WavThruVec_pytorch
1.0.0
Pytorch를 기반으로하는 Wavthruvec의 비공식 구현.
원래 논문은 신경 언어 합성을위한 중간 특징으로서 Wavthruvec : 잠재적 인 언어 표현입니다.
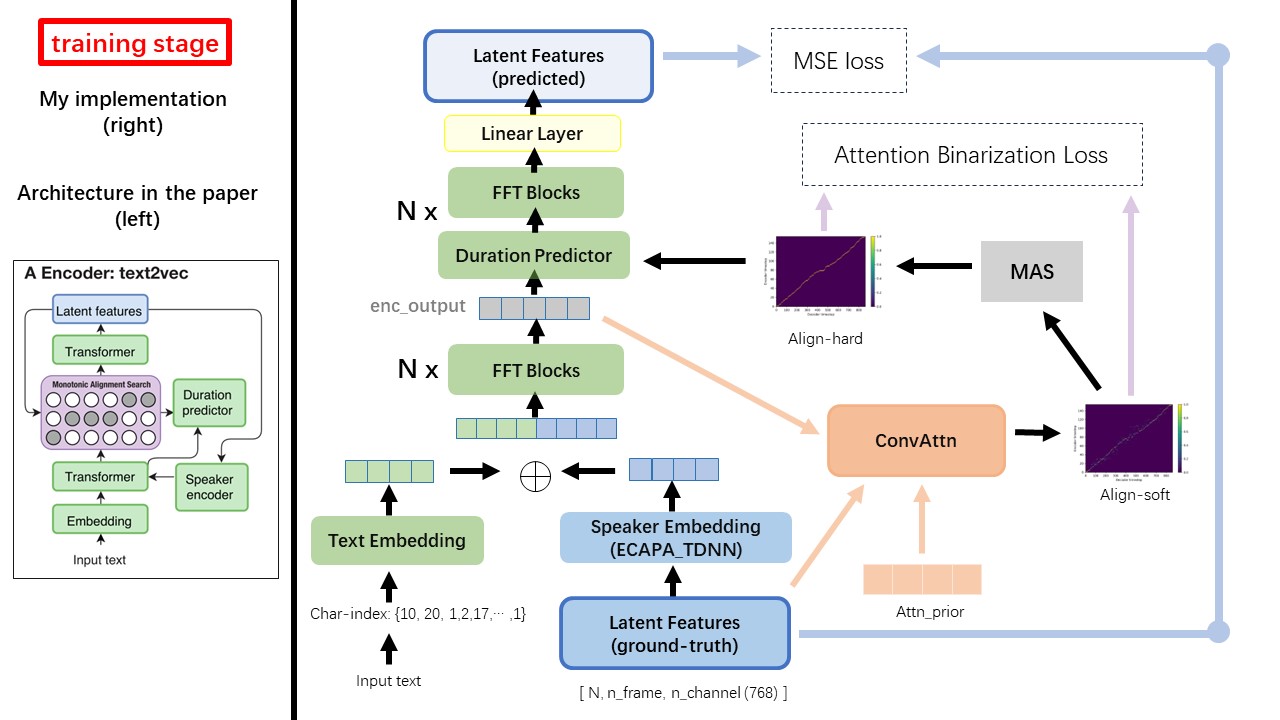
Text2Vec 모델은 주로 FastSpeech (Xcmyz) 아키텍처를 따릅니다. 주로 RAD-TTS (NVIDIA 's)를 기반으로 모델을 수정했습니다. 그리고 다중 스피커 상태를 위해 스피커 인코더로 ecapa_tdnn을 추가합니다.
논문에 언급되지 않은 다른 세부 사항은 또한 RAD-TTS를 따릅니다.
