WavThruVec_pytorch
1.0.0
การดำเนินการอย่างไม่เป็นทางการของ wavthruvec ตาม pytorch
บทความต้นฉบับคือ wavthruvec: การแสดงการพูดแฝงเป็นคุณสมบัติกลางสำหรับการสังเคราะห์การพูดของระบบประสาท
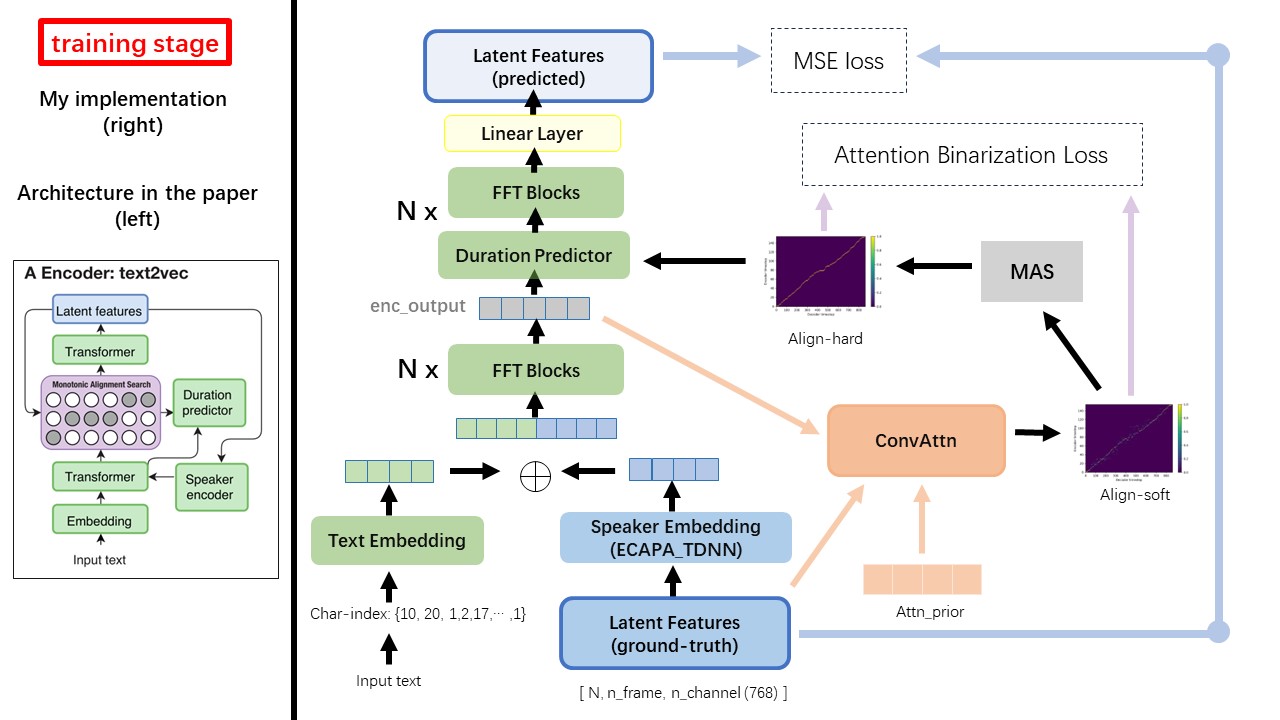
โมเดล Text2Vec ส่วนใหญ่เป็นไปตามสถาปัตยกรรม FastSpeech (XCMYZ) ฉันแก้ไขโมเดลส่วนใหญ่ขึ้นอยู่กับ Rad-TTS (Nvidia's) และฉันเพิ่ม ecapa_tdnn เป็นตัวเข้ารหัสลำโพงสำหรับเงื่อนไขหลายลำโพง
สำหรับรายละเอียดอื่น ๆ ที่ไม่ได้กล่าวถึงในกระดาษฉันยังทำตาม rad-tts
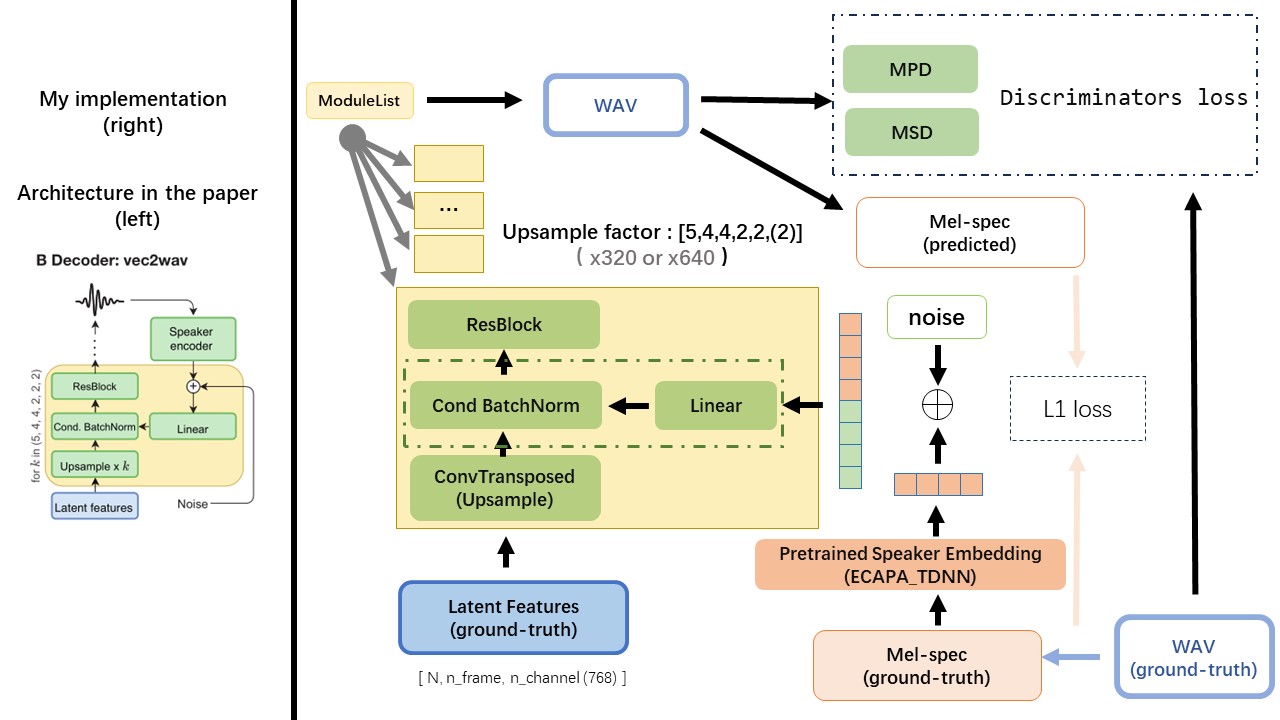
VEC2WAV ส่วนใหญ่ขึ้นอยู่กับ HIFI-GAN และแนะนำการทำให้เป็นมาตรฐานแบบมีเงื่อนไขเพื่อปรับสภาพเครือข่ายในการฝังลำโพง ลำดับอัตราการเพิ่มขึ้นคือ (5,4,4,2,2) ดังนั้นปัจจัยการสุ่มตัวอย่างคือ
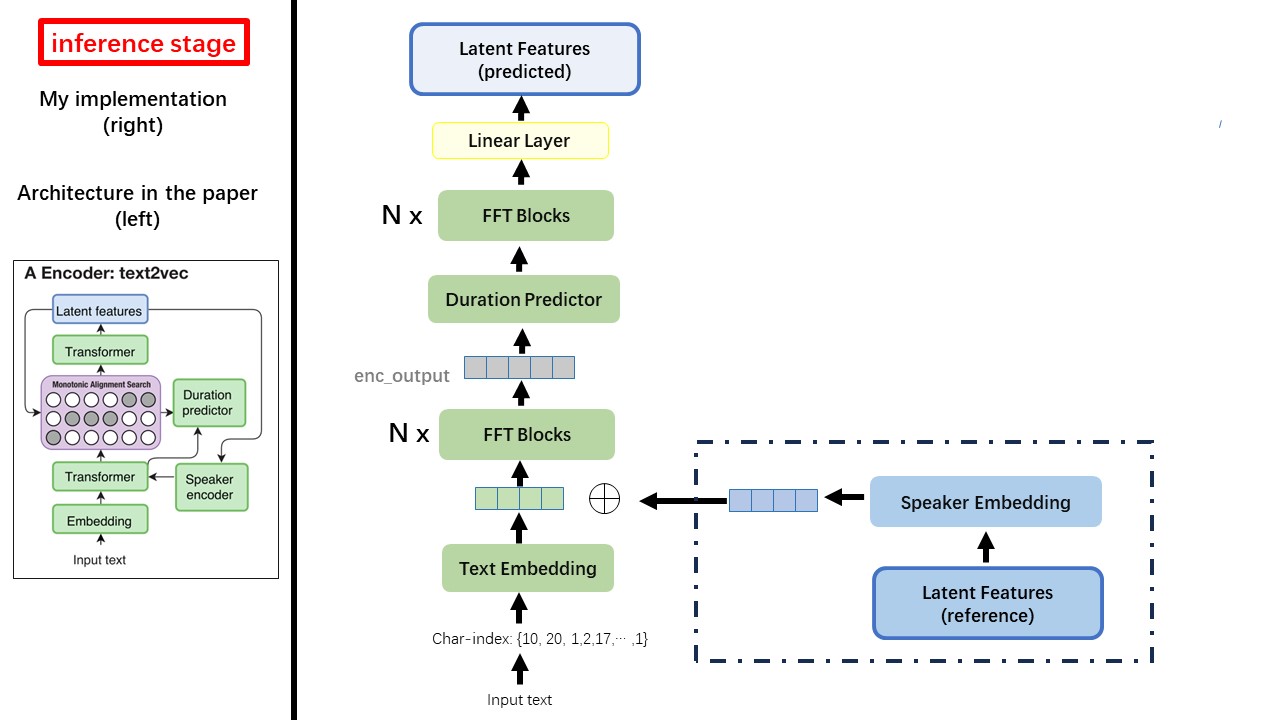
อย่าใช้วิธีการทำให้เป็นปกติของข้อความตามกฎหรือวิธีการออกเสียง แต่ฟีดอักขระดิบและเปลี่ยนเป็นการฝังตัวข้อความเป็นอินพุต
