدام MFA لإنشاء duration إطارات MEL لكل رمز نصية قبل التدريب.
أثناء وجوده في WavThruvec ، يتم إنشاء duration باستخدام MAS من RAD-TTS ، ويتم تغذيتها في الطول (المدة).
وفقًا لبحث المحاذاة الرتيب وتطبيق RAD-TTS ، عند تدريب النموذج ، سيتم إنشاء ملفات محاذاة ضمن './data/align_prior' {n_token}_{n_feat}_prior.pth
Aishell3
repars_data.py:
على سبيل المثال ، قم بإعداد _data.py فقط تأخذ بعض المتحدثين وبعض ملفات WAV.
WavThruvec يناقض مكونان: Text2Vec (التشفير) و VEC2WAV (فك ترميز) ، ويتدربون بشكل مستقل
وهكذا ، وضعت لهم في اثنين من dips منفصلة واستخدمت تكوينات التدريب المختلفة لكل منهما.
يتم تخزين سجلات Tensorboard في دليل run/{log_seed}/tb_logs . لنفترض log_seed=1 ، يمكنك استخدام هذا الأمر لخدمة Tensorboard على مضيفك المحلي.
tensorboard --logdir run/1/tb_logs
يتم حفظ نقاط التفتيش النموذجية في دليل run/{log_seed}/model_new .
افترض أنك حفظ نقاط التفتيش كل 10000 تكرار ، والآن لديك نقطة تفتيش نقطة checkpoint_10000.pth.tar . إذا كنت بحاجة إلى إعادة تشغيل التدريب في step 10000 ، فاستخدم هذا الأمر.
python ./text2vec/train.py --restore_step 10000


