WavThruVec_pytorch
1.0.0
An Unofficial Implementation of WavThruVec Based on Pytorch.
The original paper is WavThruVec: Latent speech representation as intermediate features for neural speech synthesis
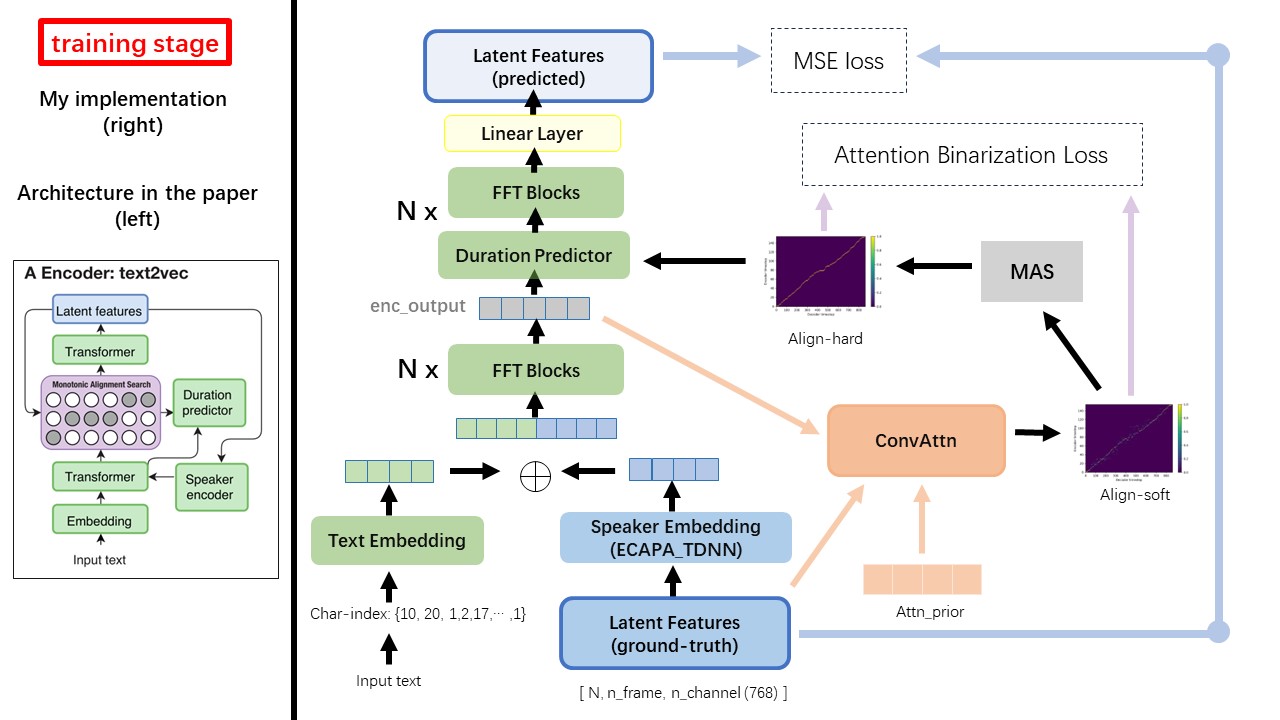
The Text2Vec model mostly follows the fastspeech (xcmyz's) architecture. I modified the model, mainly based on rad-tts (nvidia's). And I add an ECAPA_TDNN as speaker encoder, for multi-speaker condition.
For other details not mentioned in the paper, I also follow the rad-tts.
