WavThruVec_pytorch
1.0.0
Una implementación no oficial de Wavthruvec basada en Pytorch.
El documento original es Wavthruvec: representación latente del habla como características intermedias para la síntesis de habla neuronal
El modelo Text2Vec sigue principalmente la arquitectura FastSpeech (XCMYZ). Modifiqué el modelo, principalmente basado en RAD-TTS (NVIDIA). Y agrego un ECAPA_TDNN como codificador de altavoces, para la condición de múltiples altas.
Para otros detalles no mencionados en el documento, también sigo el RAD-TTS.
El VEC2WAV se basa principalmente en el Hifi-Gan e introduce la normalización de lotes condicionales para acondicionar la red en la inclusión del altavoz. La secuencia de tasas de muestra de altibajos es (5,4,4,2,2), por lo que el factor de muestreo ascendente es
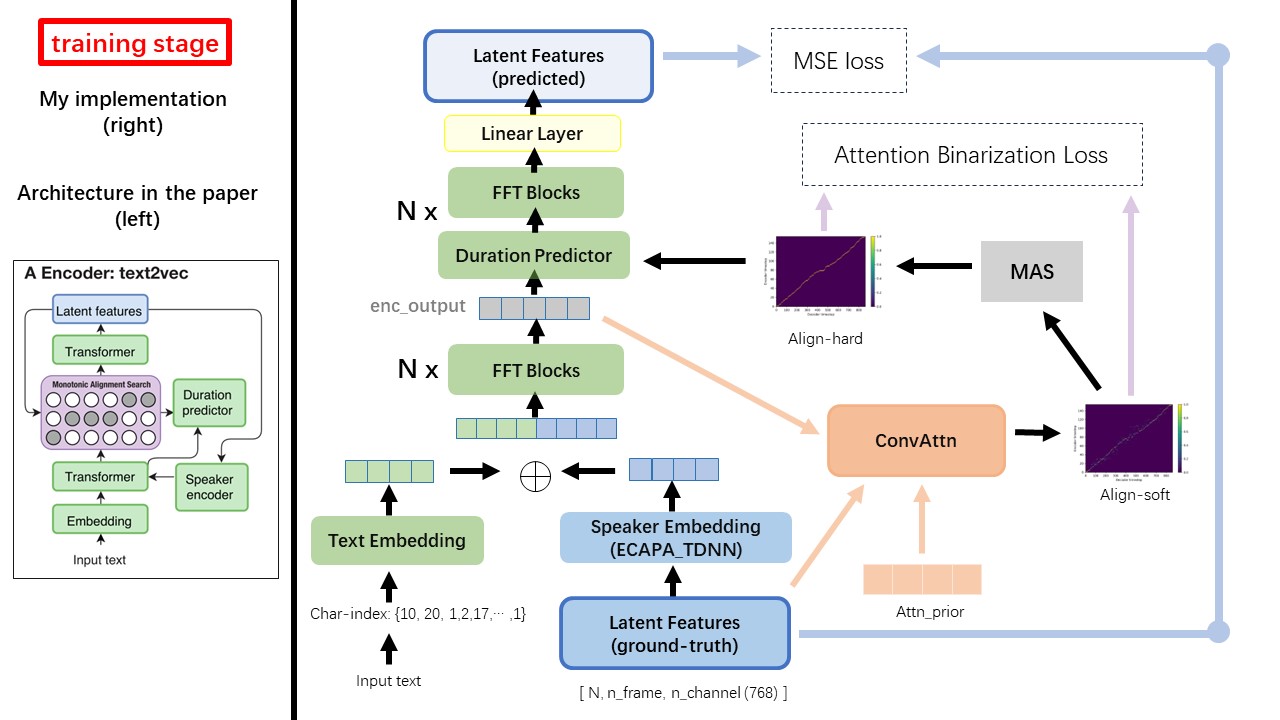
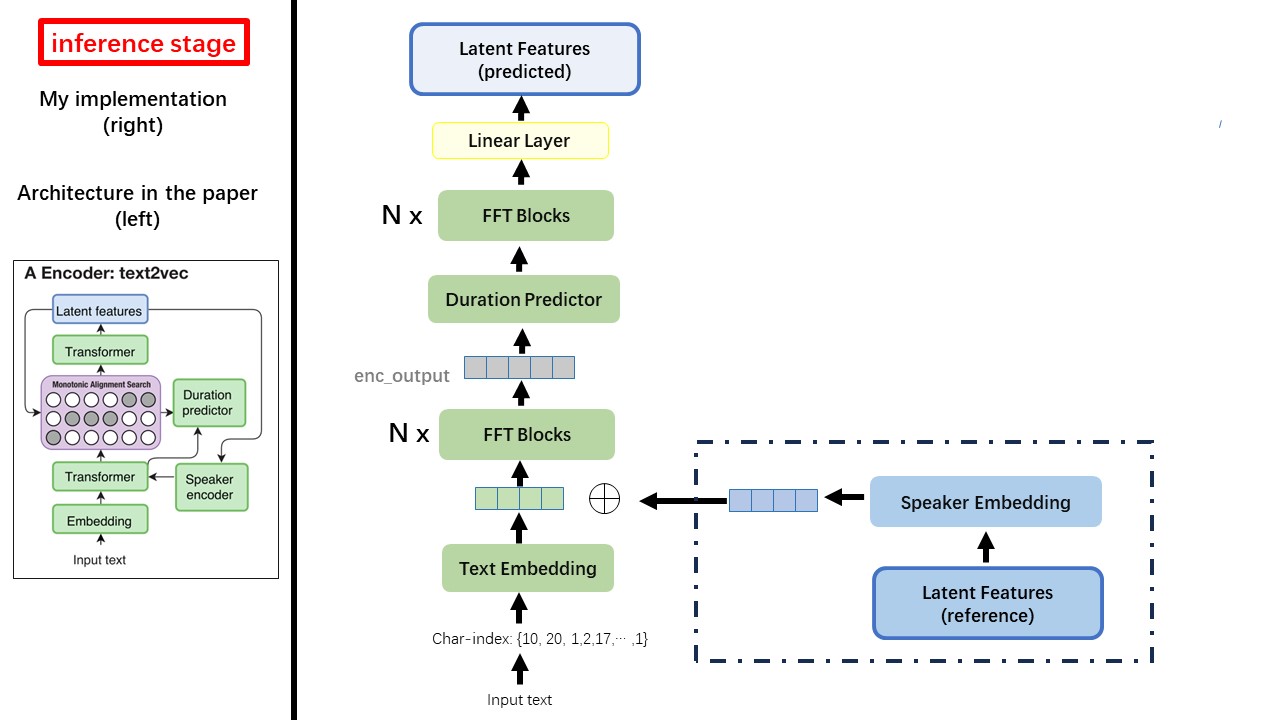
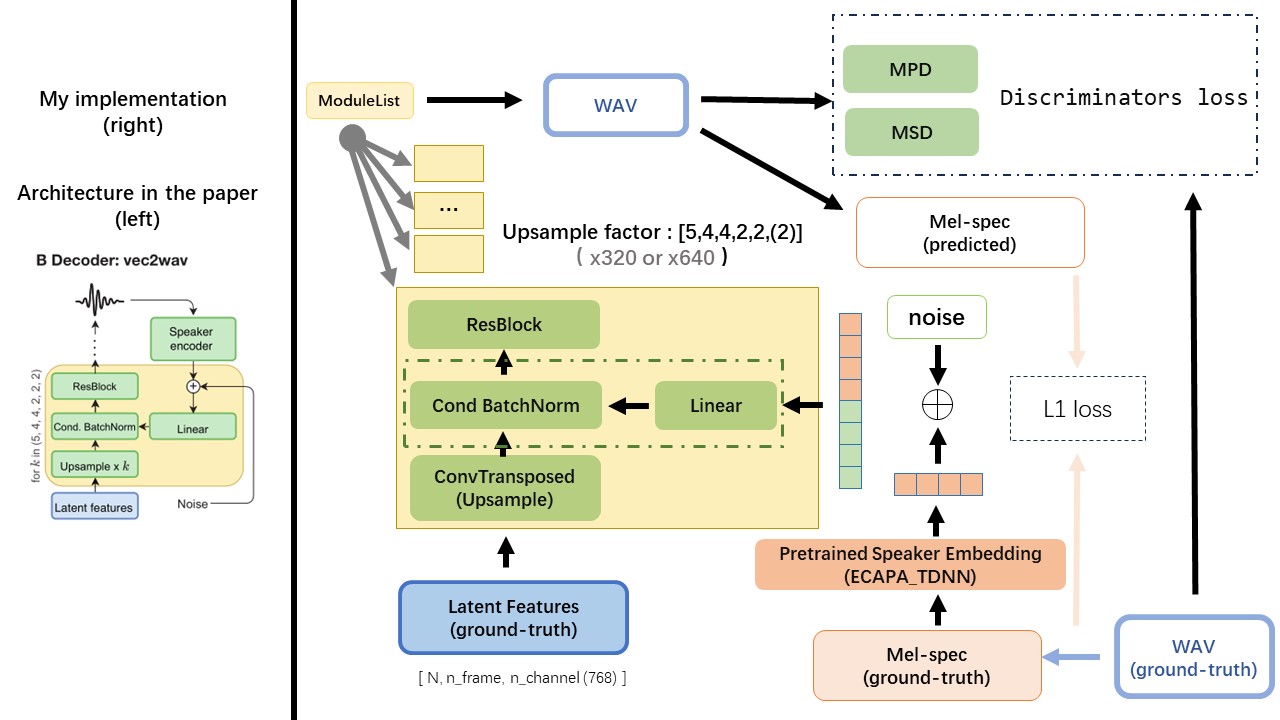
No use ningún método de normalización o fonemización de texto basado en reglas, sino que alimente el carácter sin procesar y se transforme en incrustaciones de texto como entradas.