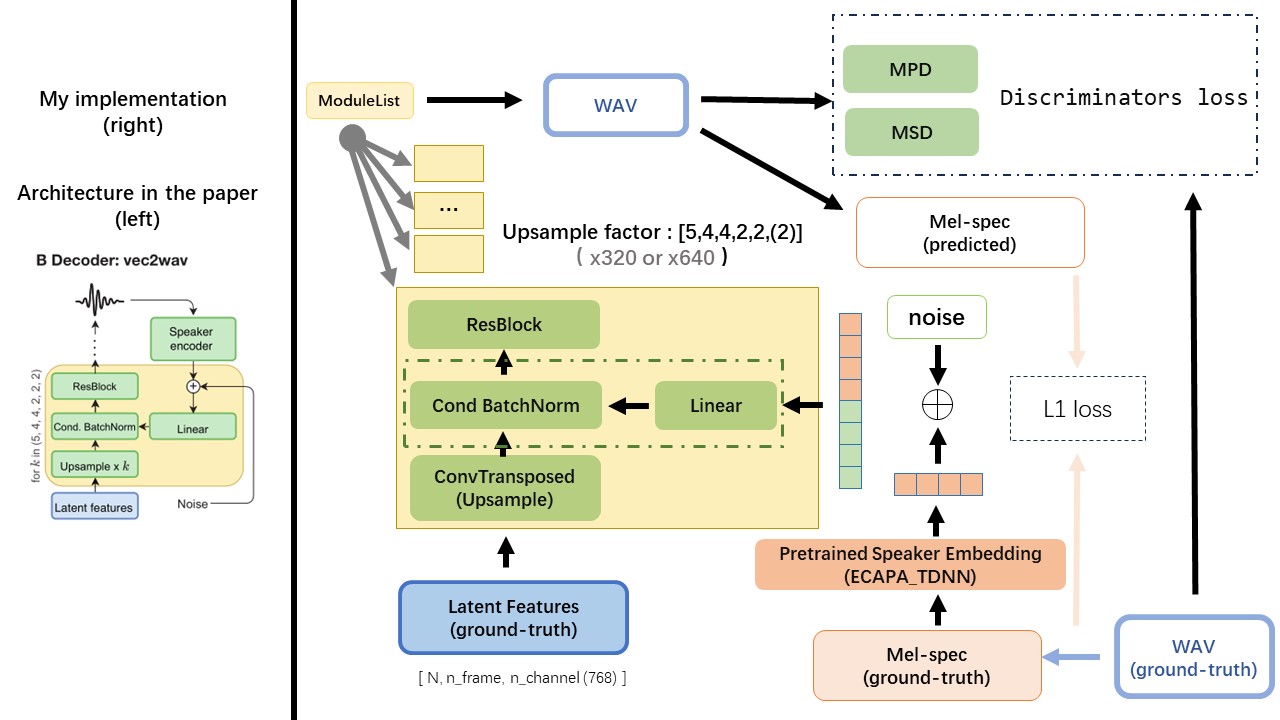
VEC2WAV는 주로 Hifi-Gan을 기반으로하며 조건부 배치 정규화를 도입하여 스피커 임베딩의 네트워크를 조절합니다. 상향 샘플 속도 시퀀스는 (5,4,2,2)이므로 업 샘플링 계수는 다음과 같습니다.
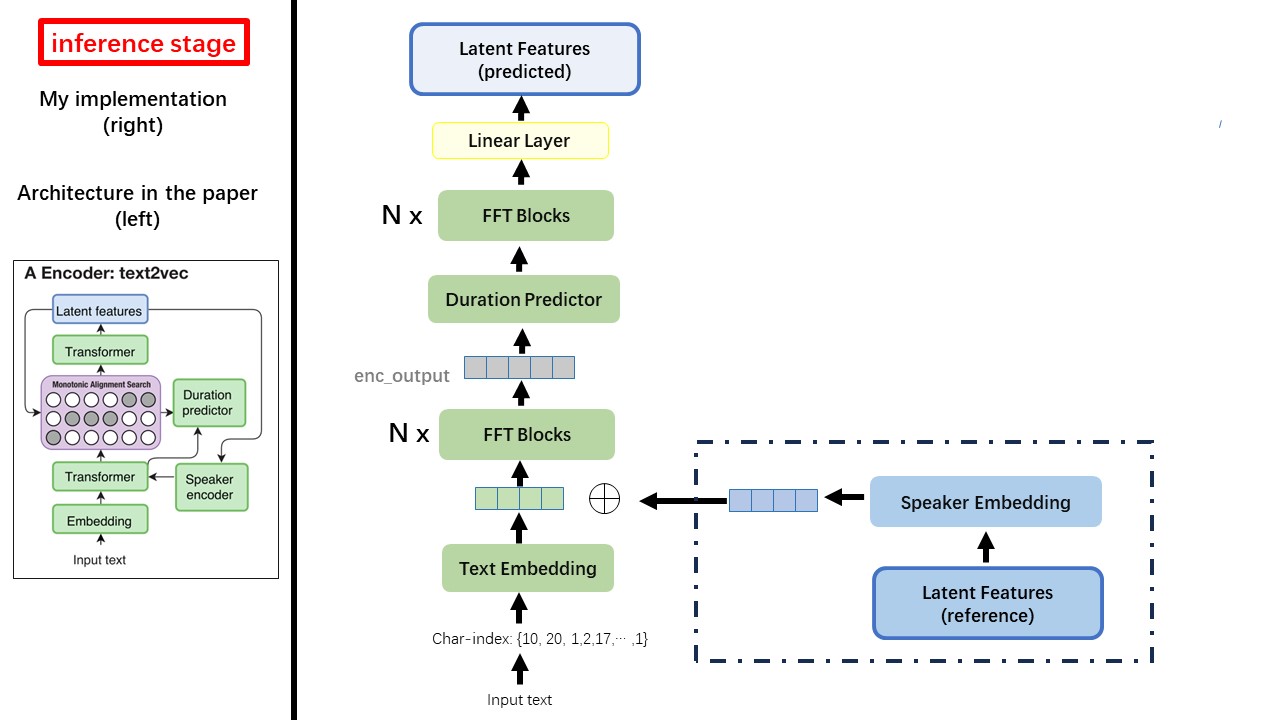
규칙 기반 텍스트 정규화 또는 음운화 방법을 사용하지 말고 원시 문자를 공급하고 입력으로 텍스트 엠 베딩으로 변환하십시오.
Wav2Vec 2.0의 출력을 'float32' 의 dtype와 (batch_size, n_frame, n_channel) 의 dtype와 함께 WAV의 기능 (Mel Spectrogram 대신)으로 사용하십시오.
참고 : n_channel = 768 또는 1024, tencentgamemate가 fairseq-version (768)과 huggingface-version (1024)을 제공하기 때문에 사용중인 WAV2VEC 2.0 사기 모델의 버전에 따라 다릅니다. 이 두 버전마다 출력 모양이 다릅니다.
이 저장소 WAV2VEC2.0 (중국어 연설 프리 트레인)에서 HuggingFace에서도 찾을 수 있습니다.
Wavthruvec과 FastSpeech의 가장 큰 차이점 중 하나는 MAS (Monotonic Alignment Search) 모듈 ( alignment.py 참조)입니다.
FastSpeech에서 훈련 입력에는 Mel 프레임 및 텍스트 토큰에 대한 교사를위한 정렬이 포함됩니다. 구체적으로, MFA를 사용하여 훈련 전에 각 텍스트 토큰의 MEL 프레임 duration 생성하는 것이 포함됩니다.