ใช้เอาต์พุตของ WAV2VEC 2.0 เป็นคุณสมบัติของ WAV (แทนที่จะเป็น MEL spectrogram) โดยมี dtype ของ 'float32' และรูปร่างของ (batch_size, n_frame, n_channel)
หมายเหตุ: N_Channel = 768 หรือ 1024 ขึ้นอยู่กับรุ่นที่คุณใช้ WAV2VEC 2.0 เวอร์ชันใดเนื่องจาก TencentGamemate ให้ Fairseq-Version (768) และ HuggingFace-Version (1024) ทั้งสองรุ่นนี้มีรูปร่างเอาต์พุตที่แตกต่างกัน
จากพื้นที่เก็บข้อมูลนี้ WAV2VEC2.0 (คำพูดภาษาจีน) และยังสามารถพบได้ที่ HuggingFace
หนึ่งในความแตกต่างที่ยิ่งใหญ่ที่สุดระหว่าง Wavthruvec และ Fastspeech คือโมดูลการจัดตำแหน่งแบบ monotonic (MAS) (อ้างอิงถึง alignment.py )
ใน Fastspeech อินพุตการฝึกอบรมรวมถึงการจัดตำแหน่งครูสำหรับเฟรม MEL และโทเค็นข้อความ โดยเฉพาะอย่างยิ่งมันเกี่ยวข้องกับการใช้ MFA เพื่อสร้าง duration ของเฟรม MEL สำหรับโทเค็นข้อความแต่ละรายการก่อนการฝึกอบรม
ในขณะที่อยู่ใน wavthruvec duration ที่สร้างขึ้นโดยใช้ MAS จาก RAD-TTS และถูกป้อนเข้าสู่ Lenghegulator (Duration-Predictor)