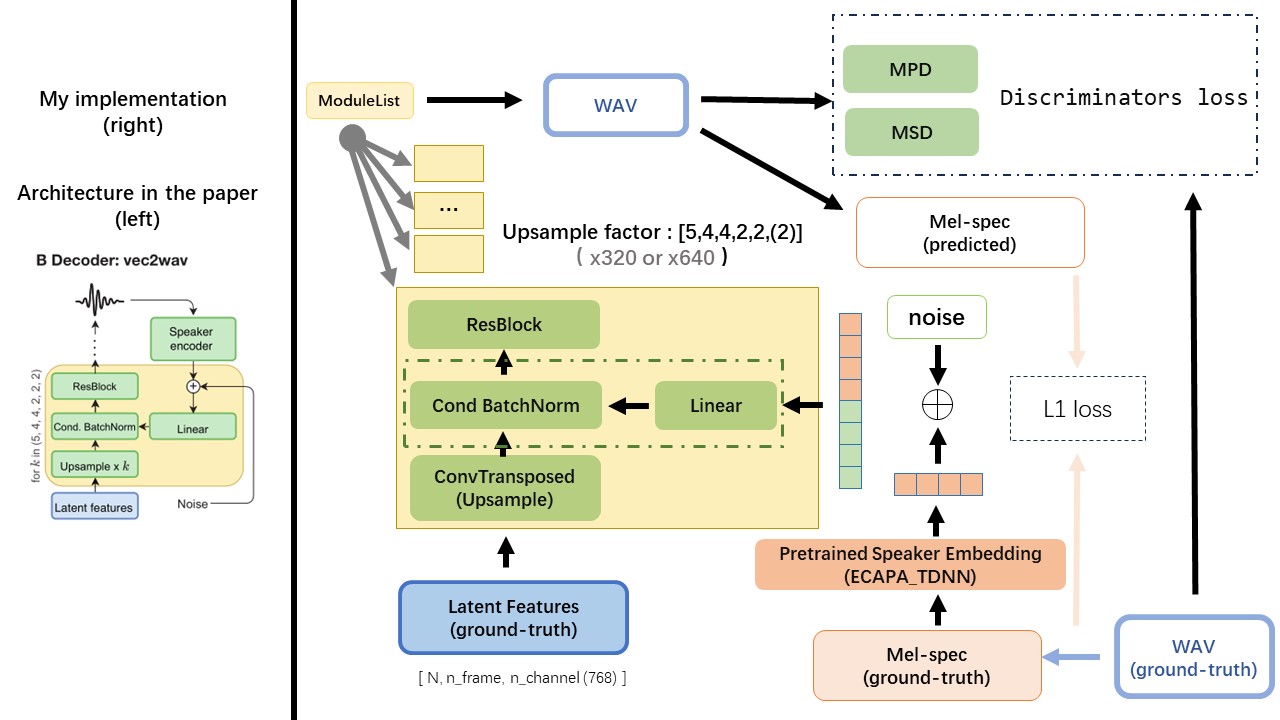
The Vec2Wav is mostly based on the hifi-gan, and introduce Conditional Batch Normalization to condition the network on the speaker embedding. The upsample rates sequence is (5,4,4,2,2) so the upsampling factor is
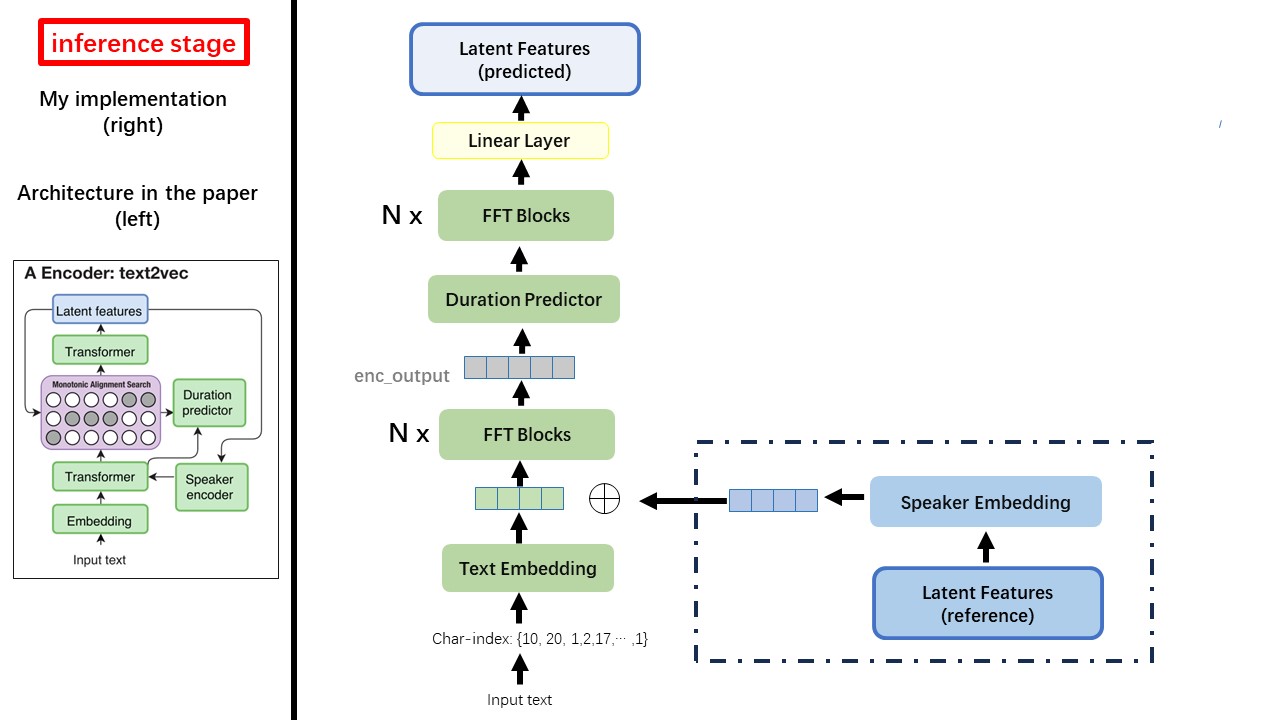
Do not use any rule-based text normalization or phonemization methods, but feed raw character and transform to text-embedding as inputs.
Use wav2vec 2.0's output as the wav's feature(instead of mel spectrogram), with a dtype of 'float32' and a shape of (batch_size, n_frame, n_channel).
note: n_channel=768 or 1024, it depends on which version of the wav2vec 2.0 pretrained model you are using, because TencentGameMate provide fairseq-version(768) and huggingface-version(1024). These two version has different output shape.
From this repository wav2vec2.0 (chinese speech pretrain), and it can also be found at huggingface
One of the biggest difference between WavThruVec and FastSpeech is the monotonic alignment search(MAS) module (refer to the alignment.py).
In FastSpeech, the training inputs include Teacher-Forcing Alignment for mel frames and text tokens. Specifically, it involves using MFA to generate the duration of mel frames for each text token before training.
While in WavThruVec, the duration is generated using the MAS from the rad-tts, and is fed into the LengthRegulator(DurationPredictor).
According to monotonic alignment search and rad-tts implementation, when you training the model, align-prior files would be generated under './data/align_prior' directory, with the file name format of {n_token}_{n_feat}_prior.pth.
aishell3
The prepare_data.py:
As an example, prepare_data.py only take a few speakers and a few wav files.
WavThruVec contrains 2 components: Text2Vec(encoder) and Vec2Wav(decoder), and they train independently
Thus, I placed them in two separate dirs and used different training configurations for each.
The TensorBoard loggers are stored in the run/{log_seed}/tb_logs directory.
Suppose log_seed=1, you can use this command to serve the TensorBoard on your localhost.
tensorboard --logdir run/1/tb_logs
The model checkpoints are saved in the run/{log_seed}/model_new directory.
Suppose you save checkpoints every 10000 iterations, and now you have a checkpoint checkpoint_10000.pth.tar.
If you need to restart training at step 10000, then use this command.
python ./text2vec/train.py --restore_step 10000