Use la salida WAV2VEC 2.0 como la función de WAV (en lugar del espectrograma MEL), con un dtype de 'float32' y una forma de (batch_size, n_frame, n_channel) .
Nota: N_Channel = 768 o 1024, depende de qué versión del modelo previamente pracricado WAV2VEC 2.0 esté utilizando, porque Tencentgamemate proporciona a FairSeq-Version (768) y a la versión de la cara de abrazo (1024). Estas dos versión tienen una forma de salida diferente.
De este repositorio WAV2VEC2.0 (pretrano del habla chino), y también se puede encontrar en Huggingface
Una de las mayores diferencia entre Wavthruvec y FastSpeech es el módulo de búsqueda de alineación monotónica (MAS) (consulte el alignment.py ).
En FastSpeech, las entradas de capacitación incluyen la alineación de los maestros para los marcos MEL y los tokens de texto. Específicamente, implica el uso de MFA para generar la duration de los marcos MEL para cada token de texto antes del entrenamiento.
Mientras que en Wavthruvec, la duration se genera utilizando el MAS de los RAD-TTS, y se alimenta al LongitudeRregulador (DuraciónPredictor).
De acuerdo con la búsqueda de alineación monotónica y la implementación de RAD-TTS, cuando capacita el modelo, los archivos Align-Prior se generarían en el directorio './data/align_prior' , con el formato de nombre de archivo de {n_token}_{n_feat}_prior.pth .
Aishell3
El prepare_data.py:
Como ejemplo, prepare_data.py solo tome algunos altavoces y algunos archivos WAV.
Wavthruvec contrata 2 componentes: Text2Vec (codificador) y VEC2WAV (decodificador), y entrenan de forma independiente
Por lo tanto, los coloqué en dos Dirs separados y usé diferentes configuraciones de entrenamiento para cada una.
Los registradores de tensorboard se almacenan en el directorio run/{log_seed}/tb_logs . Supongamos que log_seed=1 , puede usar este comando para servir la placa tensor en su localhost.
tensorboard --logdir run/1/tb_logs
Los puntos de control del modelo se guardan en el directorio run/{log_seed}/model_new .
Supongamos que guarda los puntos de control cada 10000 iteraciones, y ahora tiene un punto de control checkpoint_10000.pth.tar . Si necesita reiniciar la capacitación en step 10000 , use este comando.
python ./text2vec/train.py --restore_step 10000