ตามการค้นหาการจัดตำแหน่งแบบ monotonic และการใช้งาน RAD-TTS เมื่อคุณฝึกอบรมโมเดลไฟล์แนวทางการจัดตำแหน่งจะถูกสร้างขึ้นภายใต้ './data/align_prior' ไดเรกทอรีด้วยรูปแบบชื่อไฟล์ของ {n_token}_{n_feat}_prior.pth
aishell3
prepay_data.py:
ตัวอย่างเช่น prepay_data.py ใช้ลำโพงเพียงไม่กี่ตัวและไฟล์ WAV สองสามไฟล์
wavthruvec contrains 2 ส่วนประกอบ: text2vec (encoder) และ vec2wav (ตัวถอดรหัส) และพวกเขาฝึกอบรมอย่างอิสระ
ดังนั้นฉันจึงวางไว้ในสอง DIR แยกกันและใช้การกำหนดค่าการฝึกอบรมที่แตกต่างกันสำหรับแต่ละคน
เครื่องบันทึกเทนซอร์บอร์ดจะถูกเก็บไว้ในไดเรกทอรี run/{log_seed}/tb_logs สมมติว่า log_seed=1 คุณสามารถใช้คำสั่งนี้เพื่อให้บริการ tensorboard บน localhost ของคุณ
tensorboard --logdir run/1/tb_logs
จุดตรวจสอบโมเดลจะถูกบันทึกไว้ในไดเรกทอรี run/{log_seed}/model_new
สมมติว่าคุณบันทึกจุดตรวจทุกครั้งที่ทำซ้ำ 10,000 และตอนนี้คุณมีจุดตรวจสอบ checkpoint_10000.pth.tar _10000.pth.tar หากคุณต้องการรีสตาร์ทการฝึกอบรมที่ step 10000 ให้ใช้คำสั่งนี้
python ./text2vec/train.py --restore_step 10000