Wavthruvec에서는 RAD-TTS의 MAS를 사용하여 duration 생성되며 Lengthregulator (DurationPredictor)에 공급됩니다.
Monotonic Alignment Search 및 RAD-TTS 구현에 따르면, 모델을 훈련 할 때 {n_token}_{n_feat}_prior.pth 의 파일 이름 형식과 함께 './data/align_prior' 디렉토리에서 정렬 파일이 생성됩니다.
Aishell3
repay_data.py :
예를 들어, repay_data.py는 스피커와 몇 개의 wav 파일 만 가져옵니다.
WAVTHRUVEC는 2 개의 구성 요소를 대출합니다 : Text2Vec (Encoder) 및 Vec2wav (Decoder), 독립적으로 훈련
따라서, 나는 그것들을 두 개의 별도의 DIRS에 배치하고 각각에 대해 다른 훈련 구성을 사용했습니다.
Tensorboard 로거는 run/{log_seed}/tb_logs 디렉토리에 저장됩니다. log_seed=1 이라고 가정하면이 명령을 사용하여 LocalHost의 Tensorboard를 제공 할 수 있습니다.
tensorboard --logdir run/1/tb_logs
모델 체크 포인트는 run/{log_seed}/model_new 디렉토리에 저장됩니다.
10000 회 반복마다 검문소를 저장한다고 가정하고 이제 체크 포인트 checkpoint_10000.pth.tar 가 있습니다. step 10000 에서 교육을 다시 시작 해야하는 경우이 명령을 사용하십시오.
python ./text2vec/train.py --restore_step 10000


